什麼是Kylin
Apache Kylin是一個開源的、分布式的分析型資料倉庫,提供Hadoop/Spark 之上的 SQL 查詢接口及多元分析(OLAP)能力以支援超大規模資料,最初由 eBay 開發并貢獻至開源社群。它能在亞秒内查詢巨大的表。
Kylin的查詢高性能主要依賴于Cube理論,如圖所示:
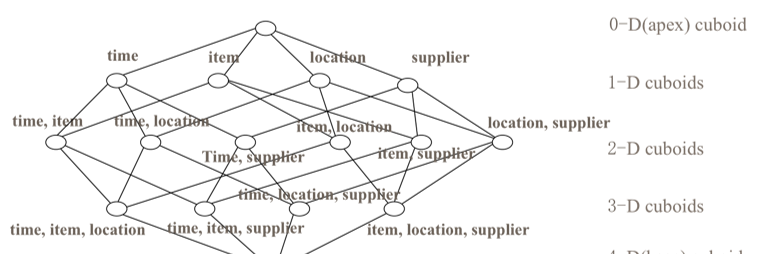
它将表字段劃分為次元和量度,通過預先計算,在次元上進行量度聚合并儲存聚合結果,而根據次元進行聚合查詢時,則可以命中已儲存的聚合結果,大大減少資料掃描量和實時計算量。
Kylin的系統架構如圖所示:

它依賴大資料基礎設施HBase、Spark、Hadoop等實作分布式的存儲和計算,并基于這些基礎設施,設計了建構引擎和查詢引擎來分别實作資料的建構和查詢。在查詢引擎部分,Kylin使用了Calcite來實作SQL的解析、優化和執行。
什麼是Calcite
Calcite是一個用于優化異構資料源的查詢處理的基礎架構,提供了标準的 SQL 語言、多種查詢優化和連接配接各種資料源的能力。從功能上看,它支援SQL 解析、SQL 校驗、SQL 查詢優化、SQL 生成、資料連接配接查詢等,但不包括資料處理和存儲。Calcite的架構如圖所示:
資料處理和存儲系統提供中繼資料和規則至Calcite,Calcite提供JDBC Server面向用戶端查詢,并對SQL查詢請求進行處理,在Calcite中,一個SQL的解析和執行大概經過以下5個步驟:
- 将SQL解析成抽象文法樹;
- 對抽象文法樹進行校驗;
- 将抽象文法樹解析成關系代數表達式;
- 對關系代數表達式進行優化,在保持語義不變的前提下,轉化為較優的表達式;
- 将優化後關系代數表達式轉化為實體執行計劃并計劃,傳回最終的結果。
目前Calcite在大資料和資料存儲領域有着廣泛的使用,如表所示:
Kylin、Phoenix、Hive、Flink等均使用Calcite實作JDBC驅動、SQL解析、SQL校驗、SQL 查詢優化等。
Kylin查詢源碼分析
資料模型
在源碼分析時,我們使用Kylin的官方資料模型示例,如圖所示:
該雪花模型包含以下5張表:
- KYLIN_SALES,銷售事實表;
- KYLIN_ACCOUNT,使用者次元表;
- KYLIN_CAL_DT,日期次元表;
- KYLIN_CATEGORY_GROUPING,類别次元表
- KYLIN_COUNTR,國家次元表。
示例SQL如下所示:
select s.lstg_site_id,sum(s.price) as price_sum from kylin_sales as s inner join kylin_account as a on s.buyer_id = a.account_id where a.account_country='US' group by s.lstg_site_id order by price_sum desc limit 10 用于查詢各站點來自美國消費者的銷售額。
入口
Kylin支援多種查詢入口,包括WEB控制台、REST API、JDBC驅動、ODBC驅動等。這裡介紹了一下JDBC驅動的實作。
當用戶端使用JDBC接口通路時,加載的JDBC驅動是org.apache.kylin.jdbc.Driver,這裡,Kylin使用了JDBC驅動架構Avatica,Driver即繼承自org.apache.calcite.avatica.UnregisteredDriver,覆寫了getFactoryClassName方法,如下所示:
@Override
protected String getFactoryClassName(JdbcVersion jdbcVersion) {
switch (jdbcVersion) {
case JDBC_30:
throw new UnsupportedOperationException();
case JDBC_40:
return KylinJdbcFactory.Version40.class.getName();
case JDBC_41:
default:
return KylinJdbcFactory.Version41.class.getName();
}
}
該段代碼說明僅支援JDBC 4.0即以上版本協定,并傳回了相應的工廠類。工廠類KylinJdbcFactory實作了AvaticaFactory接口,用于建立JDBC相關接口執行個體,部分代碼如下:
@Override
public AvaticaStatement newStatement(AvaticaConnection connection, StatementHandle h, int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException {
return new KylinStatement((KylinConnection) connection, h, resultSetType, resultSetConcurrency, resultSetHoldability);
}
@Override
public AvaticaResultSet newResultSet(AvaticaStatement statement, QueryState state, Signature signature, TimeZone timeZone, Frame firstFrame) throws SQLException {
AvaticaResultSetMetaData resultSetMetaData = new AvaticaResultSetMetaData(statement, null, signature);
return new KylinResultSet(statement, state, signature, resultSetMetaData, timeZone, firstFrame);
}
該段代碼說明JDBC相關接口的實作是在Avatica架構實作基礎的進一步繼承和擴充,例如,ResultSet接口實作是KylinResultSet,其是AvaticaResultSet的子類,KylinResultSet主要覆寫了AvaticaResultSet的execute方法,該方法的核心代碼如下所示:
KylinConnection connection = (KylinConnection) statement.connection;
IRemoteClient client = connection.getRemoteClient();
Map<String, String> queryToggles = new HashMap<>();
int maxRows = statement.getMaxRows();
queryToggles.put("ATTR_STATEMENT_MAX_ROWS", String.valueOf(maxRows));
addServerProps(queryToggles, connection);
QueryResult result;
try {
result = client.executeQuery(sql, paramValues, queryToggles);
} catch (IOException e) {
throw new SQLException(e);
}
該段代碼說明擷取IRemoteClient執行個體,執行executeQuery方法傳回查詢結果,而從IRemoteClient的實作KylinClient中的代碼可以看到,其實質上是調用kylin-server子產品的REST API “kylin/api/query”來實作查詢。
那具體看一下該API的服務端,略過Controller層、緩存命中、注釋删除等環節,查詢代碼在org.apache.kylin.rest.service.QueryService的executeRequest方法中,如下所示:
Pair<List<List<String>>, List<SelectedColumnMeta>> r = null;
try {
stat = conn.createStatement();
processStatementAttr(stat, sqlRequest);
resultSet = stat.executeQuery(correctedSql);
r = createResponseFromResultSet(resultSet);
} catch (SQLException sqlException) {
r = pushDownQuery(sqlRequest, correctedSql, conn, sqlException);
if (r == null)
throw sqlException;
isPushDown = true;
} finally {
close(resultSet, stat, null); //conn is passed in, not my duty to close
}
該段代碼仍是基于JDBC接口,而connection通過org.apache.kylin.query.QueryConnection的getConnection方法建立,代碼如下所示:
if (!isRegister) {
try {
Class<?> aClass = Thread.currentThread().getContextClassLoader()
.loadClass("org.apache.calcite.jdbc.Driver");
Driver o = (Driver) aClass.getDeclaredConstructor().newInstance();
DriverManager.registerDriver(o);
} catch (ClassNotFoundException | InstantiationException | IllegalAccessException | NoSuchMethodException | InvocationTargetException e) {
e.printStackTrace();
}
isRegister = true;
}
File olapTmp = OLAPSchemaFactory.createTempOLAPJson(project, KylinConfig.getInstanceFromEnv());
Properties info = new Properties();
info.putAll(KylinConfig.getInstanceFromEnv().getCalciteExtrasProperties());
// Import calcite props from jdbc client(override the kylin.properties)
info.putAll(BackdoorToggles.getJdbcDriverClientCalciteProps());
info.put("model", olapTmp.getAbsolutePath());
info.put("typeSystem", "org.apache.kylin.query.calcite.KylinRelDataTypeSystem");
return DriverManager.getConnection("jdbc:calcite:", info); 其加載的JDBC驅動是org.apache.calcite.jdbc.Driver,說明後續基于Calcite進行SQL解析、校驗、優化和執行。這裡,通過Calcite标準的model字段傳入中繼資料描述檔案
中繼資料
中繼資料描述檔案示例如下所示:
{
"version": "1.0",
"defaultSchema": "DEFAULT",
"schemas": [
{
"type": "custom",
"name": "DEFAULT",
"factory": "org.apache.kylin.query.schema.OLAPSchemaFactory",
"operand": {
"project": "learn_kylin"
},
"functions": [
{
name: 'PERCENTILE',
className: 'org.apache.kylin.measure.percentile.PercentileAggFunc'
},
{
name: 'CONCAT',
className: 'org.apache.kylin.query.udf.ConcatUDF'
},
{
name: 'MASSIN',
className: 'org.apache.kylin.query.udf.MassInUDF'
},
{
name: 'INTERSECT_COUNT',
className: 'org.apache.kylin.measure.bitmap.BitmapIntersectDistinctCountAggFunc'
},
{
name: 'VERSION',
className: 'org.apache.kylin.query.udf.VersionUDF'
},
{
name: 'PERCENTILE_APPROX',
className: 'org.apache.kylin.measure.percentile.PercentileAggFunc'
}
]
}
]
} OLAPSchemaFactory類實作了Calcite的SchemaFactory接口,建立OLAPSchema類執行個體,而OLAPSchema類則通過讀取HBase上存儲的中繼資料資訊生成OLAPTable類的Map集合,代碼如下所示:
public Map<String, Table> getTableMap() {
return buildTableMap();
} OLAPTable類實作了Calcite的QueryableTable和TranslatableTable接口(這兩個接口均繼承自Table接口),用于描述表,其中比較重要的幾個方法如下所示:
public RelDataType getRowType(RelDataTypeFactory typeFactory) {
if (this.rowType == null) {
// always build exposedColumns and rowType together
this.sourceColumns = getSourceColumns();
this.rowType = deriveRowType(typeFactory);
}
return this.rowType;
} 該方法在Table接口中定義,用于擷取表字段資訊,Kylin除了按Calcite定義傳回RelDataType類型的字段資訊,也會按自身定義儲存ColumnDesc類型的字段集合,其中包含次元資訊,用于後續執行實體查詢時判斷從哪些Cuboid掃描資料。
public Statistic getStatistic() {
List<ImmutableBitSet> keys = new ArrayList<ImmutableBitSet>();
return Statistics.of(100, keys);
} 該方法在Table接口中定義,用于擷取表的行數等統計資訊,在CBO方式的優化中計算成本,但是Kylin存儲引擎統計的是各Cuboid的統計資訊,是以這裡統一傳回固定值。
@Override
public RelNode toRel(ToRelContext context, RelOptTable relOptTable) {
int fieldCount = relOptTable.getRowType().getFieldCount();
int[] fields = identityList(fieldCount);
return new OLAPTableScan(context.getCluster(), relOptTable, this, fields);
}
該方法在TranslatableTable接口中定義,說明在優化過程中,掃描表資料的關系表達式節點會轉化為OLAPTableScan類執行個體,關于OLAPTableScan類會在後續優化、執行過程中再介紹。
同時,OLAPTable還有一些方法用于傳回Enumerable接口執行個體(也就是Kylin實作的OLAPQuery類),如下所示:
public Enumerable<Object[]> executeOLAPQuery(DataContext optiqContext, int ctxSeq) {
return new OLAPQuery(optiqContext, EnumeratorTypeEnum.OLAP, ctxSeq);
}
public Enumerable<Object[]> executeLookupTableQuery(DataContext optiqContext, int ctxSeq) {
return new OLAPQuery(optiqContext, EnumeratorTypeEnum.LOOKUP_TABLE, ctxSeq);
}
public Enumerable<Object[]> executeColumnDictionaryQuery(DataContext optiqContext, int ctxSeq) {
return new OLAPQuery(optiqContext, EnumeratorTypeEnum.COL_DICT, ctxSeq);
}
public Enumerable<Object[]> executeHiveQuery(DataContext optiqContext, int ctxSeq) {
return new OLAPQuery(optiqContext, EnumeratorTypeEnum.HIVE, ctxSeq);
}
這些方法在執行實體查詢時,Calcite會通過反射進行調用,擷取OLAPQuery類,實際的資料掃描委托給OLAPQuery完成,關于OLAPQuery類會在後續優化、執行過程中再介紹。
解析
查詢請求傳遞到服務端,并在服務端執行stat.executeQuery(correctedSql)後,會進入具體的查詢流程,首先進行SQL的解析。Calcite的文法解析是基于JavaCC實作的。JavaCC是一個文法解析器生成架構, 其根據預先定義的規則生成相應的解析器代碼。Calcite的文法解析規則是calcite-core中的codegen/templates/Parser.jj,根據其生成的解析器類是org.apache.calcite.sql.parser.impl. SqlParserImpl。調用該類執行個體解析SQL生成抽象文法樹(即SqlNode)的代碼在CalcitePrepareImpl中,如下所示:
SqlParser parser = createParser(query.sql, parserConfig);
SqlNode sqlNode;
try {
sqlNode = parser.parseStmt();
statementType = getStatementType(sqlNode.getKind());
} catch (SqlParseException e) {
throw new RuntimeException(
"parse failed: " + e.getMessage(), e);
}
示例SQL經過解析得到的抽象文法樹如圖所示:
樹中的每個節點是SqlNode子類執行個體。
校驗
抽象文法樹通過SqlValidatorImpl類的validate方法進行校驗,校驗的細節此處暫不展開,僅列出校驗的主要步驟包括:
- 對抽象文法樹根節點進行标準化重寫,在保持語義的前提下,将SqlOrderBy、SqlDelete、SqlUpdate、SqlMerge等類型節點重寫為SqlSelect類型節點;
- 調用各節點的validate方法進行校驗。
代碼如下:
SqlNode outermostNode = performUnconditionalRewrites(topNode, false);
cursorSet.add(outermostNode);
top = outermostNode;
TRACER.trace("After unconditional rewrite: {}", outermostNode);
if (outermostNode.isA(SqlKind.TOP_LEVEL)) {
registerQuery(scope, null, outermostNode, outermostNode, null, false);
}
outermostNode.validate(this, scope);
是以,上一步的抽象文法樹經過校驗會轉化為下圖:
關系代數表達式
校驗後的抽象文法樹通過SqlToRelConverter 類的convertQueryRecursive方法進一步解析成關系代數表達式。這個方法代碼如下所示:
final SqlKind kind = query.getKind();
switch (kind) {
case SELECT:
return RelRoot.of(convertSelect((SqlSelect) query, top), kind);
case INSERT:
return RelRoot.of(convertInsert((SqlInsert) query), kind);
case DELETE:
return RelRoot.of(convertDelete((SqlDelete) query), kind);
case UPDATE:
return RelRoot.of(convertUpdate((SqlUpdate) query), kind);
case MERGE:
return RelRoot.of(convertMerge((SqlMerge) query), kind);
case UNION:
case INTERSECT:
case EXCEPT:
return RelRoot.of(convertSetOp((SqlCall) query), kind);
case WITH:
return convertWith((SqlWith) query, top);
case VALUES:
return RelRoot.of(convertValues((SqlCall) query, targetRowType), kind);
default:
throw new AssertionError("not a query: " + query);
從這個方法的命名就可以看出,方法内部是在遞歸調用,從抽象文法樹根節點開始,根據其類型,分别調用對應的convertSelect、convertInsert、convertDelete、convertUpdate、convertMerge等方法,轉化為RelNode類型執行個體(RelNode是關系代數表達式節點接口),而在這些方法内部,會對傳入節點的子節點,根據其類型,再遞歸調用這些方法,進而将抽象文法樹所有節點均轉化為RelNode類型執行個體,并建立互相之間的關系。通過convertSelect方法具體轉化SqlSelect類型節點的代碼部分如下所示:
convertFrom(
bb,
select.getFrom());
convertWhere(
bb,
select.getWhere());
final List<SqlNode> orderExprList = new ArrayList<>();
final List<RelFieldCollation> collationList = new ArrayList<>();
gatherOrderExprs(
bb,
select,
select.getOrderList(),
orderExprList,
collationList);
final RelCollation collation =
cluster.traitSet().canonize(RelCollations.of(collationList));
if (validator.isAggregate(select)) {
convertAgg(
bb,
select,
orderExprList);
} else {
convertSelectList(
bb,
select,
orderExprList);
}
if (select.isDistinct()) {
distinctify(bb, true);
}
convertOrder(
select, bb, collation, orderExprList, select.getOffset(),
select.getFetch());
其依次對from、where、groupBy、orderBy等子節點進行轉化。最終,上一步的抽象文法樹進行轉化後得到下列關系代數表達式:
LogicalSort(sort0=[$1], dir0=[DESC], fetch=[10])
LogicalAggregate(group=[{0}], PRICE_SUM=[SUM($1)])
LogicalProject(LSTG_SITE_ID=[$4], PRICE=[$5])
LogicalFilter(condition=[=($16, 'US')])
LogicalJoin(condition=[=($7, $13)], joinType=[inner])
OLAPTableScan(table=[[DEFAULT, KYLIN_SALES]], ctx=[], fields=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]])
OLAPTableScan(table=[[DEFAULT, KYLIN_ACCOUNT]], ctx=[], fields=[[0, 1, 2, 3, 4, 5]])
其根節點排序(LogicalSort),葉子節點是兩張表的資料掃描(OLAPTableScan)
優化
在轉化得到關系代數表達式後,會進一步對其進行優化,在保持語義不變的前提下,對表達式進行轉化和調整以找到最優的表達式。優化器可以分為2類:
- 基于規則的優化器(Rule Based Optimizer,簡稱RBO):根據優化規則将一個關系表達式轉化為另外一個關系表達式,同時原有表達式被放棄,經過一系列轉化後生成最終表達式;
- 基于成本的優化器(Cost Based Optimizer,簡稱CBO):根據優化規則對關系表達式進行轉換,同時原有表達式也會保留,經過一系列轉化後生成多個表達式,之後計算每個表達式的成本,從中挑選成本最小的表達式作為最終表達式。
Calcite有兩個優化器實作:
- HepPlanner: RBO的實作,按照規則進行比對,直到達到次數限制或者周遊後無比對規則;
- VolcanoPlanner: CBO 的實作,一直疊代各規則,直到找到成本最小的表達式。
Calcite的優化在Prepare類的optimize方法中,部分代碼如下所示:
final RelOptPlanner planner = root.rel.getCluster().getPlanner();
…
final Program program = getProgram();
final RelNode rootRel4 = program.run(
planner, root.rel, desiredTraits, materializationList, latticeList);
首先生成一個VolcanoPlanner類型的優化器執行個體,然後通過getProgram擷取Program接口執行個體,并通過該接口的run方法執行優化。Program接口有多個實作,getProgram方法最終是通過Programs類的standard方法擷取的SequenceProgram類執行個體,代碼如下所示:
return sequence(subQuery(metadataProvider),
new DecorrelateProgram(),
new TrimFieldsProgram(),
program1,
// Second planner pass to do physical "tweaks". This the first time
// that EnumerableCalcRel is introduced.
calc(metadataProvider));
也就是說,優化可劃分為串行執行的5步,包括将子查詢轉化為Join操作、删除無用字段等,其中第三步是使用已建立的VolcanoPlanner類型優化器執行個體進行優化。關系代數表達式的葉子節點是OLAPTableScan類型,該類覆寫了RelNode的register方法,其中添加了Kylin擴充的多個規則,如下表所示:
| 類 | 說明 |
|---|---|
| OLAPToEnumerableConverterRule | 将RelNode類型節點轉化為OLAPToEnumerableConverter類型節點 |
| OLAPFilterRule | 将LogicalFilter類型節點轉化為OLAPFilterRel類型節點 |
| OLAPProjectRule | 将LogicalProject類型節點轉化為OLAPProjectRel類型節點 |
| OLAPAggregateRule | 将LogicalAggregate類型節點轉化為OLAPAggregateRel類型節點 |
| OLAPJoinRule | 将LogicalJoin 類型節點轉化為 OLAPJoinRel或OLAPFilterRel類型節點 |
| OLAPLimitRule | 将Sort類型節點轉化為OLAPLimitRel類型節點 |
| OLAPSortRule | 将Sort類型節點轉化為OLAPSortRel類型節點 |
| OLAPUnionRule | 将Union類型節點轉化為OLAPUnionRel類型節點 |
| OLAPWindowRule | 将Window類型節點轉化為OLAPWindowRel類型節點 |
| OLAPValuesRule | 将LogicalValues類型節點轉化為OLAPValuesRel類型節點 |
同時,還删除了多個Calcite原生的規則,部分如下所示:
// since join is the entry point, we can't push filter past join
planner.removeRule(FilterJoinRule.FILTER_ON_JOIN);
planner.removeRule(FilterJoinRule.JOIN);
// since we don't have statistic of table, the optimization of join is too cost
planner.removeRule(JoinCommuteRule.INSTANCE);
planner.removeRule(JoinPushThroughJoinRule.LEFT);
planner.removeRule(JoinPushThroughJoinRule.RIGHT);
// keep tree structure like filter -> aggregation -> project -> join/table scan, implementOLAP() rely on this tree pattern
planner.removeRule(AggregateJoinTransposeRule.INSTANCE);
planner.removeRule(AggregateProjectMergeRule.INSTANCE);
planner.removeRule(FilterProjectTransposeRule.INSTANCE);
planner.removeRule(SortJoinTransposeRule.INSTANCE);
planner.removeRule(JoinPushExpressionsRule.INSTANCE);
planner.removeRule(SortUnionTransposeRule.INSTANCE);
planner.removeRule(JoinUnionTransposeRule.LEFT_UNION);
planner.removeRule(JoinUnionTransposeRule.RIGHT_UNION);
planner.removeRule(AggregateUnionTransposeRule.INSTANCE);
planner.removeRule(DateRangeRules.FILTER_INSTANCE);
planner.removeRule(SemiJoinRule.JOIN);
planner.removeRule(SemiJoinRule.PROJECT);
以此來保持表達式中的一些模式,便于後續實體執行計劃的相關操作。經過上述優化後,關系表達式轉化為如下結果:
OLAPLimitRel(ctx=[], fetch=[10])
OLAPSortRel(sort0=[$1], dir0=[DESC], ctx=[])
OLAPAggregateRel(group=[{0}], PRICE_SUM=[SUM($1)], ctx=[])
OLAPProjectRel(LSTG_SITE_ID=[$4], PRICE=[$5], ctx=[])
OLAPFilterRel(condition=[=($16, 'US')], ctx=[])
OLAPJoinRel(condition=[=($7, $13)], joinType=[inner], ctx=[])
OLAPTableScan(table=[[DEFAULT, KYLIN_SALES]], ctx=[], fields=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]])
OLAPTableScan(table=[[DEFAULT, KYLIN_ACCOUNT]], ctx=[], fields=[[0, 1, 2, 3, 4, 5]])
執行
最後是将關系代數表達式轉化為實際實體執行計劃,掃描HBase中的資料并傳回結果,這裡正在梳理過程中,可先參考官方推薦的文檔
https://www.jianshu.com/p/21df8303d2ae了解其原理,其中,會執行OLAPTableScan類的implement方法,如下所示:
@Override
public Result implement(EnumerableRelImplementor implementor, Prefer pref) {
context.setReturnTupleInfo(rowType, columnRowType);
String execFunction = genExecFunc();
PhysType physType = PhysTypeImpl.of(implementor.getTypeFactory(), getRowType(), JavaRowFormat.ARRAY);
MethodCallExpression exprCall = Expressions.call(table.getExpression(OLAPTable.class), execFunction,
implementor.getRootExpression(), Expressions.constant(context.id));
return implementor.result(physType, Blocks.toBlock(exprCall));
}
public String genExecFunc() {
// if the table to scan is not the fact table of cube, then it's a lookup table
if (context.realization.getModel().isLookupTable(tableName)) {
return "executeLookupTableQuery";
} else if (DictionaryEnumerator.ifDictionaryEnumeratorEligible(context)) {
return "executeColumnDictionaryQuery";
} else {
return "executeOLAPQuery";
}
}
通過反射調用OLAPQuery類的相關方法,這些方法在之前介紹中繼資料時曾提及,其均傳回Enumerable接口執行個體。以OLAPEnumerator為例,其在疊代擷取結果時,實質上是調用queryStorage方法,代碼如下所示:
private ITupleIterator queryStorage() {
logger.debug("query storage...");
// bind dynamic variables
olapContext.bindVariable(optiqContext);
// If olapContext is cached, then inherit it.
if (!olapContext.isBorrowedContext) {
olapContext.resetSQLDigest();
}
SQLDigest sqlDigest = olapContext.getSQLDigest();
// query storage engine
IStorageQuery storageEngine = StorageFactory.createQuery(olapContext.realization);
ITupleIterator iterator = storageEngine.search(olapContext.storageContext, sqlDigest,
olapContext.returnTupleInfo);
if (logger.isDebugEnabled()) {
logger.debug("return TupleIterator...");
}
return iterator;
}
擷取相應的IStorageQuery接口執行個體,通過協處理器掃描HBase資料。