5G時代,業務資料越來越豐富,業務使用MySQL資料庫作為背景存儲,存儲引擎使用InnoDB,會帶來哪些挑戰?如何針對公司業務特點及MySQL資料庫特性,制定若幹資料庫使用規範供一線RD在設計業務時參考部分内容要求強制執行。本文從介紹MySQL相關關鍵基礎架構,并結合實際案例介紹表和索引的設計技巧,并對規範中重點内容做詳細解讀。
一、基礎知識
1.1 InnoDB記錄存儲方式
大家都知道在InnoDB存儲引擎中記錄是按主鍵順序存儲,并且依靠這個特性為表建立了主鍵聚簇索引。
InnoDB是如何實作記錄“順序存儲”的呢?首先要知道“順序”分頁内順序和頁間順序,頁為InnoDB内外存交換的基本機關。
頁間順序:磁盤檔案中頁與頁之間使用雙向連結清單連接配接,頁間有可能是實體有序。大多數情況是邏輯上的有序;
頁内順序:頁内各記錄使用單項連結清單把記錄連接配接起來,是以頁内是邏輯有序,配合slot資料結構實作頁内接近二分查找的查詢效率。
圖1 為InnoDB頁内空間分布:
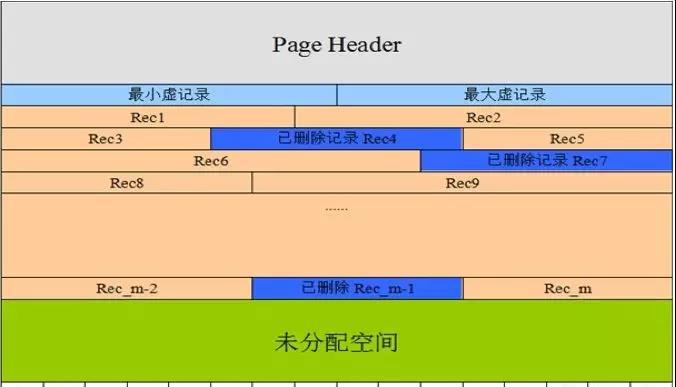
圖1 InnoDB頁内空間釋出
根據以上特點,我們來分析下使用不同的主鍵對存儲會造成哪些影響:
自增主鍵:主鍵值遞增,資料是順序插入的,是以在頁内資料實體連續,寫滿一頁後在順序配置設定下一頁。在沒有删除操作的情況下,整個表的記錄在磁盤檔案中都是按照寫入順序連續存儲的。其中存儲方式磁盤使用率非常高,且随機IO很低。插入效率相當高。
業務主鍵:比如使用者表使用“uid”做主鍵,商品表使用“infoId”做主鍵,這種有意義的主鍵,我們稱為業務主鍵。很明顯,業務主鍵不但無法做到記錄實體連續而且在插入資料時還可能造成頁的分裂,進而導緻頁内碎片,例如如果一個頁空間已滿,存儲主鍵值0~99,100條資料,如果要插入55這條記錄,頁内已經放不下,需要分裂成兩個頁才能完成插入操作,而分裂後的兩個頁很難被寫滿,會造成頁内碎片,是以業務主鍵在寫入性能和磁盤使用率上都不如自增主鍵。
通過上面的分析,我們是不是可以得出結論:使用自增主鍵一定好呢?在我們分析完InnoDB的索引以前,現在下結論還有些早。
1.2 主鍵索引
InnoDB會自動在表的主鍵上建立索引,資料結構使用B+ Tree。根據存儲上的特點主鍵索引也被稱為聚簇索引。聚簇索引的索引結構和實際資料是存儲在一起的,B+ Tree葉子節點存儲的就是實際的記錄,如圖2所示:

圖2 B+ Tree存儲結構
1.3 非主鍵索引
既然記錄存儲在主鍵索引結構中,那麼在其他列建立的索引是如何找到記錄的呢?我們可以很自然的想到,非主鍵列上的索引可以先通過自身索引結構查找到主鍵值,然後在用主鍵值在聚簇索引上找到相應的記錄。InnoDB就是這麼做的,是以我們也稱非主鍵列上的索引為二級索引(因為一次查詢需要查找兩個索引樹)。
二級索引有以下特點:
1、除了主鍵索引以外的索引;
2、索引結構葉子節點中的Data是主鍵值;
3、一次查詢需要查找自身和主鍵兩個索引;
1.4 聯合索引
聯合索引也叫多列索引,索引結構的key包含多個字段,排序時先第一列比較,如果相同再按第二列比較,以此類推。聯合索引結構圖如圖3所示:
圖3 聯合索引結構圖
聯合索引上的查詢要滿足以下特點:
1、key按照最左開始查找,否則無法使用索引;
2、跳過中間列,會導緻後面的列不能使用索引;
3、某列使用範圍查詢時,後面的列不能使用索引。
根據字首索引特性,聯合索引(a,b,c),可以滿足(a),(a,b),(a,b,c)三種查詢。
二、小結
了解了InnoDB的索引後,我們再來分析自增主鍵和業務主鍵優缺點:
自增主鍵:寫入、查詢效率和磁盤使用率都高,但每次查詢都需要兩級索引,因為線上業務不會有直接使用主鍵列的查詢。
業務主鍵:寫入、查詢效率和磁盤使用率都低,但可以使用一級索引,依賴覆寫索引的特性,某些情況下在非主鍵索引上也可以實作1次索引完成查詢(後面的案例中會介紹)。
自增主鍵相對業務主鍵在IO效率上優勢在SSD硬碟下幾乎可以忽略,而在業務查詢性能上業務主鍵有明顯優勢,是以在資料庫中使用的都是業務主鍵。
三、業務表設計
針對MyQL資料庫特性結合公司業務特點制定了一系列資料庫使用規範,可以有效的指導一線RD在項目開發過程中資料庫表和索引的設計工作。下面介紹業務中表和索引的重點設計原則以及兩個實際案例。
3.1 表設計原則
主鍵選擇:前面我們已經對比分析過業務主鍵和自增主鍵的優缺點,結論是業務主鍵更符合業務的查詢需求,而網際網路業務大多都符合讀多寫少的特性,是以所有線上業務都使用業務主鍵;
索引個數:由于過多的索引會造成索引檔案過大,是以要求索引數不多于5個;
列類型選擇:通常越小、越簡單越好,例如:BOOL字段統一使用TINYINT,枚舉字段統一使用TINYINT,交易金額統一使用LONG。因為BOOL和枚舉類型使用TINYINT可以很友善的擴充,針對金額資料,雖然InnoDB提供了支援精确計算的DECIMAL類型,但DECIMAL是存儲類型不是資料類型,不支援CPU原生計算,效率會低一些,是以我們簡單處理将小數轉為整數用LONG存儲。
分表政策:首先要明确資料庫出現性能問題一般在資料量到達一定程度後!是以要求我們提前做好預估,不要等需要拆分時再拆,一般把表的資料量控制在千萬級别;常用分表政策有兩種:按Key取模,讀寫均勻;按時間切分,冷熱資料明确;
3.2 實際案例
案例一:使用者表設計
使用者表包含字段:uid,nickname,mobile,addr,image…..,switch;
uid為主鍵,業務上有按uid和mobile兩種查詢需求,是以要在moblie上建立索引。
switch列比較特殊,類型為BIGINT,用來儲存使用者的BOOL類型的屬性,每一位可以儲存使用者的一個屬性,例如我們用第一位儲存是否接收推送,第二位儲存是否儲存離線消息等等。
這種設計有很高的擴充性(因為BIGINT有64位,可以儲存64個狀态,一般情況很難用滿),但是同時也帶來一些問題,switch有很高的查詢頻率。由于InnoDB是行存儲,要找查詢switch需要把正行資料取出來。
這對上述場景,我們可以表設計上可以做哪些優化呢?常用的方案是把表垂直查分,這種很常見我們不做過多讨論。
還有一種方案我們可以利用InnoDB覆寫索引的特性,在uid和switch兩列上建立聯合索引,這樣在二級索引上包含uid和switch兩列的值,這樣用uid查詢switch時,隻通過二級是以就能找到switch,不需要通路記錄,甚至不需要到二級索引的葉子節點就可以找到要查詢的switch值,查詢效率非常高。
另外有一點需要考慮,可以想象switch的變更也是相當頻繁的,switch值得改變會導緻聯合索引的變更嗎(這裡的變更指索引節點分裂或順序調整)?
答案是不會!因為聯合索引的第一列uid是唯一且不會變的,是以uid就已經決定了索引的順序,switch列的改變隻會改變索引節點上第二個key的值,不會改變索引結構。
五、總結
1、 自增主鍵性能不一定高,需要結合實際業務場景做分析;
2、 大多數場景資料類型選擇上盡量使用簡單的類型;
3、 索引不是越多越好,太多的索引會導緻過大的索引檔案;
4、 如果要查詢的資料可以在索引檔案中找到,存儲引擎就不會查找主鍵索引通路實際記錄。