前文 Kubernetes中的ClusterIP、NodePort、LoadBalancer、Ingress服務通路方式比較 中總結了服務接入通路的主要方式,以及它們之間隐含關系。有了這些概念基礎後,K8S應用開發和服務部署就容易很多了,但Under the hood服務通路究竟是如何實作的呢?這篇内容就Kubernetes的網絡模型和典型的容器網絡實作,特别是阿裡雲自己的容器網絡插件(Terway)的實作做了一個較詳細的總結。
Pod之間Container-to-Container networking
Linux networking namespace為程序通訊提供了一個邏輯網絡棧,包括network devices、routes、firewall rules。Network namespace(NS)管理實際是為其中的所有程序提供了一個獨立的邏輯網絡Stack。
預設情況下,Linux将每個程序挂載在Root NS下,這些程序通過eth0通往外面的世界。
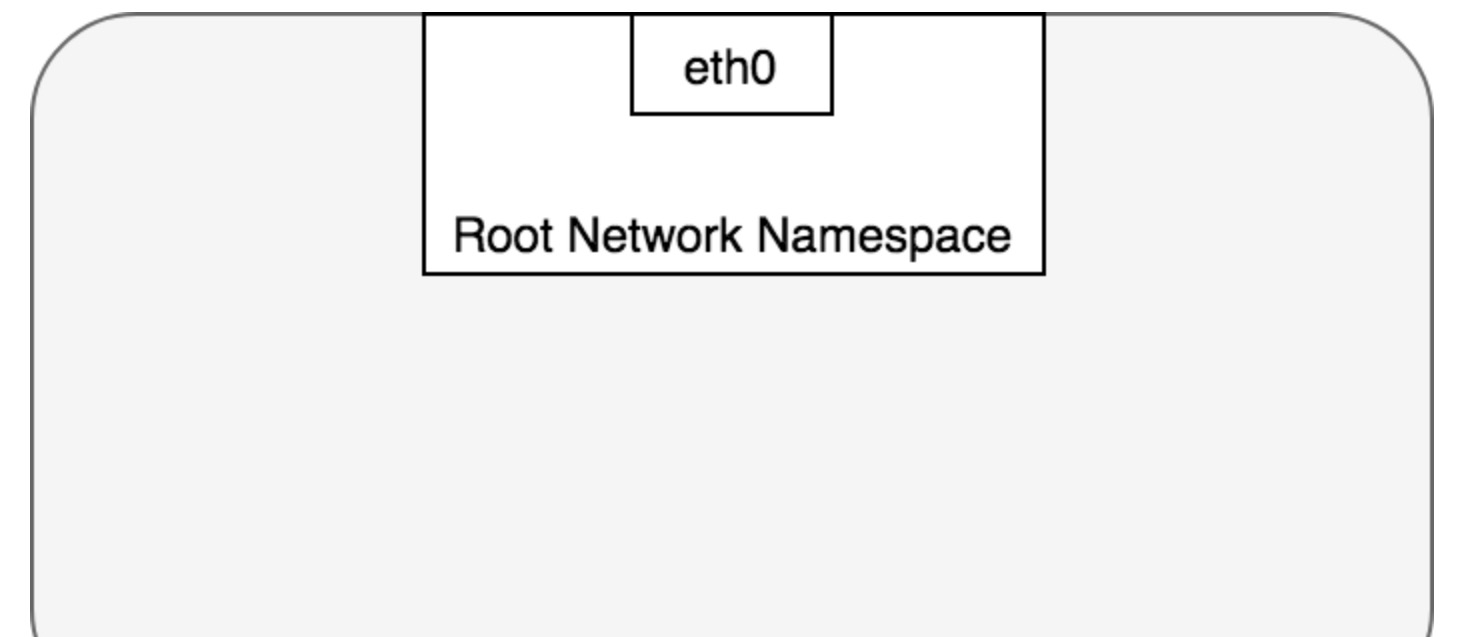
在Pod世界裡所有其中的容器共享一個NS,這些容器都有相同的IP和Port空間,通過localhost通路也是互通的。Shared storage也是可以通路的,通過SharedVolume挂載到容器中。如下一個NS per pod圖例:

同Node中Pod-to-Pod networking
先看同一個Node下Pod之間的networking如何實作?答案是通過
Virtual Ethernet Device (or veth pair)
的兩塊Virtual interfaces,每塊veth挂載在一個NS上,來實作跨NS的連接配接。比如,一塊挂在Root NS(host)上,另一塊挂在Pod NS上,好比一根網線把兩個在不同網絡空間的traffic連接配接起來了,如圖:
有了
veth pair
這條網線,Pods網絡可以連通到Root NS了,但在Root NS上如何實作對來自不同Pod的packet通訊呢?答案是通過
Linux Ethernet Bridge
,一個虛拟的Layer2網絡裝置來實作不同network segments之間的Ethernet packet switching。不得不提這個old-school協定:ARP,實作了MAC位址到IP位址的發現協定。Bridge廣播ethframe到所有連接配接的裝置(除發送者外),收到ARP回複後将packet forward到對應veth裝置上。如圖:
跨Node之間Pod-to-Pod networking
進入這部分之前,先提及K8S在其(Pod)networking設計上的3個fundamental requirements,任何networking部分的實作都必須遵循這三個需求。
- 在不使用NAT下,所有Pods都能和其它任何Pods通訊
- 在不使用NAT下,所有Nodes都能和所有Pods通訊
- Pod所看到自己的IP和其它Pods看到它的IP一定是相同的
簡要來看,K8S網絡模型要求Pod IP在整個網絡中都能通達。具體實作方案有三方面:
- Layer2(Switching)Solution
- Layer3(Routing)Solution,如,Calico, Terway
- Overlay Solution,如Flannel
這部分下文介紹,目前且認為Pod IP的網絡通達性是確定的。
在Pod獲得IP之前,kubelet為每個Node配置設定一個CIDR位址段(Classless inter-domain routing),每個Pod在其中擷取唯一IP,CIDR 位址塊的大小對應于每個Node的最大 Pod 數量(預設110個)。在Pod IP和跨Node網絡層部署成功後,從源Pod1到目的Pod4的通訊如圖:
Pod-to-Service networking
K8S Service管理服務的Pods狀态,在Pod有變化下管理對應IP的變化,并管理對外提供服務的Virtual IP到Pod IPs路由通路,實作外部對服務Virtual IP的通路路由到Pod IP,以此屏蔽外部對服務後端的實作形态。是以在服務建立時,會對應生成一個Virtual IP(也即是Cluster IP),任何對該Virtual IP的通路将打散路由到服務所屬的Pods上。
K8S的服務是如何實作對Virtual IP的通路負載均衡呢?答案是netfilter和iptables。netfilters是Linux built-in networking framework,為Linux提供網絡包過濾、NAT和Port translation等豐富的自定義handler實作。iptables是運作在Linux user-space的規則管理系統,為netfilter架構提供豐富的包轉發規則管理。
在K8S實作中kube-proxy(node deamon)通過watch apiserver來獲得服務配置的變化,比如,服務的Virtual IP變化、Pod IP變化(ie, pod up/down)。iptables規則随之變化并将請求路由到服務對應的Pod上,Pod IP選取是随機的,這樣看iptables起到了Pod負載均衡作用。在通路請求Return path上,iptables會做一次SNAT以替換IP header的Pod IP為服務Virtual IP,這樣使得Client看起來請求僅在服務Virtual IP上進行通訊。
從K8S v1.11中IPVS(IP Virtual Server)被引入成為第二種叢集内負載均衡方式。IPVS同樣也是建構基于netfilter之上,在建立服務定義時可指定使用iptables或IPVS。IPVS是特定适合于服務負載均衡的解決方案,提供了非常豐富的均衡算法應用場景。
使用DNS
每個服務會設定一個DNS域名,
kubelets
為每個容器進行配置
--cluster-dns=<dns-service-ip>
,用以解析服務所對應DNS域名到對應的Cluster IP或Pod IP。1.12後CoreDNS成為預設DNS方式。服務支援3種類型DNS records(A record、CNAME、SRV records)。其中常用的是A Records,比如,在
cluster.local
的DNS name下,A record格式如
pod-ip-address.my-namespace.pod.cluster.local
,其中Pod hostname和subdomain字段可以設定為标準的FQDN格式,比如,
custom-host.custom-subdomain.my-namespace.svc.cluster.local
CNI
網絡模型的實作上K8S在Pod資源管控(kubelet)和一套标準Container Networking Interface(CNI)定義和實作共同完成的。CNI在其中充當了"膠水"作用:各種容器網絡實作能在一緻的操作接口下由kubelet統一管控排程。另外,多個容器網絡也能共存于一個叢集内,為不同Pod的網絡需求提供服務,都是在kubelet的統一管控下完成。
Overlay networking: Flannel
Flannel是CoreOS為K8S networking開發的解決方案,也是阿裡雲
ACK産品支援的容器網絡解決方案。Flannel的設計原理很簡潔,在host網絡之上建立另一個扁平網絡(所謂的overlay),在其上位址空間中給每個pod容器設定一個IP位址,并用此實作路由和通訊。
主機内容器網絡在docker bridge
docker0
上完成通訊,不再贅述。主機間通訊使用核心路由表和IP-over-UDP封裝進行實作。容器IP包流經docker bridge會轉發到
flannel0
網卡(TUN)裝置上,進而流入到
flanneld
程序中。
flanneld
會對packet目标IP位址所屬的網段資訊查詢其對應的
下一跳
主機IP,容器子網CIDR和所屬主機IP的映射(key-value)儲存在etcd中,
flanneld
查詢得到packet目标IP所屬的主機IP位址後,會将IP packet封裝到一個UDP payload中并設定UDP packet目标位址為所得到的目标主機IP,最後在host網絡中發送出UDP packet。到達目标主機後,UDP packet會流經
flanneld
并在這裡解封出IP packet,再發送至
flannel0
、
docker0
最後到達目标容器IP位址上。下圖示意流程:
值得一提是,容器CIDR和下一跳主機IP的映射條目容量沒有特殊限制。在阿裡雲ACK産品上該條目容量需要在VPC/vSwitch控制面中進行分發,考慮到整體性能因素,在數量上做了一定數量限制(預設48個)。但在自建主機網絡部署中,該數量限制就不會明顯了,因為主機下一跳主機網絡在一個大二層平面上。
Flannel新版本backend不建議采用UDP封裝方式,因為traffic存在3次使用者空間與核心空間的資料拷貝,(如下圖)性能上存在比較大的損耗。新版本推薦用VxLan和雲服務商版本的
backends進行優化。
L3 networking: Calico
Calico是L3 Routing上非常流行容器網絡架構方案。主要元件是
Felix,BIRD和BGP Route Reflector。Felix和BIRD均是運作在Node上的deamon程式。
Felix完成網卡的管理和配置,包括Routes programming和ACLs。實作路由資訊對
Linux kernel FIB的操作和ACLs的管理操作。由于Felix功能完整性和運作獨立性非常好,其功能作為Off-the-shelf被內建到阿裡雲Terway網絡插件中,實作其網絡政策功能。
BIRD(BGP client)完成核心路由FIB條目向叢集網絡側分發,使其路由條目對所有網絡節點中可見,并實作BGP路由協定功能。每一個BGP client會連接配接到網絡中其它BGP client,這對規模較大的部署會是明顯的瓶頸(due to the N^2 increase nature)。鑒于該限制引入了BGP Route Reflector元件,實作BGP clients路由分發的中心化彙聚。在叢集網站中Reflector元件可以部署多個,完全能于部署規模大小來決定。Reflector元件僅僅執行路由信令和條目的分發,其中不涉及任何資料面流量。如下簡要的Calico架構:
L3 networking:Terway
Terway是阿裡雲自研CNI插件,提供了阿裡雲VPC互通和友善對接阿裡雲産品的基礎設施,沒有overlay網絡帶來的性能損耗,同時提供了簡單易用的backend功能。
Terway功能上可分為三部分:1. CNI插件,一個獨立的binary運作程式;2. Backend Server(也稱為daemon),程式以獨立daemonSet方式運作在每個Node上;3. Network Policy,完全內建了Calico Felix實作。
CNI插件binary是通過daemonSet部署中initContainer安裝到所有節點上,實作了
ADD
DEL
CHECK
三個接口供kubelet調用。這裡以一個Pod在建立過程中的網絡setup步驟來說明:
- 當一個Pod被排程到節點上時,kubelet監聽到Pod建立在自己節點上,通過runtime(docker...)建立sandbox容器來打通所需namespace。
- kubelet調用插件binary的
cmdAdd
AllocIP
- backendServer程式的
networkService
ENIMultiIP
VPCENI
VPCIP
-
ENIMultiIP
networkService
ResourceManager
-
VPCENI
networkService
allocateENI
-
VPCIP
ipam
-
- 在backendServer傳回
AllocIP
綜上圖示:
為什麼需要支援上述三種網絡類型?根本上是由阿裡雲vpc網絡基礎設施所決定,同時覆寫阿裡雲主流應用對vpc網絡資源的使用場景需求。另一方面是對标Amazon AWS的容器網絡解決方案,在基于VPC和ENI的網絡設施上能支援同等功能。
ENI多IP、VPC ENI和VPC IP的主要差別在于前兩者下的Pod網段和VPC網段是相同的,而VPC IP的網段和節點的主控端網段不同。這樣使得在ENI網絡環境下的IP路由完全在VPC的L2網絡平面上進行,而VPC IP網絡需要在VPC路由表中進行配置Pod網段的下一跳主機,和Flannel的路由模式類似。可以看出,ENI網絡能帶來更靈活的路由選擇和更好的路由性能。如下兩個截圖反映其不同路由特點:
VPC ENI網絡:
VPC IP網絡:
ENI多IP(1個主IP/多個輔助IP)網絡下有2種路由模式:
veth政策路由
和
ipvlan
。兩者本質差別在于使用不同的路由模式,前者使用
veth pair
的政策路由,後者使用
ipvlan
網絡路由。政策路由需要在節點上配置政策路由條目來保證輔助IP的流量經過它所屬的彈性網卡。
ipvlan
實作了一個網卡虛拟出多個子網卡和不同的IP位址,eni将其輔助IP綁定到這些虛拟出來的子網卡上形成一個與vpc平面打通的L3網絡。這種模式使ENI多IP的網絡結構比較簡單,性能相對
veth政策路由
網絡也更好。兩種網絡模式切換通過配置即可完成(預設是
vethpair
):
值得一提的是Terway還實作了ENI多IP位址資源池的管理和配置設定機制。
networkService
eniIPFactory
為每個eni網卡建立一個goroutine,該eni網卡上的eniIP的配置設定釋放都在這個goroutine中完成。在建立一個eniIP時掃描已經存在的eni網卡,如該eni還存在空閑的eniIP,該goroutine會通過
ipResultChan
傳回給
eniIPFactory
一個配置設定的IP。如果所有的eni網卡的eniIP都配置設定完畢,會先建立一個新的eni網卡和對應的goroutine,首次建立eni網卡時無需做IP配置設定,直接傳回eni網卡主IP即可。eniIP釋放是逆向的,在eni網卡的最後一個eniIP釋放時,整個eni網卡資源會釋放掉。
另外,有一個
startCheckIdleTicker
goroutine會定期掃描位址池的
MaxPoolSize
MinPoolSize
水位,在低于和高出水位閥值時會對位址池eniIP資源進行進行建立和釋放,使得位址池IP資源處于一個可控水位範圍中。為了保證資源狀态一緻性,有一個
startGarbageCollectionLoop
goroutine會定期掃描IP位址是否在用或過期狀态,如檢測到會進行資源GC操作。最後,Pod資源狀态資料都持久化在本地的一個
boltDB
檔案中
/var/lib/cni/terway/pod.db
,即使Pod已經在apiServer中删除,
GetPod
會從本地
boltDB
中讀取副本資料。在Pod已經删除但副本還存在DB的情況下,GC goroutine檢測到會執行清理。截圖簡述:
總結下,從這些backend功能可以看到Terway為阿裡雲vpc網絡資源設施連通性做了很好的封裝,讓基于阿裡雲Kubernetes的應用開發和部署帶來更加簡便和高效的優點。