0 概念區分
-
普通索引和唯一索引
普通索引可以重複,唯一索引和主鍵一樣不能重複。
唯一索引可以作為資料的一個合法驗證手段,例如學生表的身份證号碼字段,我們人為規定該字段不得重複,那麼就使用唯一索引。(一般設定學号字段為主鍵)
-
主鍵和唯一索引
主鍵保證資料庫裡面的每一行都是唯一的,比如身份證,學号等,在表中要求唯一,不重複。唯一索引的作用跟主鍵的作用一樣。
不同的是,在一張表裡面隻能有一個主鍵,主鍵不能為空,唯一索引可以有多個,唯一索引可以有一條記錄為空,即保證跟别人不一樣就行。
比如學生表,在學校裡面一般用學号做主鍵,身份證則弄成唯一索引;而到了教育局,他們就把身份證号弄成主鍵,學号換成了唯一索引。
選誰做表的主鍵,要看實際應用,主鍵不能為空。
1 示例
一個市民系統,每個人都有個唯一身份證号;
業務代碼已保證不會寫入兩個重複的身份證号;
如果市民系統需要按照身份證号查姓名,就會執行類似SQL:
select name from CUser where id_card = 'xxxxxxxyyyyyyzzzzz'; 相信你一定會在
id_card
字段上建索引。
由于身份證号字段比較大,不建推薦把身份證号做主鍵。
是以現在有兩個選擇
- 給id_card字段建立唯一索引
- 建立一個普通索引
如果業務代碼已保證不會寫入重複的身份證号,那這兩個選擇邏輯上都正确。
但從性能角度考慮,唯一索引還是普通索引呢?
假設字段 k 上的值都不重複。
- InnoDB的索引組織結構 接下來從這兩種索引對查詢語句和更新語句的性能影響來進行分析。
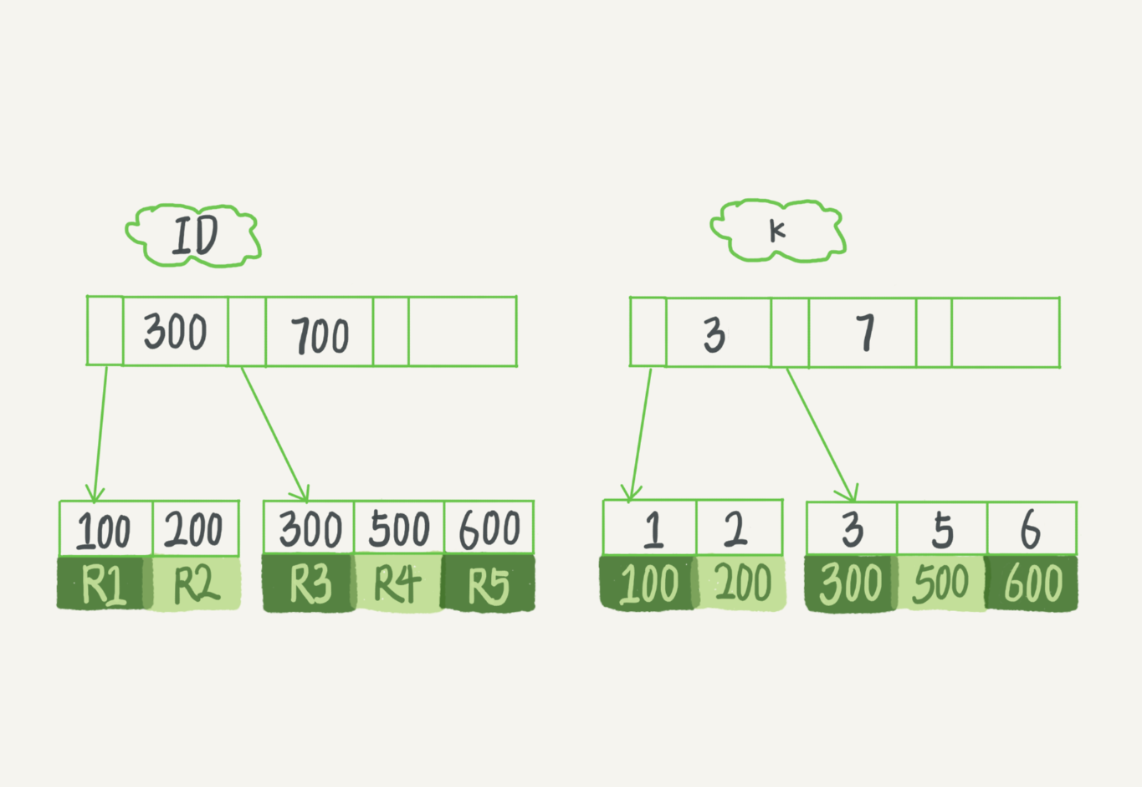
你分得清MySQL普通索引和唯一索引了嗎?0 概念區分1 示例2 查詢過程3 更新過程4 實踐中的索引選擇5 change buffer 和 redo log6 總結
2 查詢過程
查詢語句
select id from T where k=5 該語句在索引樹查找的過程:
先通過B+樹從樹根開始,按層搜尋到葉節點,即圖中右下角的資料頁,然後可認為資料頁内部是通過二分法定位記錄。
- 對普通索引,查找到滿足條件的第一個記錄(5,500)後,需查找下個記錄,直到碰到第一個不滿足k=5條件的記錄
- 對唯一索引,由于索引定義了唯一性,查找到第一個滿足條件的記錄後,就會停止檢索。
該不同點帶來的性能差距會有多少呢?
微乎其微!
InnoDB資料是按資料頁為機關讀寫。即當需讀一條記錄時,并非将該記錄本身從磁盤讀出,而是以頁為機關,将其整體讀入記憶體。
InnoDB中,每個資料頁的大小預設是16KB。
因引擎按頁讀寫,是以,當找到k=5記錄時,它所在資料頁就都在記憶體了。
對普通索引,要多做的那一次“查找和判斷下一條記錄”的操作,就隻需要一次指針尋找和一次計算。
如果k=5記錄剛好是該資料頁的最後一個記錄,那麼要取下個記錄,必須讀取下個資料頁,操作會稍微複雜。
對于整型字段,一個資料頁可存近千個key,是以這種情況機率很低。是以,計算平均性能差異時,仍可認為該操作成本對現在的CPU可忽略不計。
3 更新過程
3.1 change buffer
需更新一個資料頁時
- 若資料頁在記憶體,直接更新
-
若該資料頁不在記憶體,在不影響資料一緻性前提下,InooDB會将這些更新操作緩存在change buffer,無需從磁盤讀入該資料頁。
在下次查詢需要通路該資料頁時,将資料頁讀入記憶體,然後執行change buffer中與這個頁有關的操作。通過該方式就能保證這個資料邏輯的正确性。
雖然叫change buffer,實際上是可持久化的資料。
即change buffer在記憶體中有拷貝,也會被寫進磁盤。
3.2 merge
3.2.1 概念
将change buffer中的操作應用到原資料頁,得到最新結果的過程。
3.2.2 觸發時機
通路該資料頁會觸發merge
系統有背景線程會定期merge
在資料庫正常關閉(shutdown)的過程中,也會執行merge。
若能将更新操作先記錄在change buffer,減少讀盤,語句執行速度會明顯提升。
且資料讀入記憶體需要占用buffer pool,是以該方式還能避免占用記憶體,提高記憶體使用率。
3.3 何時用change buffer
對于唯一索引,所有更新操作要先判斷該操作是否違反唯一性限制。
比如,要插入(4,400)記錄,要先判斷表中是否已存k=4記錄,而這必須要将資料頁讀入記憶體才能判斷。
如果都已經讀入到記憶體,那直接更新記憶體會更快,就沒必要使用change buffer。
是以,唯一索引的更新就不能使用change buffer,實際上也隻有普通索引可使用。
change buffer用的是buffer pool裡的記憶體,是以不能無限增大。
change buffer的大小,可通過參數innodb_change_buffer_max_size動态設定。
參數設定為50時,表示change buffer的大小最多隻能占用buffer pool的50%。
了解了change buffer機制,看看要在這張表中插入一個新記錄(4,400),InnoDB處理流程。
分情況讨論該記錄要更新的目标頁是否在記憶體中:
在記憶體
-
唯一索引
找到3和5之間位置,判斷到沒有沖突,插入值,語句執行結束。
-
普通索引
找到3和5之間位置,插入值,語句執行結束。
普通索引和唯一索引對更新語句性能影響的差别,隻是一個判斷,隻會耗費微小CPU時間。
不在記憶體
- 需要将資料頁讀入記憶體,判斷到沒有沖突,插入值,語句執行結束
- 将更新記錄在change buffer,語句執行結束
将資料從磁盤讀入記憶體涉及随機IO通路,是資料庫裡面成本最高操作之一。
change buffer因減少随機磁盤通路,是以對更新性能提升明顯。
問題案例:某業務的庫記憶體命中率突然從99%降低到了75%,整個系統處于阻塞狀态,更新語句全部堵住。
探究其原因,發現該業務有大量插入資料操作,而DBA在前天把其中的某個普通索引改成了唯一索引。
change buffer的使用場景
普通索引的所有場景,使用change buffer都可加速嗎?
因為merge才是真正進行資料更新時刻;
change buffer主要目的是将記錄的變更動作緩存下來;
是以在一個資料頁做merge前,change buffer記錄變更越多(即該資料頁上要更新的次數越多),收益越大。
對寫多讀少業務,頁面在寫完後馬上被通路到的機率較小,change buffer使用效果最好。該類業務模型常見為賬單、日志類的系統。
反之,假設一業務的更新模式是寫後馬上查詢,那麼即使滿足條件,将更新先記錄在change buffer,但之後由于馬上要通路該資料頁,立即觸發merge。
這樣随機通路IO的次數不會減少,反而增加change buffer維護代價。
是以,對于這種業務模式,change buffer起副作用。
4 實踐中的索引選擇
普通索引和唯一索引如何抉擇。
這兩類索引在查詢性能上沒差别,主要考慮對更新性能影響。
是以,推薦盡量選擇普通索引。
如果所有更新後面,都緊跟對該記錄的查詢,那麼該關閉change buffer。
而在其他情況下,change buffer都能提升更新性能。
普通索引和change buffer的配合使用,對于資料量大的表的更新優化還是很明顯的。
在使用機械硬碟時,change buffer機制的收效非常顯著。
是以,當你有一個類似“曆史資料”的庫,并且出于成本考慮用機械硬碟時,應該關注這些表裡的索引,盡量使用普通索引,把change buffer 開大,確定“曆史資料”表的資料寫速度。
5 change buffer 和 redo log
WAL 提升性能的核心機制,也是盡量減少随機讀寫,這兩個概念易混淆。
是以,這裡我把它們放到了同一個流程裡來說明區分。
在表上
5.1 執行插入
insert into t(id,k) values(id1,k1),(id2,k2); 假設目前k索引樹的狀态,查找到位置後
k1所在資料頁在記憶體(InnoDB buffer pool),k2所在的資料頁不在記憶體中
- 帶change buffer的更新狀态圖。

你分得清MySQL普通索引和唯一索引了嗎?0 概念區分1 示例2 查詢過程3 更新過程4 實踐中的索引選擇5 change buffer 和 redo log6 總結
該更新語句涉及四部分:
- 記憶體
- redo log(ib_log_fileX)
- 資料表空間(t.ibd)
- 系統表空間(ibdata1)
該更新語句做了如下操作(按圖中數字順序):
- Page1在記憶體,直接更新記憶體
- Page2沒有在記憶體中,就在記憶體的change buffer區,記錄下“我要往Page2插一行”的資訊
- 将前兩個動作記入redo log(圖中的3和4)
做完上面,事務完成。執行這條更新語句的成本很低,就寫兩處記憶體,然後寫一處磁盤(兩次操作合在一起寫了一次磁盤),還是順序寫。
圖中兩個虛箭,是背景操作,不影響更新的響應時間。
這之後的讀請求,怎麼處理?
現在執行
select * from t where k in (k1, k2) 若讀語句緊随在更新語句後,記憶體中的資料都還在,那麼此時這倆讀操作就與系統表空間(ibdata1)和 redo log(ib_log_fileX)無關。是以在圖中就沒畫這倆。
- 兩個讀請求的流程圖(帶change buffer的讀過程)
你分得清MySQL普通索引和唯一索引了嗎?0 概念區分1 示例2 查詢過程3 更新過程4 實踐中的索引選擇5 change buffer 和 redo log6 總結
從圖中可見:
讀Page1時,直接從記憶體傳回。
WAL之後如果讀資料,是不是一定要讀盤,是不是一定要從redo log裡面把資料更新以後才可以傳回?其實不用。
看上圖狀态,雖然磁盤上還是之前資料,但這裡直接從記憶體傳回結果,結果正确。
要讀Page2時,需把Page2從磁盤讀入記憶體,然後應用change buffer裡面的記錄檔,生成一個正确版本并傳回結果。
可見直到需讀Page2時,該資料頁才被讀入記憶體。
是以,要簡單對比這倆機制對更新性能影響
- redo log 主要節省随機寫磁盤的IO消耗(轉成順序寫)
- change buffer主要節省随機讀磁盤的IO消耗
6 總結
由于唯一索引用不了change buffer的優化機制,是以如果業務可以接受,從性能角度,推薦優先考慮非唯一索引。
6.1 關于到底是否使用唯一索引
主要糾結在“業務可能無法確定”。本文前提是“業務代碼已經保證不會寫入重複資料”下,讨論性能問題。
- 如果業務不能保證,或者業務就是要求資料庫來做限制,那麼沒得選,必須建立唯一索引。這種情況下,本文意義在于,如果碰上大量插入資料慢、記憶體命中率低時,多提供一個排查思路。
- 然後,在一些“歸檔庫”的場景,可考慮使用唯一索引的。比如,線上資料隻需保留半年,然後曆史資料儲存在歸檔庫。此時,歸檔資料已是確定沒有唯一鍵沖突。要提高歸檔效率,可考慮把表的唯一索引改普通索引。
6.2 如果某次寫入使用change buffer,之後主機異常重新開機,是否會丢失change buffer的資料?
不會丢失。
雖然是隻更新記憶體,但在事務送出時,我們把change buffer的操作也記錄到redo log,是以崩潰恢複時,change buffer也能找回。
6.3 merge的過程是否會把資料直接寫回磁盤?
merge執行流程
- 從磁盤讀入資料頁到記憶體(老版本資料頁)
- 從change buffer找出該資料頁的change buffer 記錄(可能有多個),依次應用,得到新版資料頁
-
寫redo log
該redo log包含資料的變更和change buffer的變更
至此merge過程結束。
這時,資料頁和記憶體中change buffer對應磁盤位置都尚未修改,是髒頁,之後各自刷回自己實體資料,就是另外一過程。