好程式員大資料教育訓練分享之Hadoop的單節點叢集設定(獨立模式),接下來,我們就來了解一下Hadoop叢集的安裝。而Hadoop的安裝模式有以下三種,我們一一來了解一下:
單節點上的本地模式(獨立模式) :Local(Standalone)Mode
單節點的僞分布模式:Pseudo-Distributed Mode
多節點的安全分布式叢集模式:Fully-Distributed Cluster
1 本地模式介紹
1.1 特點:
運作在單台機器上,沒有分布式思想,使用的是本地檔案系統
1.2. 用途
用于對MapReduce程式的邏輯進行調試,確定程式的正确。由于在本地模式下測試和調試MapReduce程式較為友善,是以,這種模式适宜用在開發階段。
2 平台軟體說明
- 作業系統: win10/win7
- 虛拟軟體: VMware14
- 虛拟機: CentOS_7.7_64_master192.168.10.200
- 軟體包存儲路徑: /opt/software/
- 軟體安裝路徑: /opt/apps/
- Jdk: jdk-8u221-linux-x64.tar.gz
- Hadoop: hadoop-2.7.6.tar.gz
- 使用者: root
3 環境搭建:Jdk的安裝步驟
步驟1)檢查一下是否已經安裝過或者系統内置JDK,如果有内置的,将其解除安裝
[root@master ~]# rpm -qa | grep jdk
如果有,請解除安裝
[root@master ~]# rpm -e xxxxxxxx --nodeps #将查詢到的内置jdk代替xxxxxxx
步驟2)上傳jdk1.8
将jdk-8u221-linux-x64.tar.gz上傳到/opt/software/目錄中
步驟3)解壓jdk到/opt/apps/下
[root@master ~]# cd /opt/software
[root@master software]# tar -zxvf jdk-8u221-linux-x64.tar.gz -C /opt/apps/
步驟4)更名jdk
[root@master ~]# cd /opt/apps
[root@master apps]# mv jdk1.8.0_221/ jdk
步驟5)配置Jdk的環境變量:/etc/profile
[root@master apps]# vi /etc/profile
.........省略...........
jdk environment
export JAVA_HOME=/opt/apps/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
步驟6)使目前視窗生效
[root@master apps]# source /etc/profile
步驟7)驗證jdk環境
[root@master apps]# java -version
[root@master apps]# javac
4 hadoop目錄結構說明
1 Hadoop目錄結構如下:(可以提前在window系統上解壓,看一下)
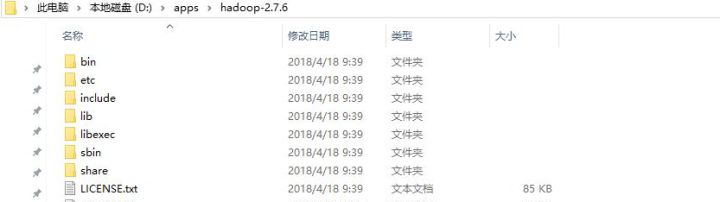
--1. bin: hadoop的二進制執行指令檔案存儲目錄
--2. sbin: hadoop的執行腳本存儲目錄
--3. etc: hadoop的配置檔案存儲目錄
--4. lib/libexec: hadoop的資源庫存儲目錄
--5. share:hadoop的共享資源、開發工具和案例存儲目錄
--6. include: hadoop的工具腳本存儲目錄
5 環境搭建:Hadoop的安裝步驟
步驟1) 上傳并解壓hadoop
将hadoop軟體包上傳到/opt/software目錄下,然後解壓到/opt/apps/目錄下
[root@master ~]# cd /opt/software/
[root@master software]# tar -zxvf hadoop-2.7.6.tar.gz -C /opt/apps/
步驟2)更名hadoop
[root@master software]# cd /opt/apps
[root@master apps]# mv hadoop-2.7.6/ hadoop
步驟3)配置hadoop的環境變量
.........省略..........
hadoop environment
export HADOOP_HOME=/opt/apps/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
步驟4)使目前視窗生效
步驟5)驗證hadoop
[root@master apps]# hadoop version
3.6 程式案例示範:grep程式
步驟1) 進入hadoop的根目錄
[root@master apps]# cd $HADOOP_HOME
步驟2) 建立一個目錄input
[root@master hadoop]# mkdir input
步驟3) 将$HADOOP_HOME/etc/hadoop/目錄下的所有xml檔案複制到input目錄下
[root@master hadoop]# cp ./etc/hadoop/*.xml ./input
步驟4) 使用hadoop自帶的grep程式查找input目錄下的檔案是否有符合正規表達式'dfs[a-z.]'的字元串
[root@master hadoop]# hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep input ./output 'dfs[a-z.]'
指令行内容解析:
--1. 使用hadoop指令運作jar檔案
--2. 同時指定具體的jar檔案的路徑
--3. 使用jar檔案裡的grep主程式
--4. 統計目前目錄下的input目錄裡的内容,
--5. 将統計結果輸出到目前目錄下的output目錄
--6. 給grep指定一個正規表達式
注意:輸出目錄是一個不存在的目錄,程式會自動生成
步驟5) 進入output目錄檢視part-r-00000檔案
[root@master hadoop]# cd ./output
[root@master output]# cat part-r-00000
3.7 案例測試_wordcount.
[root@master hadoop]# hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount
![Java String.format方法的簡單使用[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)