背景
熟悉或了解分布性系統的開發者都字段一緻性算法的重要性,Paxos一緻性算法從90年提出到現在已經有二十幾年了,而Paxos流程太過于繁雜實作起來也比較複雜,可能也是以為過于複雜現在我聽說過比較出名使用到Paxos的也就隻是Chubby、libpaxos,搜了下發現Keyspace、BerkeleyDB資料庫中也使用了該算法作為資料的一緻性同步,雖然現在很廣泛使用的Zookeeper也是基于Paxos算法來實作,但是Zookeeper使用的ZAB(Zookeeper Atomic Broadcast)協定對Paxos進行了很多的改進與優化,算法複雜我想會是制約他發展的一個重要原因;說了這麼多隻是為了要引出本篇文章的主角Raft一緻性算法,沒錯Raft就是在這個背景下誕生的,文章開頭也說到了Paxos最大的問題就是複雜,Raft一緻性算法就是比Paxos簡單又能實作Paxos所解決的問題的一緻性算法。
Raft是斯坦福的Diego Ongaro、John Ousterhout兩個人以易懂(Understandability)為目标設計的一緻性算法,在2013年釋出了論文:《In Search of an Understandable Consensus Algorithm》從2013年釋出到現在不過隻有兩年,到現在已經有了十多種語言的Raft算法實作架構,較為出名的有etcd,Google的Kubernetes也是用了etcd作為他的服務發現架構;由此可見易懂性是多麼的重要。
Raft概述
與Paxos不同Raft強調的是易懂(Understandability),Raft和Paxos一樣隻要保證n/2+1節點正常就能夠提供服務;衆所周知但問題較為複雜時可以把問題分解為幾個小問題來處理,Raft也使用了分而治之的思想把算法流程分為三個子問題:選舉(Leader election)、日志複制(Log replication)、安全性(Safety)三個子問題;這裡先簡單介紹下Raft的流程;
Raft開始時在叢集中選舉出Leader負責日志複制的管理,Leader接受來自用戶端的事務請求(日志),并将它們複制給叢集的其他節點,然後負責通知叢集中其他節點送出日志,Leader負責保證其他節點與他的日志同步,當Leader宕掉後叢集其他節點會發起選舉選出新的Leader;
Raft詳解
1、角色
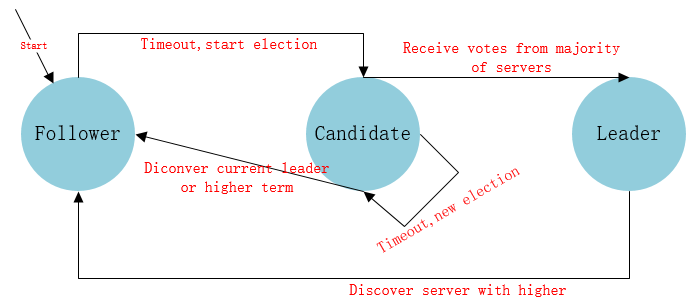
Raft把叢集中的節點分為三種狀态:Leader、Follower、Candidate,理所當然每種狀态負責的任務也是不一樣的,Raft運作時提供服務的時候隻存在Leader與Follower兩種狀态;
Leader(上司者):負責日志的同步管理,處理來自用戶端的請求,與Follower保持這heartBeat的聯系;
Follower(追随者):剛啟動時所有節點為Follower狀态,響應Leader的日志同步請求,響應Candidate的請求,把請求到Follower的事務轉發給Leader;
Candidate(候選者):負責選舉投票,Raft剛啟動時由一個節點從Follower轉為Candidate發起選舉,選舉出Leader後從Candidate轉為Leader狀态;
2、Term
在Raft中使用了一個可以了解為周期(第幾屆、任期)的概念,用Term作為一個周期,每個Term都是一個連續遞增的編号,每一輪選舉都是一個Term周期,在一個Term中隻能産生一個Leader;先簡單描述下Term的變化流程:
Raft開始時所有Follower的Term為1,其中一個Follower邏輯時鐘到期後轉換為Candidate,Term加1這是Term為2(任期),然後開始選舉,這時候有幾種情況會使Term發生改變:
1:如果目前Term為2的任期内沒有選舉出Leader或出現異常,則Term遞增,開始新一任期選舉
2:當這輪Term為2的周期選舉出Leader後,過後Leader宕掉了,然後其他Follower轉為Candidate,Term遞增,開始新一任期選舉
3:當Leader或Candidate發現自己的Term比别的Follower小時Leader或Candidate将轉為Follower,Term遞增
4:當Follower的Term比别的Term小時Follower也将更新Term保持與其他Follower一緻;
可以說每次Term的遞增都将發生新一輪的選舉,Raft保證一個Term隻有一個Leader,在Raft正常運轉中所有的節點的Term都是一緻的,如果節點不發生故障一個Term(任期)會一直保持下去,當某節點收到的請求中Term比當
前Term小時則拒絕該請求;
3、選舉(Election)
Raft的選舉由定時器來觸發,每個節點的選舉定時器時間都是不一樣的,開始時狀态都為Follower某個節點定時器觸發選舉後Term遞增,狀态由Follower轉為Candidate,向其他節點發起RequestVote RPC請求,這時候有三種可能的情況發生:
1:該RequestVote請求接收到n/2+1(過半數)個節點的投票,從Candidate轉為Leader,向其他節點發送heartBeat以保持Leader的正常運轉
2:在此期間如果收到其他節點發送過來的AppendEntries RPC請求,如該節點的Term大則目前節點轉為Follower,否則保持Candidate拒絕該請求
3:Election timeout發生則Term遞增,重新發起選舉
在一個Term期間每個節點隻能投票一次,是以當有多個Candidate存在時就會出現每個Candidate發起的選舉都存在接收到的投票數都不過半的問題,這時每個Candidate都将Term遞增、重新開機定時器并重新發起選舉,由于每個節點中定時器的時間都是随機的,是以就不會多次存在有多個Candidate同時發起投票的問題。有這麼幾種情況會發起選舉,1:Raft初次啟動,不存在Leader,發起選舉;2:Leader當機或Follower沒有接收到Leader的heartBeat,發生election timeout進而發起選舉;

4、日志複制(Log Replication)
日志複制(Log Replication)主要作用是用于保證節點的一緻性,這階段所做的操作也是為了保證一緻性與高可用性;當Leader選舉出來後便開始負責用戶端的請求,所有事務(更新操作)請求都必須先經過Leader處理,這些事務請求或說成指令也就是這裡說的日志,我們都知道要保證節點的一緻性就要保證每個節點都按順序執行相同的操作序列,日志複制(Log Replication)就是為了保證執行相同的操作序列所做的工作;在Raft中當接收到用戶端的日志(事務請求)後先把該日志追加到本地的Log中,然後通過heartbeat把該Entry同步給其他Follower,Follower接收到日志後記錄日志然後向Leader發送ACK,當Leader收到大多數(n/2+1)Follower的ACK資訊後将該日志設定為已送出并追加到本地磁盤中,通知用戶端并在下個heartbeat中Leader将通知所有的Follower将該日志存儲在自己的本地磁盤中。
5、安全性(Safety)
安全性是用于保證每個節點都執行相同序列的安全機制,如當某個Follower在目前Leader commit Log時變得不可用了,稍後可能該Follower又會倍選舉為Leader,這時新Leader可能會用新的Log覆寫先前已committed的Log,這就是導緻節點執行不同序列;Safety就是用于保證選舉出來的Leader一定包含先前 commited Log的機制;
選舉安全性(Election Safety)
每個Term隻能選舉出一個Leader
Leader完整性(Leader Completeness)
這裡所說的完整性是指Leader日志的完整性,當Log在Term1被Commit後,那麼以後Term2、Term3...等的Leader必須包含該Log;Raft在選舉階段就使用Term的判斷用于保證完整性:當請求投票的該Candidate的Term較大或Term相同Index更大則投票,否則拒絕該請求;
參考資料:
http://ramcloud.stanford.edu/raft.pdf
文章首發位址:Solinx
http://www.solinx.co/archives/415