文法分析器是編譯器前端的核心
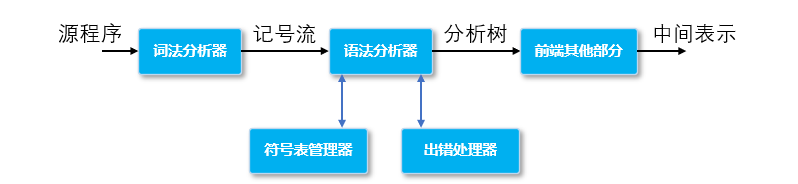
文法分析器的兩項主要任務,分别:
- 是根據詞法分析器提供的記号流,為文法正确的輸入構造分析樹(或文法樹);
- 檢查輸入中的文法 / 詞法錯誤,并調用出錯處理程式進行相應的處理。
文法錯誤的處理
源程式中的錯誤可以分為詞法/文法錯誤、語義錯誤兩類。前者主要形式是命名不合法、關鍵字書寫錯誤、文法結構有問題(比如缺分号、該配對的東西不配對)等;後者則可分為靜态/動态兩種,靜态例如類型使用錯誤、參數使用錯誤等,動态語義錯誤則是無窮遞歸這類邏輯性的問題。
文法錯誤的處理目标
- 不多不漏地報告所有錯誤出現的準确位置;
- 發現一個錯誤後能夠繼續分析,做到一次分析完整個程式,再一次性指出所有錯誤;
- 盡量小地降低分析速度(分析速度和掃描遍數有關)。
文法錯誤的基本恢複政策
- 緊急恢複:抛棄掉一些輸入,直到遇到同步記号;
- 短語級恢複:對錯誤進行串替換,糾正錯誤;
- 出錯産生式:用出錯産生式捕捉(預測)錯誤;
- 全局糾正:找到和錯誤輸入序列 x 最相近的序列 y,然後用 y 替換掉 x 。
例如:
x = a+b
y = c+d; 緊急恢複:x = a+b+d; // 丢棄掉 b 後的記号,直到遇到 +
短語級恢複: x = a+b; // 加入分号
在寫程式時,要養成減少錯誤的好習慣:每次用變量、參數時,要在使用之前進行初始化,并在直接使用之前檢查一下是否出現值為空等問題,防止出現不可預知的錯誤
![VBScript編譯器(VBS也瘋狂) v2.3 綠色[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)