在人口流量紅利不再,獲客成本越來越高的時代,精益創業、MVP 的概念已經深入人心,精細化營運也是大勢所趨,而這些背後本質上都依賴資料化營運,那如何根據現有業務,快速從 0 開始打造一個契合業務的資料産品呢?本文将以某二手交易平台業務為基礎,講述整個資料平台從 0 到 1 的演進與實踐,希望對大家能有所啟發。
1、背景
在某二手交易平台開始大資料平台建設之前,整個資料從需求提出到研發流程再到資料報表、資料産品,也是經曆過一段非常混沌的時期,而且效率和品質往往很難得到保障,主要表現為以下幾個方面:
(1)可用性差
比如經常出現計算延遲、異常,資料名額也常常資料對不上,很多相似的名額不清楚具體差異在哪,即使同一個名額也可能不同的同學開發的而對不上。另外資料波動無感覺,比如日志格式出錯,結果第二天才發現有問題。
(2)維護成本高
成百上千的日志子產品,不知從何維護,出了問題也不知道從哪裡可以追溯到源頭和負責人。
(3)業務快速疊代,精細化、資料化營運需求和研發資源之間的沖突
2、目标與方案
(1)目标
資料可管理、可維護、可擴充、高可用
及時、準确、直覺的呈現業務資料與問題
降低使用門檻,提升使用效率
(2)方案
資料倉庫化
資料平台化
3、資料倉庫建設
結構化
階層化
主題化
模型化:使用者模型/事件模型
ETL
ETL 是整個資料倉庫的核心,正如業界流傳的一句話:Garbage In, Garbage Out. 髒活累活都是在這一層完成,以便為上層業務提供口徑、格式、邏輯統一的資料層,提升資料品質和穩定性,如果這一層沒做好,上層的統計分析與資料挖掘無異于空中樓閣。ETL常見的工作如下:
無效資料
髒資料轉換
資料模型/業務邏輯預處理
高可用:依賴、重試、告警、優先級
4、資料平台化與産品化
從資料體系和平台的層次來劃分可以分為标準的五層結構:采集層、傳輸層、存儲層、計算層、應用層
随着業務的不斷疊代,業務逐漸複雜、資料量也急劇膨脹後,每一層都會遭遇挑戰,比如采集層,如何在高并發的情況下,保證日志能穩定落地到磁盤而不重不丢不延時?是采用開源的 Nginx+Lua 方案還是自研元件造輪子?數防止資料的無限膨脹,據倉庫中繼資料怎麼管理?如何減小維護成本?計算層的任務排程如何解決依賴關系,又如何做到分布式排程高可用?以上這些問題,早期我們大部分都采用開源的解決方案,但在後續的易用性、擴充性和維護性都遭遇了不少問題,總體成本一點都不低,是以最後我們大部分還是采用自研的解決方案(這塊話題比較廣,細節比較多,本文暫時不展開詳述,有機會後續将會單獨展開分享)。又如計算層的 OLAP 引擎我們該如何選取?比如 MR 适合大規模資料集的批處理,Hive 适合靈活的探索式即席查詢,Kylin 适合多元實時統計分析,Storm 适合實時流式計算,Spark 适合記憶體疊代型計算,到底該選誰?可以看到的是沒有所謂的銀彈和通用解決方案,需要結合自身的業務場景和需求來技術選型和架構。
整體技術棧與架構如下:

資料産品化方面主要是對資料需求與報表的抽象,最終形成通用的自動化報表工具,比如:
業務需求抽象分類:求和、求平均、TOP K、最大最小、去重、過濾
多樣性的解決方案:離線、實時、單維、多元
基于這些抽象,我們比較容易實作基于報表、統計項和日志、日志行之間的邏輯映射關系,形成通用的自助化配置報表,極大釋放開發資源。
另外産品、營運、BOSS可能随時需要關注業務營運狀态、利用資料做各種分析和業務決策,我們需要考慮到平台的移動化與跨終端,這裡我們在技術選型時就考慮到了這一點,利用比較流行的響應式布局架構可以近乎 0 代價實作跨平台,而不用單獨去開發 iOS 或 android 用戶端。
5、資料名額體系化、分析架構與方法論
資料名額和次元成千上萬,如何基于業務去展開分析,又如何去量化營運效果,評估業務,其實是需要建立一套科學的分析架構和名額體系的,否則隻會迷失在資料的海洋裡,或者盲人摸象得出錯誤的結論,以某二手交易平台的業務體系為例,咱們可以看下某二手交易平台的資料名額體系:
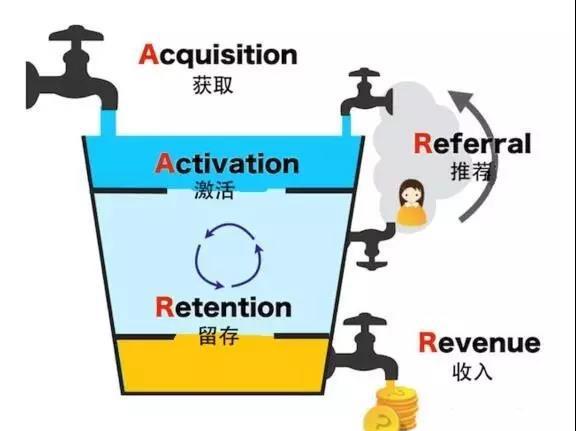
另外基于此我們設計了一些常用的資料模型與分析架構,供業務方快速的分析決策,評估效果,比如留存、漏鬥模型,精益創業裡的 AARRR 分析架構,基于使用者事件模型,我們還實作了自助化的漏鬥、留存分析工具,供業務方自助化的配置任意想關注的路徑漏鬥或行為留存。
6、整個資料平台及其體系化的重難點
漏鬥透傳機制:這個屬于日志埋點問題,如果不解決,一些通用的資料模型如漏鬥分析就無法進行,是以我們設計了一套 Session 級别的透傳機制,確定使用者每個頁面或動作的通路能夠被串聯分析,追溯來源入口,精細化分析改善現有産品和有針對性的營運。
資料治理:資料品質的體系化建設,資料倉庫、實時監控是兩個不錯的解決方案。
業務級别的中繼資料管理:将中繼資料細化到業務層次,降低業務方的使用門檻,提升決策效率。
資料生命周期管理:哪些是熱資料哪些是冷資料,核心和非核心,長期和短期,防止資料的無限膨脹,帶來繁重的存儲、維護成本和計算資源的浪費。
大資料場景下的實時多元分析:比如大資料場景下的實時去重計算,我們會依據不同的場景,選取不同的方案,如bitmap、分布式緩存、基數估計等等,在計算代價和時效性、準确性三方面去做 tradeoff。
7、總結:如何根據現有業務,快速從 0 開始打造一個契合業務的資料産品?
走進業務
抽象業務訴求
換位思考,走在需求的前面
站在巨人的肩膀上
萬變不離其宗的方法論