Elasticsearch是一款優秀的開源企業級搜尋引擎,其查詢接口主要為Search接口,提供了豐富的各類查詢、排序、統計聚合等功能。本文将要介紹的是另一個查詢接口SearchScroll,同時介紹一下我們在這方面做的一些性能和穩定性等方面的優化工作。
Elasticsearch的SearchScroll接口可用于從索引中檢索大量資料,或者是所有的資料,值得注意的是Elasticsearch的SearchScroll請求不是為了使用者進行實時請求,而是為了更快導出大量資料。同時該接口提供穩定的查詢結果,不會因為使用者一直在更新資料導緻查詢結果集合重複或缺失。典型場景如索引重建、将符合某一個條件的所有的資料全部導出來然後交給計算平台進行分析處理。SearchScroll支援多slice進行請求,在用戶端以多并發的方式進行查詢,導出速度可以更快。
為什麼需要SearchScroll
Search接口的功能已經足夠豐富,那麼為什麼還需要SearchScroll?原因就是Search接口的速度不夠快和結果不夠穩定。
from+size
Search接口進行翻頁的方式主要有兩種,一是size+from的翻頁方式,這種翻頁方式存在很大的性能瓶頸,時間複雜度O(n),空間複雜度O(n)。其每次查詢都需要從第1頁翻到第n頁,但是隻有第n頁的資料需要傳回給使用者。那麼之前n-1頁都是做的無用功。如果翻的更深,那麼消耗的系統資源更是翻倍增長,很容易出現OOM,系統各項名額出現異常。舉個例子,假設每個文檔在協調節點進行merge的ScoreDoc需要16位元組,那麼翻到一億條時候,需要1.6G的記憶體,如果多來幾個并發,普通使用者的計算機根本扛不住這麼大的記憶體開銷。是以,很多産品在功能上直接禁止使用者深度翻頁來避免這種技術難題。
SearchAfter
Search接口另一種翻頁方式是SearchAfter,時間複雜度O(n),空間複雜度O(1)。SearchAfter是一種動态指針的技術,每次查詢都會攜帶上一次的排序值,這樣下次取結果隻需要從上次的位點繼續掃資料,前提條件也是該字段是數值類型且設定了docValue。舉個例子,假設"val_1"是數值類型的字段,然後使用Search接口查詢時候添加Sort("val_1"),那麼response中可以拿到最後一條資料的"val_1"的值,,也就是response中sort字段的值,然後下次查詢将該值放在query中的searchAfter參數中,下次查詢就可以在上一次結果之後繼續查詢,如此反複,最後可以翻頁很深,記憶體消耗相比size+from的方式降低了數倍。該方式效果類似于我們直接在bool查詢中主動加一個rangeFilter,可以達到類似的效果。表面看這種方案能将查詢速度降到O(1)的複雜度,實際上其内部還是會掃sort字段的docValue,翻頁越深,則掃docValve越多,是以複雜度和翻頁深度成正比,越往後查詢越慢,但是相比size+from的方式,至少可以完成深度翻頁的任務,不至于OOM,速度勉強可以接受。SearchAfter的翻頁方式在性能上有了質的提升,但是其限制了使用者隻能一頁一頁往後翻,無法跳頁,是以很多産品在功能設計時候是不允許跳頁的,隻能一頁一頁往後翻,也是有一定的技術原因的。
SearchScroll
Search接口在使用SearchAfter後,相比size+from的翻頁方式,翻頁性能有質的提升,但是和SearchScroll相比,性能遜色很多,使用者需要擷取的資料越多,翻的越深,則差别越大。
在查詢性能上,SearchScroll的翻頁方式,時間複雜度O(1),空間複雜度O(1)。SearchScroll能夠以恒定的速度翻頁擷取完所有資料,而采用SearchAfter的方式擷取資料會随翻頁深度增大而吞吐能力大幅下降。在我們的單機單shard2億資料測試中,采用SearchScroll方式能夠以每次50ms延時穩定擷取完2億資料,而SearchAfter深度翻頁到千萬級條資料後查詢延時就到了秒級别,查詢速度線性下降。
在吞吐能力上,SearchScroll請求天然支援多并發方式查詢,是以SearchScroll特别适合批量快速拉取大量資料,然後交給spark等計算平台進行後續資料分析處理。在Elasticsearch中把每個并發稱之為一個Slice(分片),Elasticsearch内部對使用者的請求進行分片,分片越多則速度越快,拉取資料的速度翻倍提高。當然之前的普通的Search查詢方式也可以并發通路,但是需要使用者将Search請求的query進行拆分,比如原來是擷取1年的資料,那麼可以将query拆分為12個,一個月一個請求,展現在查詢語句裡就是将月份條件添加到query語句中的filter中來保證僅傳回某一個月的資料。Search查詢通過拆分query有時候可以達到類似的并發效果,來加速Search查詢,但是有些query語句是難以拆分的,使用成本較高,是以直接利用SearchScroll讓Elasticsearch幫助我們進行并發拆分是一個不錯的選擇。
在結果穩定性上,SearchScroll由于會“打snapshot”,context會保留目前的segments,後續寫入的資料都是感覺不到的,是以不會造成查到的結果中存在重複資料或者缺失資料。在批量導資料等要求結果穩定的場景下,SearchScroll特别适用。從另一個角度講,對需要穩定結果的使用者來說是件好事,但是會導緻該部分segments暫時無法被merge,也會占用一些作業系統的檔案句柄,是以需要留意系統的這些方面的名額,確定Elasticsearch系統穩定運作。
總之,SearchScroll的查詢速度很快,吞吐能力很高,結果很穩定。
原理剖析
本節主要簡單介紹SearchScroll的流程和SearchScroll的并發原理。
流程解讀
使用SearchScroll功能,使用者的請求主要分為兩個階段,我們将第一階段稱之為Search階段,第二階段稱之為Scroll階段。如下圖所示。
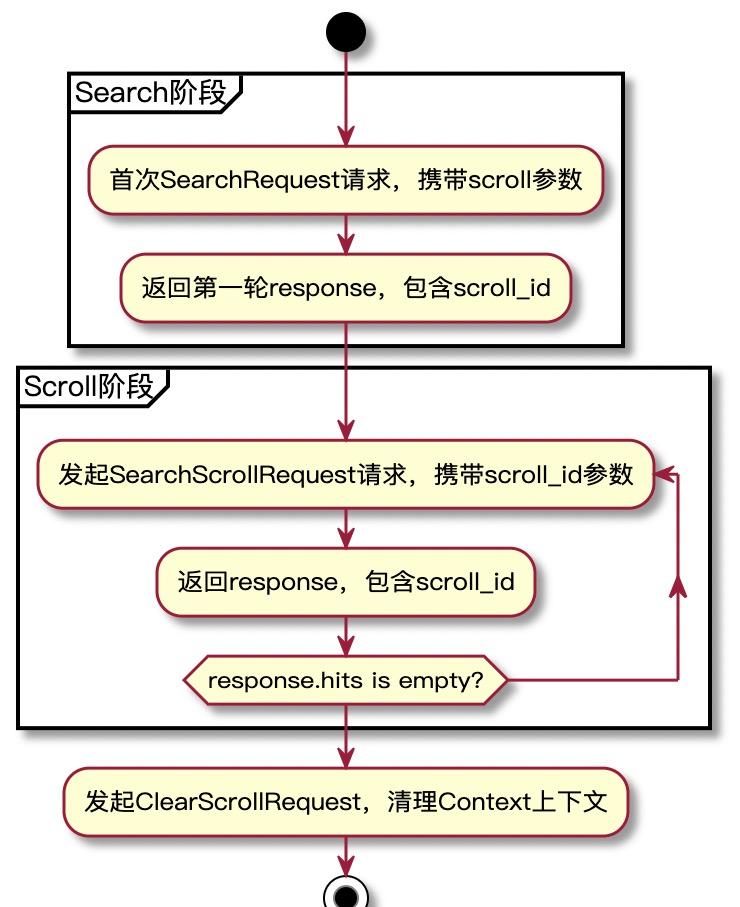
其中第一階段和傳統的Search請求流程幾乎一緻,在Search流程的基礎上進行了一些額外的特殊處理,比如Slice并發處理、Context上下文保留、Response中傳回scroll_id、記錄本次的遊标位址友善下一次scroll請求繼續擷取資料等等。
第二階段Scroll請求則大大簡化,Search中的許多流程都不要再次進行,僅需要執行query、fetch、response三個階段。而完整的search請求包含rewrite、can_match、dfs、query、fetch、dfs_query、expand、response等複雜的流程,是以其在es的代碼實作中也沒有嚴格遵循上述的流程流轉的架構,也沒有SearchPhaseContext等context實作。
Search階段
第一個階段是Search的流程,其中在
Elasticsearch核心解析 - 查詢篇有詳細的介紹。這裡按照查詢流程,僅介紹一些不同的地方。
CreateContext
建立SearchContex後,如果是scroll請求,則在searchContext中設定ScrollContext。ScrollContext中主要包含context的有效時間、上一次通路了哪個文檔lastEmittedDoc(即遊标位置)等資訊。具體如下:
private Map<String, Object> context = null;
public long totalHits = -1;
public float maxScore;
public ScoreDoc lastEmittedDoc;
public Scroll scroll; queryPhase.preProcess中會處理sliceFilter,判斷該slice請求到達哪個shard。這裡是進行slice并發請求核心處理邏輯,簡單來說根據slice的id和shard_id是否比對來判斷是否在本shard上進行請求。然後将query進行重寫,将使用者原有的query放入到boolQuery的must中,slice建構出的filter放入boolQuery的filter中。
SearchScroll通過SearchContext保留上下文。每個context都有一個id,它是單機原子自增的,後續如果還需要使用則可以根據id拿到該context。context會自動清理,預設5分鐘的keepAlive,新來的請求會重新整理keepAlive,或者通過clearScroll來主動清除該context。
LoadOrExecuteQueryPhase
SearchScroll請求結果永遠不會被cache,判斷條件很簡單,如果請求中攜帶了scroll參數,這一步會直接跳過。
QueryPhase.execute
該步驟為search查詢的核心邏輯,search請求攜帶scroll和不攜帶scroll在這裡幾乎是一模一樣的,具體參考上述連結的文章介紹。
FetchSearchPhase
fetch階段,需要将query階段傳回的doc_id進行fetch其doc内容。如果是scroll類型的search請求,則需要buildScrollId,scrollid中儲存了一個數組,每個元素包含2個值:
- nodeid,下次請求知道上一次請求在哪個shard上進行的。
- RequestId(ContextId),找到上一次請求對應的searchContext,友善進行下一次請求。
fetch結束的時候,需要将本次請求發給使用者的最後一個元素的排序字段的值的大小保留下來,這個值是哪個字段取決于search請求中的sort設定了什麼值。elasticsearch推薦使用_doc進行排序,這樣性能最好。當擷取到最後一個文檔後,需要更新到searchContext中的ScrollContext的lastEmittedDoc值,這樣下次請求就知道從哪裡開始進行搜尋了。
小結
總結一下Search和Scroll的核心差別,主要是在query階段需要處理并發的scroll請求(slice),fetch階段需要得到本次傳回給使用者的最後一個文檔lastEmittedDoc,然後告知data節點的context,這樣下次請求就可以繼續從上一個記錄點進行搜尋。

Scroll階段
該階段是在elasticsearch中是通過調用SearchScrollRequest發起請求,其參數主要有兩個:
- scroll_id,友善在data節點上找到對應的context,繼續上一次的請求。
- scroll失效時間,即重新整理context的aliveTime,aliveTime過後該context失效。這個參數一般使用不多,使用預設值即可。
該階段從api層面來看已經差別很大,一個是SearchRequest,另一個是SearchScrollRequest。search的流程上面主要是分析了一些不同的地方,接下來講一下scroll的流程,隻有query、fetch、response三個phase,其中response僅僅是拼裝和傳回資料,這裡略過。
query
- 在協調節點上,将scroll_id進行parse,得到本次請求的目标shard和對應shard上的searchContext的id,将這兩個參數通過InternalScrollSearchRequest請求轉發到data節點上。
- 在data節點上,從記憶體中擷取到對應的searchContext,即擷取到了使用者原來的query和上次遊标資訊lastEmittedDoc。然後再執行QueryPhase.execute時,會将query進行改寫,如下代碼所示。改寫後将lastEmittedDoc放入boolQuery的filter中,這就是為什麼scroll請求可以知道下次請求的資料應該從哪裡開始。并且這個MinDocQuery的性能是比傳統的rangeQuery要快很多的,它僅僅比對 >=after.doc + 1的文檔,可以直接跳過很多無效的掃描。
final ScoreDoc after = scrollContext.lastEmittedDoc;
if (after != null) {
BooleanQuery bq = new BooleanQuery.Builder()
.add(query, BooleanClause.Occur.MUST)
.add(new MinDocQuery(after.doc + 1), BooleanClause.Occur.FILTER)
.build();
query = bq;
} fetch
- 在協調節點上,将各個shard傳回的資料進行排序,然後将使用者想要的size個資料進行fetch,這些資料同樣需要得到lastEmittedDoc, 與Search階段一緻,都是通過ShardFetchRequest告知data節點上searchContext本次的lastEmittedDoc,并更新在context中供下次查詢使用。
- 在data節點上,如果傳入的request.lastEmittedDoc不為空,則更新searchContext中的lastEmittedDoc。
SearchScroll的并發原理介紹
SearchScroll天然支援基于shard的并發查詢,而Search接口想要支援并發查詢,需要将query進行拆分,雖然也能進行并發查詢,但是其背後浪費的叢集資源相對較多。
首先從API使用方式上介紹SearchScroll的并發,我們用一個簡單的例子做說明。Slice參數是SearchScroll控制并發切分的參數,id、max是其最主要的兩個參數,id取值為[0,max),max取值沒有特别的限制,一般不超過1024,但是推薦max取值為小于等于索引shard的個數。id、max兩個參數決定了後續在data節點如何檢索資料。
GET /bar/_search?scroll=1m
{
"slice": {
"id": 0,
"max": 128
},
"query": {
"match" : {
"title" : "foo"
}
}
} SearchScroll并發擷取資料隻需要我們多個線程調用Elasticsearch的接口即可,然後請求到達data節點後,開始處理slice,如果該slice不應該查詢本shard,則直接傳回一個MatchNoDocsQuery這樣的filter,然後本shard上的查詢會迅速得到執行。如果并發數等于shard數,就相當于一個并發真實的查詢了一個shard。而用Search接口拆query後進行并發查詢,每個并發還是會通路所有的shard在所有資料上進行查詢,浪費叢集的資源。
SearchScroll如何判定一個slice是否應該查詢一個節點上的shard,隻需要進行簡單的hash值判斷即可。有4個參數id、max、shardID、numShards(索引shard個數)決定了是否會進行MatchNoDocsQuery,具體規則如下:
- 當max>=numShards,如果 id%numShards!=shardID,則傳回MatchNoDocsQuery
- 當max<numShards,如果 id!=shardId%max,則傳回MatchNoDocsQuery
為什麼推薦SearchScroll的max取值小于等于索引shard個數?簡單說明就是并發數大于索引shard數後,需要将一個shard切分為多份來給多個slice使用,而切分單個shard是需要消耗一些資源的,會造成首次查詢較慢,且有記憶體溢出風險。
首先看一下slice是如何切分shard的,規則如下:
- numShards=1
-
- 直接TermsSliceQuery切分,單個shard的slice_id就是TermsSliceQuery請求的slice_id,單個shard内如何切分見下方介紹。
- max<=numShards
-
- 一個slice對應numShards/max個完整shard
- max>numShards
-
- 靠前的單個shard被分為(max/numShards + 1)份,後面的被分為(max/numShards)份
- 例如:
-
-
- 5shard 8個slice,則
-
-
-
-
- shard0->slice0、5
- shard1->slice1、6
- shard2->slice2、7
- shard3->slice3
- shard4->slice4
-
-
單shard内slice是根據slice.field參數來切分的,推薦使用_id或者_uid來進行切分,_uid也是該參數的預設值。其它支援DocValue的number類型的field都可以進行切分。
- 根據_uid字段進行切分,則使用TermsSliceQuery進行切分
-
- 這個filter是O(N*M),其中N是term的枚舉數量,M是每個term出現的平均次數。
- 每個segment會生成一個DocIdSet
-
-
- 首輪Search請求由于score沒有cache,需要真正的去周遊拿docid,是以執行較慢。
- 針對每個segment,周遊term dictionary,計算每個term的hashCode, Math.floorMod(hashCode, slice_max) == slice_id 來決定是否放入到DocIdSet。
-
-
- 計算hash值的函數:StringHelper.murmurhash3_x86_32
- 其它DocValue數值類型字段進行切分,則使用DocValuesSliceQuery進行切分
-
- DocValuesSliceQuery和TermsSliceQuery類似,隻是沒有使用_uid作為切分,它使用了指定field的排序好的SortedNumericDocValues
- 它構造出的DocIdSet是一個全量的DocIdSet(DocIdSetIterator.all),但是在scorer時候有一個兩階段的過程,TwoPhaseIterator中如果match才會取出,不然就指向下一個。match中定義的邏輯和上面_uid切分是一緻的,都是根據hash值是否和slice_id對應。如果Math.floorMod(hashCode, slice_max) == slice_id就拿出來,不然就跳過。
- 計算hash值:BitMixer.mix
-
-
- 該計算hash值的速度估計會比string的要快,因為實作要比murmurhash3_x86_32簡單很多。
-
-
- 注意點:
-
-
- 該字段不能更新,隻能設定一次
- 該字段的分布要均勻,不然每個slice擷取到的docId不均勻。
-
單shard内切分slice的兩種方式總結:
- TermsSliceQuery耗記憶體,可能會造成jvm記憶體緊張;DocValuesSliceQuery不占用記憶體,但是依賴讀DocValue,是以速度沒有TermsSliceQuery快。
- TermsSliceQuery真實的周遊了_uid的值,而DocValuesSliceQuery周遊了doc_id序号,根據這個doc_id去取DocValue。
性能、穩定性優化改進
目前Elasticsearch在SearchScroll接口上有很多地方存在性能或者穩定性問題,我們對他們進行了一些優化和改進,讓該接口性能更好和使用更佳。本節主要介紹的是我們在SearchScroll接口上做的一些優化的工作。
queryAndFetch
這個優化是Elasticsearch目前就有的,但是還有改進的空間。
當索引隻有一個shard的時候,Elasticsearch能夠啟用該優化,這時候SearchScroll查詢能夠啟用queryAndFetch查詢政策,這樣在協調節點上隻需要一步queryAndFetch操作就可以從data節點上拿到資料,而預設的查詢政策queryThenFetch需要經曆一個兩階段操作。如圖所示,queryAndFetch這種查詢方式可以節省一次網絡開銷,查詢時間縮短。
當使用者的shard數不等于1時候,Elasticsearch沒有任何優化。但是,當使用者的SearchScroll的max和shard數一緻的時候,也是可以開啟queryAndFetch優化的,因為一個并發僅僅在一個shard上真正的執行。我們将這些case也進行了優化,在多并發時候也能進行queryAndFetch優化,節省CPU、網絡、記憶體等資源消耗,提高整體吞吐率。
查詢剪枝
SearchScroll多并發場景下,請求剛到協調節點上,會查詢出每個shard在哪些節點上,然後将請求轉發到這些節點上。當查詢請求到達data節點上,根據slice參數重寫query時候,會判斷該shard應不應該被目前slice進行查詢。主要判斷邏輯本文上述章節已經介紹。如果該slice不應該查詢本shard,則直接傳回一個MatchNoDocsQuery這樣的filter,相當于該請求在data節點上浪費了一次查詢。雖然加了MatchNoDocsQuery的原請求執行速度很快,但是會占用線程池浪費一些cpu時間,而且會浪費線程池的隊列空間。
假如使用者有512個shard,且使用者用512個并發進行通路。需要注意的是,每個并發請求都會轉發到所有的shard上,是以在叢集的data節點上瞬間會有512*512=26萬個任務需要執行,其中僅有512個任務是真正需要執行的,其它的請求都是在浪費叢集資源。預設情況下單個節點查詢線程池隊列是1000,一般叢集也沒有那麼多data節點,難支撐26萬個請求。
針對該問題,我們将slice的MatchNoDocsQuery的filter過濾提前到協調節點,不需要再轉發這些無用的請求。在協調節點上會計算哪些shard需要真正執行查詢任務,是以我們将MatchNoDocsQuery的filter邏輯前置,達到查詢剪枝的目的。
除此之外,在并發數和shard數不相等時候,一個并發請求可能會發送到n個shard上。假如使用者需要傳回m條資料,會向n個shard各請求m條資料,然後在協調節點需要将n*m條資料進行排序,選出前m條進行fetch然後再傳回給使用者,這樣相當于浪費了(n-1)*m條資料的計算和io資源。是以可以僅從一個shard上擷取資料,按順序将所有shard上的資料拉取結束,在挨個拉取的過程中,還要保持之前在各個shard建立的searchContext,避免SearchContext失效。
查詢剪枝後,并發通路方式下,scroll_id也将變得特别短。之前使用者拿到的scroll_id特别長,跟使用者的shard數成正比,當shard數較多時候,scroll_id也特别長,在傳輸過程和scroll_id編碼解析過程中都會浪費一些系統資源。
shard選擇政策
一個索引通常會有很多副本,當請求到達協調節點後,請求應該轉發到哪個副本呢?
預設情況下,采用的是随機政策,将所有副本打亂随機拿出一個副本即可。預設的随機政策能夠将請求均勻地打散在每一個shard上。假如我們的data節點處理能力不一緻,或者由于一些原因造成某些機器負載較高,那麼采用随機政策可能不太适用。Elasticsearch提供了一個自适應的選擇政策,其能夠根據目前的每個節點的狀态來選擇最佳的副本。參考因素如下源碼列出的,包括節點的client數、隊列長度、響應時間、服務時間等。是以,通過"cluster.routing.use_adaptive_replica_selection"參數将副本自适應選擇政策打開,能夠發揮每一台機器的能力,請求延時能夠有效降低,每台機器的負載能夠更加均勻。
ComputedNodeStats(int clientNum, NodeStatistics nodeStats) {
this(nodeStats.nodeId, clientNum,(int) nodeStats.queueSize.getAverage(), nodeStats.responseTime.getAverage(), nodeStats.serviceTime);
} 針對SearchScroll請求,如果是頻率較高的拉取不同索引的少量資料,那麼副本自适應選擇政策可以滿足需求。但是針對一些大索引拉取資料的case則不再适用。假如某一個索引有512個shard,且需要拉取的資料較多,那麼叢集資源可能僅夠該索引大量拉取,不會再有其他請求過來。當512個并發請求一下子進來協調節點,這時候協調節點會拉取每個data節點的狀态來決定把請求發往哪個副本。但是512個并發是一起過來的,是以拿到的nodeStats可能是一緻的,會造請求發往相同的data節點,造成一些data節點負載較高,而其他data節點負載較低。SearchScroll的首輪請求會決定了後續請求在哪個data節點執行,是以後續所有請求和首輪一樣,造成各個data節點負載不一緻。
針對這種情況,如果索引shard較多,且使用者是SearchScroll請求,則需要不再使用副本自适應選擇政策。
請求支援重試
自Elasticsearch支援SearchScroll以來,scroll_id都是不變的,所有的遊标位點資訊都是維護在data節點的searchContext中。scroll_id僅僅編碼了node_id和context_id。協調節點根據node_id将請求轉發到對應的data節點,在data節點上根據context_id拿到searchContext,最後拿到所有相關的具體資訊。
目前scroll_id是不支援重試的,強行進行重試可能會造成資料丢失,推薦遇到失敗全部重新拉取。比如使用者有100條資料需要拉取,每次拉10條。當拉取20~30條時候,Elasticsearch已經拿到資料,代表着data節點的遊标位點資訊已經更新,但是使用者網絡發生問題,沒有取到這10條資料。這時候使用者忽略網絡異常而繼續請求的話,會拿到30~40的10條資料,而20~30的10條資料再也拿不到,造成讀取資料丢失。針對這一問題,我們将searchContext中維護的last_emitted_doc編碼到scroll_id中,這樣在部分場景失敗下就可以進行重試。
之前scroll_id的編碼是為query_type + array_size + array[context_id + node_id],我們優化後的scroll_id為增加了version、index_name、last_emitted_doc等資訊:
- version字段是為了以後做版本相容使用,目前的scroll_id并沒有版本的概念,是以版本相容難做。
- index_name是索引的名字。雖然該字段對查詢沒有任何用處,但是在stats監控中需要用到。之前我們僅能統計SearchScroll的整個叢集或者Node級别的監控,現在拿到index_name後,可以做到索引級别更細粒度的監控,比如拿到某一個索引Scroll階段的query、merge、sort、fetch等各項監控資訊。
- last_emitted_doc是新增的字段,在Elasticsearch中是ScoreDoc.java,主要編碼的是doc和score兩個字段。如果ScoreDoc是FieldDoc子類型,則還會編碼fields。
scroll_id中編碼last_emitted_doc後,使用者的每次請求我們都能拿到目前的遊标位點資訊。在協調節點中,通過InternalScrollSearchRequest将該Request從協調節點發送到data節點,最終data節點不再從searchContext中拿last_emitted_doc,而是從InternalScrollSearchRequest拿到last_emitted_doc。
除此之外,目前Elasticsearch的SearchContext是不支援并發通路的,且沒有給出任何提示,如果并發通路會造成拿到的資料錯亂。是以,我們将SearchContext加了狀态,如果通路一個正在被通路的SearchContext,則抛出沖突異常。
最後
本文介紹了SearchScroll的基本概念和一些内部原理,最後介紹了我們在SearchScroll方面做的一些性能優化工作,希望大家對SearchScroll有更深的了解。
如果您是Java老司機,或者對Lucene、Elasticsearch、Solr等相關引擎運用熟練、了解到位,或者想從事搜尋引擎相關的一些工作,可以釘釘或郵箱聯系尋劍<[email protected]>,團隊技術氛圍濃厚、簡單淳樸,歡迎大家私聊交流。