雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
簡單了解一下可重複讀
可重複讀是指:一個事務執行過程中看到的資料,總是跟這個事務在啟動時看到的資料是一緻的。
我們可以簡單了解為:在可重複讀隔離級别下,事務在啟動的時候就”拍了個快照“。注意,這個快照是基于整個庫的。
這時,你可能就會想,如果一個庫有 100G,那麼我啟動一個事務,MySQL就要拷貝 100G 的資料出來,這個過程得多慢啊。可是,我平時的事務執行起來很快啊。
實際上,我們并不需要拷貝出這 100G 的資料。我們來看下”快照“是怎麼實作的。
拍個快照
InnoDB 裡面每個事務都有一個唯一的事務 ID,叫作 transaction id。它在事務開始的時候向 InnoDB 的事務系統申請的,是按申請順序嚴格遞增的。
每條記錄在更新的時候都會同時記錄一條 undo log,這條 log 就會記錄上目前事務的 transaction id,記為 row trx_id。記錄上的最新值,通過復原操作,都可以得到前一個狀态的值。
如下圖所示,一行記錄被多個事務更新之後,最新值為 k=22。假設事務A在 trx_id=15 這個事務送出後啟動,事務A 要讀取該行時,就通過 undo log,計算出該事務啟動瞬間該行的值為 k=10。
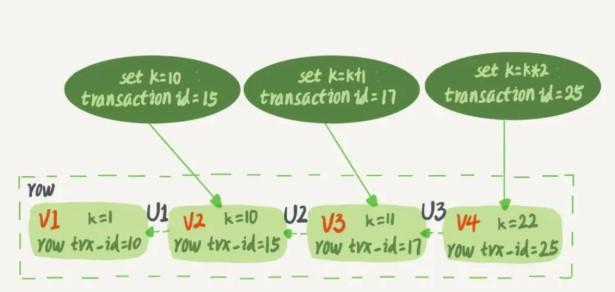
在可重複讀隔離級别下,一個事務在啟動時,InnoDB 會為事務構造一個數組,用來儲存這個事務啟動瞬間,目前正在”活躍“的所有事務ID。”活躍“指的是,啟動了但還沒送出。
數組裡面事務 ID 為最小值記為低水位,目前系統裡面已經建立過的事務 ID 的最大值加 1 記為高水位。
這個視圖數組和高水位,就組成了目前事務的一緻性視圖(read-view)。
這個視圖數組把所有的 row trx_id 分成了幾種不同的情況。

- 如果 trx_id 小于低水位,表示這個版本在事務啟動前已經送出,可見;
- 如果 trx_id 大于高水為,表示這個版本在事務啟動後生成,不可見;
- 如果 trx_id 大于低水位,小于高水位,分為兩種情況:
- 若 trx_id 在數組中,表示這個版本在事務啟動時還未送出,不可見;
- 若 trx_id 不在數組中,表示這個版本在事務啟動時已經送出,可見。
InnoDB 就是利用 undo log 和 trx_id 的配合,實作了事務啟動瞬間”秒級建立快照“的能力。
舉個栗子
初始化語句
下表為事務A, B, C 的執行流程
我們假設事務A, B, C 的 trx_id 分别為 100, 101, 102。事務A開始前活躍的事務 ID 隻有 99,并且 id=1 這一行資料的 trx_id=90。
根據假設,我們得出事務啟動瞬間的視圖數組:事務A:[99, 100],事務B:[99, 100, 101],事務C:[99, 100, 101, 102]。
- 事務C通過更新語句,把 k 更新為 2,此時trx_id=102;
- 事務B通過更新語句,把 k 更新為 3,此時trx_id=101;
- 事務B通過查詢語句,查詢到最新一條記錄為3,trx_id=101,滿足隔離條件,傳回 k=3;
- 事務A通過查詢語句:
1.查詢到最新一條記錄為3,trx_id=101,比高水位大,不可見;
2.通過 undo log,找到上一個曆史版本,trx_id=102,比高水位大,不可見;
3.繼續找上一個曆史版本,trx_id=90,比低水位小,可見。
提出問題:為啥事務B更新的時候能看到事務C的修改?
我們假設事務B在更新的看不到事務C的修改,是什麼個情況?
- 事務B查詢到最新一條記錄為2,trx_id=102,比高水位大,不可見;
- 通過 undo log,找到上一個版本,trx_id=90,比低水位小,可見;
- 傳回記錄 k=1,執行 k=k+1,把 k 更新為2,此時 trx_id=101。
如果是這種情況,事務C可能就蒙了:“啥子情況,我的更新怎麼就丢了”。事務B覆寫了事務C的更新。
是以,InnoDB在更新時運用一條規則:更新資料都是先讀後寫的,而這個讀,隻能讀目前的值,稱為“目前讀“ (current read)。
是以,事務B在更新時要拿到最新的資料,在此基礎上做更新。緊接着,事務B在讀取的時候,查詢到最新的記錄為3, trx_id=101 為目前事務ID,可見。
我們再假設另一種情況:
事務B在更新之後,事務C緊接着更新,事務B復原了,事務C成功送出。
如果按照目前讀的定義,會發生以下事故,假設目前 K=1:
- 事務B把 k 更新為 2;
- 事務C讀取到目前最新值,k=2,更新為3;
- 事務B復原;
- 事務C送出。
這時候,事務C發現自己想要執行的是 +1 操作,結果變成了 ”+2“ 操作。
InnoDB 肯定不允許這種情況的發生,事務B在執行更新語句時,會給該行加上行鎖,直到事務B結束,才會釋放這個鎖。
小結
InnoDB 的行資料有多個版本,每個版本都有 row trx_id。事務根據 undo log 和 trx_id 建構出滿足目前隔離級别的一緻性視圖。可重複讀的核心是一緻性讀,而事務更新資料的時候,隻能使用目前讀,如果目前記錄的行鎖被其他事務占用,就需要進入鎖等待。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/live立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-06-05
本文作者:超超不會飛
本文來自:“
掘金”,了解相關資訊可以關注“掘金”