雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
導讀:Alluxio 項目誕生于 UC Berkeley AMP 實驗室,自開源以來經過 7 年的不斷開發疊代,支撐大資料處理場景的資料統一管理和高效緩存功能日趨成熟。然而,随着雲原生人工智能(Cloud Native AI)的興起,靈活的計算存儲分離架構大行其道。在此背景下,使用者在雲上訓練大規模深度學習模型引發的資料緩存需求日益旺盛。為此,阿裡雲容器服務團隊與 Alluxio 開源社群和南京大學顧榮老師等人通力合作尋找相關解決方案,目前已經提供 K8s 上運作模型訓練資料加速的基礎方案,包括容器化部署、生命周期管理以及性能優化(持續中),進而降低資料通路高成本和複雜度,進一步助力雲上普惠 AI 模型訓練。
1. 背景介紹
近些年,以深度學習為代表的人工智能技術取得了飛速的發展,正落地應用于各行各業。随着深度學習的廣泛應用,衆多領域産生了大量強烈的高效便捷訓練人工智能模型方面的需求。另外,在雲計算時代,以 Docker、Kubernetes 以主的容器及其編排技術在應用服務自動化部署的軟體開發運維浪潮中取得了長足的發展。Kubernetes 社群對于 GPU 等加速計算裝置資源的支援方興未艾。鑒于雲環境在計算成本和規模擴充方面的優勢,以及容器化在高效部署和靈活疊代方面的長處,基于“容器化彈性基礎架構+雲平台 GPU 執行個體”進行分布式深度學習模型訓練成為了業界生成 AI 模型的主要趨勢。
為了兼顧資源擴充的靈活性,雲應用大多采用計算和存儲分離的基本架構。其中,對象存儲因為能夠有效地降低存儲成本、提升擴充彈性,經常用來存儲管理海量訓練資料。除了采用單一雲上存儲之外,很多雲平台的使用者因為安全合規、資料主權或者遺産架構方面的因素,大量資料還存儲在私有資料中心。這些使用者希望基于混合雲的方式建構人工智能訓練平台,利用雲平台的彈性計算能力滿足高速增長的 AI 業務模型訓練方面的需求,然而這種“本地存儲+雲上訓練”的訓練模式加劇了計算存儲分離架構帶來的遠端資料通路的性能影響。計算存儲分離的基本架構雖然可以為計算資源和存儲資源的配置和擴充帶來更高的靈活性,但是從資料通路效率的角度來看,由于受限于網絡傳輸帶寬,使用者不經調優簡單使用這種架構通常會遇到模型訓練性能下降的問題。
2. 正常方案面臨的資料通路挑戰
目前雲上深度學習模型訓練的正常方案主要采用手動方式進行資料準備,具體是将資料複制并分發到雲上單機高效存儲(例如,NVMe SSD)或分布式高性能存儲(例如 GlusterFS 并行檔案系統)上。這種由使用者手工或者腳本完成的資料準備過程通常面臨如下三個問題:
1.資料同步管理成本高: 資料的不斷更新需要從底層存儲定期進行資料同步,這個過程管理成本較高;
2.雲存儲成本開銷更多: 需要為雲上單機存儲或高性能分布式存儲支付額外費用;
3.大規模擴充更加複雜: 随着資料量增長,難以将全部資料複制到雲上單機存儲;即使複制到 GlusterFS 這樣的海量并行檔案系統也會花費大量的時間。
基于容器和資料編排的模型訓練架構方案
針對雲上深度學習訓練正常方案存在的上述問題,我們設計并實作了一種基于容器和資料編排技術的模型訓練架構方案。具體系統架構如圖 1 所示:
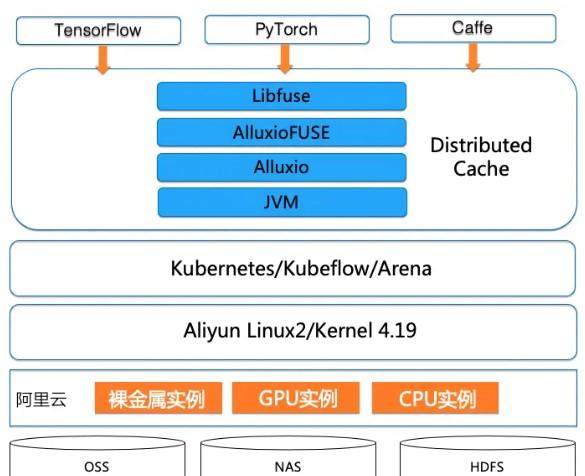
系統架構核心元件
- Kubernetes:是一種流行的深度神經網絡訓練容器叢集管理平台,它提供了通過容器使用不同機器學習架構的靈活性以及按需擴充的靈活性。阿裡雲容器服務 ACK(Alibaba Cloud Kubernetes)是阿裡雲提供的 Kubernetes 服務,可以在阿裡雲平台的 CPU、GPU、NPU(含光 800 晶片)、神龍裸金屬執行個體上運作 Kubernetes 工作負載;
- Kubeflow:是開源的基于 Kubernetes 雲原生 AI 平台,用于開發、編排、部署和運作可擴充的便攜式機器學習工作負載。Kubeflow 支援兩種 TensorFlow 架構分布式訓練,分别是參數伺服器模式和 AllReduce 模式。基于阿裡雲容器服務團隊開發的 Arena,使用者可以送出這兩種類型的分布式訓練架構;
- Alluxio:是面向混合雲環境的開源資料編排與存儲系統。通過在存儲系統和計算架構之間增加一層資料抽象層,提供統一的挂載命名空間、階層化緩存和多種資料通路接口,可以支援大規模資料在各種複雜環境(私有雲叢集、混合雲、公有雲)中的資料高效通路。

Alluxio 發轫于大資料時代,流觞自誕生了 Apache Spark 的 UC Berkeley AMP 實驗室。Alluxio 系統設計的初衷是為了解決大資料處理流水線中不同計算架構在通過磁盤檔案系統(如 HDFS)互換資料,造成整個分析性能瓶頸耗時在 I/O 操作方面的問題。Alluxio 項目開源于 2013 年,經過 7 年的不斷開發疊代,在大資料處理場景下的應用日趨成熟。另外,近些年随着深度學習的崛起,Alluxio 分布式緩存技術正逐漸成為業界解決雲上 I/O 性能問題的主流解決方案。進一步地,Alluxio 推出基于 FUSE 的 POSIX 檔案系統接口,為雲上 AI 模型訓練提供了高效的資料通路手段。
為了能夠更好的将 Alluxio 融入 Kubernetes 生态系統發揮兩者結合的優勢,Alluxio 團隊和阿裡雲容器服務團隊協作開發提供了 Alluxio 的 Helm Chart 方案, 極大地簡化了在 Kubernetes 内的部署和使用。
雲上訓練——Alluxio 分布式緩存初探
1. 深度學習實驗環境
- 我們使用 ResNet-50 模型與 ImageNet 資料集,資料集大小 144GB,資料以 TFRecord 格式存儲,每個 TFRecord 大小約 130MB。每個 GPU 的 batch_size 設定為 256;
- 模型訓練硬體選擇的是 4 台 V100(高配 GPU 機型),一共 32 塊 GPU 卡;
- 資料存儲在阿裡雲對象存儲服務中,模型訓練程式通過 Alluxio 讀取資料,并在讀取過程中将資料自動緩存到 Alluxio 系統。Alluxio 緩存層級配置為記憶體,每台機器提供 40GB 記憶體作為記憶體存儲,總的分布式緩存量為 160GB,沒有使用預先加載政策。
2. 初遇性能瓶頸
在性能評估中,我們發現當 GPU 硬體從 NVidia P100 更新到 NVidia V100 之後,單卡的計算訓練速度得到了不止 3 倍的提升。計算性能的極大提升給資料存儲通路的性能帶來了壓力。這也給 Alluxio 的 I/O 提出了新的挑戰。
下圖是在分别在合成資料(Synthetic Data)和使用 Alluxio 緩存的性能對比,橫軸表示 GPU 的數量,縱軸表示每秒鐘處理的圖檔數。合成資料指訓練程式讀取的資料有程式自身産生,沒有 I/O 開銷,代表模型訓練性能的理論上限; 使用 Alluxio 緩存指訓練程式讀取的資料來自于 Alluxio 系統。
在 GPU 數量為 1 和 2 時,使用 Alluxio 和合成資料對比,性能差距在可以接受的範圍。但是當 GPU 的數量增大到 4 時,二者差距就比較明顯了,Alluxio 的處理速度已經從 4981 images/second 降到了 3762 images/second。 而當 GPU 的數量達到 8 的時候,Alluxio 上進行模型訓練的性能不足合成資料的 30%。而此時通過系統監控,我們觀察到整個系統的計算、記憶體和網絡都遠遠沒有達到瓶頸。這間接說明了簡單使用 Alluxio 難以高效支援 V100 單機 8 卡的訓練場景。
為了能夠深入了解是什麼因素影響了性能并進行調優,需要首先研究分析 Alluxio 在 Kubernetes 下支援 FUSE 的整個技術棧。如下圖所示:
3. 原因剖析
通過深度分析整個技術棧和Alluxio核心,我們将造成相關性能影響的原因總結如下:
1.Alluxio 檔案操作引入多次 RPC 互動,在訓練場景下引入性能開銷。
Alluxio 不隻是一個單純的緩存服務。它首先是一個分布式虛拟檔案系統,包含完整的中繼資料管理、塊資料管理、UFS 管理(UFS 是底層檔案系統的簡稱)以及健康檢查機制,尤其是它的中繼資料管理實作比很多底層檔案系統更加強大。這些功能是 Alluxio 的優點和特色,但也意味着使用分布式系統帶來的開銷。例如,在預設設定下使用 Alluxio 用戶端來讀一個檔案,即便資料已經緩存在本地的 Alluxio Worker 中,用戶端也會和 Master 節點有多次 RPC 互動來擷取檔案元資訊以保證資料的一緻性。完成整個讀操作的鍊路額外開銷在傳統大資料場景下并不明顯,但是深度面對學習場景下高吞吐和低延時的需求就顯得捉襟見肘了。
2.Alluxio 的資料緩存和驅逐政策會頻繁觸發節點資料緩存震蕩。
深度學習場景資料冷熱經常不明顯,是以每個 Alluxio Worker 都會完整讀取資料。而 Alluxio 預設模式會優先資料本地讀取,即使資料已經儲存在 Alluxio 叢集中,也會從其他緩存節點拉取到本地存一份副本。這個特性在我們的場景下會帶來兩個額外開銷:
- 異步資料緩存的額外開銷;
- 本地空間不足會觸發自動資料驅逐的開銷,特别當節點緩存資料接近飽和的情況下性能開銷巨大。
3.基于 FUSE 進行檔案系統的開發、部署、使用都很簡單,但是預設性能并不理想,原因如下:
- FUSE 讀操作效率不高,每次 read 最多隻能讀 128KB,讀一個 128MB 的檔案需要 1000 次調用 read;
- FUSE 讀操作屬于非阻塞行為,由 libfuse 非阻塞線程池處理,一旦并發請求數量遠超過線程池 (max_idle_threads) 的大小,就會觸發頻繁的大量線程建立和删除,進而影響讀性能。而在 FUSE 中,這個預設配置是 10;
- 中繼資料的頻繁通路,因為 FUSE 核心子產品是個橋梁角色,連接配接了應用程式和 Alluxio 的檔案系統,而每一次讀擷取檔案/目錄的 inode 以及 dentry,FUSE 核心子產品都會到 Alluxio 系統運作一趟,增加了系統壓力。
4.Alluxio 和 FUSE 的內建(下文簡稱為 AlluxioFUSE)在深度學習中常見的多線程高并發場景下性能有待優化,甚至需要深度定制:
- Alluxio 目前僅支援在 FUSE 中使用 direct_io 模式,而不能使用 kernel_cache 模式來借助 page cache 進一步提高 I/O 效率。這是因為 Alluxio 目前設計要求在多線程場景下,每個線程都必須使用自己的檔案輸入句柄(FileInputStream)。而如果打開 page cache,目前的 AlluxioFUSE 會有些并發預先讀到 cache 的操作,進而産生報錯;
- 據從被 Alluxio 用戶端讀入後,到進入 FUSE 要經曆多次拷貝。這些額外的拷貝通常是由于 AlluxioFUSE 使用到的第三方 Java 庫 API 限制;
- AlluxioFUSE 實作中使用到的第三方庫 JNRFuse 隻能适配較低版本的 FUSE,并且在高并發場景下有較大的性能負擔。
5.Kubernetes 對于 Alluxio 的線程池影響。
Alluxio 基于 Java 1.8 版本實作,其中的一些線程池的計算會依賴于 Runtime.getRuntime().availableProcessors(),但是在 Kubernetes 環境下,預設配置中 cpu_shares 的值為 2,而 JVM 對于 cpu 的核心數的計算公式 cpu_shares()/1024,導緻結果是 1。這會影響 java 程序在容器内的并發能力。
雲上模型訓練的性能優化
在分析了上述性能問題和因素之後,我們将設計了一系列性能優化政策以提升雲上模型訓練的性能。首先,需要明白資料通路的“多快好省”是無法全部兼顧,我們針對的主要是模型訓練下隻讀資料集的資料通路加速。優化的基本思路是關注高性能和資料一緻性,而犧牲一部分靈活的自适應性(比如讀寫同時發生,資料内容不斷更新等場景)。
基于上述思路,我們設計了具體的性能優化政策,這些政策遵循以下核心原則:
- 尋找資源限制,包括線程池以及 JVM 在容器中的配置;
- 借助各級緩存,包括 FUSE 層和 Alluxio 中繼資料緩存;
- 避免額外開銷,減少非必須的調用鍊路。比如避免不必要的中繼資料互動,引入上下文切換的 GC 線程和 compiler 程序;以及 Alluxio 内部的一些可以簡化的操作。
下面将從各層的元件優化角度,對這些優化政策逐一介紹:
1. 對 FUSE 的優化
更新 Linux Kernel 版本
FUSE 實作分為兩層:運作在使用者态的 libfuse 和運作在核心态的 FUSE Kernel。高版本的 Linux Kernel 針對 FUSE 做了大量的優化。我們對比了 Kernel 3.10 和 4.19 的性能,發現讀性能可以達到 20% 的提升。
優化 FUSE 參數
(1).延長 FUSE 中繼資料有效時間
Linux 中每個打開檔案在核心中擁有兩種中繼資料資訊:struct dentry 和 struct inode,它們是檔案在核心的基礎。所有對檔案的操作,都需要先擷取檔案這兩個結構。是以,每次擷取檔案/目錄的 inode 以及 dentry 時,FUSE 核心子產品都會從 libfuse 以及 Alluxio 檔案系統進行完整操作,這樣會帶來資料通路的高延時和高并發下對于 Alluxio Master 的巨大壓力。可以通過配置 –o entry_timeout=T –o attr_timeout=T 進行優化。
(2).配置 max_idle_threads 避免頻繁線程建立銷毀引入 CPU 開銷。
這是由于 FUSE 在多線程模式下,以一個線程開始運作。當有兩個以上的可用請求,則 FUSE 會自動生成其他線程。每個線程一次處理一個請求。處理完請求後,每個線程檢查目前是否有超過 max_idle_threads (預設 10) 個線程;如果有,則該線程回收。而這個配置實際上要和使用者程序生成的 I/O 活躍數相關,可以配置成使用者讀線程的數量。而不幸的是 max_idle_threads 本身隻在 libfuse3 才支援,而 AlluxioFUSE 隻支援 libfuse2, 是以我們修改了 libfuse2 的代碼支援了 max_idle_threads 的配置。
2. 對 Alluxio 的優化
Alluxio 和 FUSE 的內建通過一個名為 AlluxioFuse 的程序實作。該程序在運作期會通過調用内嵌的 Alluxio 用戶端和運作的 Alluxio Master 以及 Worker 互動。我們針對深度學習的場景,定制 AlluxioFuse 所使用的 Alluxio 屬性來優化性能。
避免頻繁逐出(Cache Eviction)造成緩存抖動
由于深度學習訓練場景下,每次訓練疊代都是全量資料集的疊代,緩存幾個 TB 的資料集對于任何一個節點的存儲空間來說都是捉襟見肘。而 Alluxio 的預設緩存政策是為大資料處理場景(例如查詢)下的冷熱資料分明的需求設計的,資料緩存會儲存在 Alluxio 用戶端所在的本地節點,用來保證下次讀取的性能最優。具體來說:
(1).alluxio.user.ufs.block.read.location.policy 預設值為 alluxio.client.block.policy.LocalFirstPolicy, 這表示 Alluxio 會不斷将資料儲存到 Alluxio 用戶端所在的本地節點,就會引發其緩存資料接近飽和時,該節點的緩存一直處于抖動狀态,引發吞吐和延時極大的下降,同時對于 Master 節點的壓力也非常大。是以需要 location.policy 設定為 alluxio.client.block.policy.LocalFirstAvoidEvictionPolicy 的同時,指定 alluxio.user.block.avoid.eviction.policy.reserved.size.bytes 參數,這個參數決定了當本地節點的緩存資料量達到一定的程度後,預留一些資料量來保證本地緩存不會被驅逐。通常這個參數應該要大于 節點緩存上限 X (100% - 節點驅逐上限的百分比) 。
(2).alluxio.user.file.passive.cache.enabled 設定是否在 Alluxi 的本地節點中緩存額外的資料副本。這個屬性是預設開啟的。是以,在 Alluxio 用戶端請求資料時,它所在的節點會緩存已經在其他 Worker 節點上存在的資料。可以将該屬性設為 false,避免不必要的本地緩存。
(3).alluxio.user.file.readtype.default 預設值為 CACHE_PROMOTE。這個配置會有兩個潛在問題,首先是可能引發資料在同一個節點不同緩存層次之間的不斷移動,其次是對資料塊的大多數操作都需要加鎖,而 Alluxio 源代碼中加鎖操作的實作不少地方還比較重量級,大量的加鎖和解鎖操作在并發較高時會帶來不小的開銷,即便資料沒有遷移還是會引入額外開銷。是以可以将其設定為 CACHE 以避免 moveBlock 操作帶來的加鎖開銷,替換預設的 CACHE_PROMOTE。
緩存中繼資料和節點清單
在深度學習訓練場景下,每次訓練任務開始前會列出所有訓練資料檔案并讀取其中繼資料,然後運作訓練任務的程序會進一步讀取訓練資料檔案。通過 Alluxio 讀取檔案通路時預設會完成如下操作:首先從 Master 擷取檔案中繼資料,從中擷取 block 中繼資料,再從 Worker 擷取 block 的具體位置,最後真正從擷取的位置讀取 block 資料。完成完整的操作鍊路包括多次 RPC 開銷,引入明顯的檔案通路延時。如果能将該資料檔案的 block 資訊緩存到用戶端記憶體中,會非常明顯的提升檔案的通路性能。
(1).将 alluxio.user.metadata.cache.enabled 設定為 true, 可以在 Alluxio 用戶端開啟檔案以及目錄的中繼資料緩存,避免二次通路時仍需要通過 RPC 通路中繼資料的問題。結合配置設定給 AlluxioFUSE 的堆大小,使用者可以配置 alluxio.user.metadata.cache.max.size 來設定最多緩存檔案和目錄的中繼資料數量,也可以配置 alluxio.user.metadata.cache.expiration.time 調整中繼資料緩存的有效時間。同時在每次選擇讀取資料的 Worker 節點時,Alluxio Master 節點也會不斷去查詢所有 Worker 節點的狀态,這也會在高并發場景下引入額外開銷。
(2).将 alluxio.user.worker.list.refresh.interval 設定為 2min 或者更長。
(3).讀取檔案也會不斷更新 last accesstime,實際上在高并發的場景下,這會對 Alluxio Master 造成很大壓力。我們通過修改 Alluxio 代碼增加了開關,可以關閉掉 last accesstime 的更新。
充分利用資料本地性
(1).資料本地性就是盡量将計算移到資料所在的節點上進行,避免資料在網絡上的傳輸。分布式并行計算環境下,資料的本地性非常重要。在容器環境下支援兩種短路讀寫方式:Unix socket 方式和直接檔案通路方式。
- Unix Socket 的方式好處在于隔離性好,不需要 Alluxio Client 和 Alluxio Worker 容器運作在同樣的 Network,UTS,Mount 的 Namespace。但是它的性能比直接檔案通路要差一些,同時會引發 netty 的 OutOfDirectMemoryError
- 而直接通路檔案的方式則是以需要確定同一台機器上運作的 Alluxio Worker 和 AlluxioFUSE 的主機名和 IP 位址一緻,同時要保證 Alluxio Client 和 Worker 共享同樣緩存目錄,這種方式性能更好同時更加穩定。但是它實際上犧牲了隔離性,需要二者共享 Network,UTS,Mount 的 Namespace
我們目前選擇的方案是優先采用後者。
3. 對 Java & Kubernetes 的優化
配置 ActiveProcessorCount
(1).Runtime.getRuntime().availableProcessors() 控制的;而如果通過 Kubernetes 部署容器而不指定 cpu 資源的 request 數量,容器内 Java 程序讀到 proc 檔案系統下的 cpushare 數量為 2, 而此時的 availableProcessors() 來自于 cpu_shares()/1024,會被算成 1。實際上限制了容器内 Alluxio 的并發線程數。考慮到 Alluxio Client 屬于 I/O 密集型的應用,是以可以通過 -XX:ActiveProcessorCount 設定處理器數目。這裡的基本原則是 ActiveProcessorCount 盡量設定得高些。
調整 GC,JIT 線程
(2).JVM 的預設 GC,JIT 編譯線程數量取決于 -XX:ActiveProcessorCount 的數量,但實際上也可以通過 -XX:ParallelGCThreads -XX:ConcGCThreads -XX:CICompilerCount 等參數配置,可以将其設定的小些,避免這些程序頻繁的搶占切換,導緻性能下降。
4. 性能優化效果
在優化 Alluxio 之後,ResNet50 的訓練性能單機八卡性能提升了 236.1%,并且擴充性問題得到了解決,訓練速度在不但可以擴充到了四機八卡,而且在此場景下和合成資料相比性能損失為 3.29%(31068.8 images/s vs 30044.8 images/s)。相比于把資料儲存到 SSD 雲盤,在四機八卡的場景下,Alluxio 的性能提升了 70.1% (雲 SSD 17667.2 images/s vs 30044.8 images/s)。
而實際訓練時間方面,使用 Alluxio 需要 65 分鐘(合成資料場景耗時 63 分鐘),和通過雲上 SSD 進行模型訓練相比節省了 45 分鐘,節省成本 40.9%。
5. 總結與進一步工作
在本文中,我們總結了 Alluxio 在高性能分布式深度學習模型訓練場景中落地的挑戰點,以及我們在優化 Alluxio 的實踐。進一步地,我們介紹了如何從多個層面提升 AlluxioFUSE 在高并發讀場景下性能優化的經驗。最後,我們實作的基于 Alluxio 優化的分布式模型訓練方案,并在 4 機 8 卡的 ResNet50 場景下進行了性能驗證,取得了很好的效果。
在進一步工作方面,對于高吞吐海量規模的小檔案和高并發讀場景,Alluxio 還有一些在 page cache 的支援和 FUSE 層的穩定性方面的工作,我們阿裡雲容器服務團隊也會和 Alluxio 開源社群以及南京大學戴海鵬、顧榮等老師一起繼續合作努力改進。我們相信通過工業界、開源社群和學術界和聯合的創新力量,能夠逐漸降低計算存儲分離場景下深度學習訓練的資料通路高成本和複雜度,進一步助力雲上普惠 AI 模型訓練。
6. 緻謝
感謝 Alluxio 團隊的範斌,邱璐,Calvin Jia,常铖在整個方案的設計和優化過程中的巨大幫助,從 Alluxio 自身能力上對于中繼資料緩存系統做了顯著的提升,為 Alluxio 落地 AI 場景開啟了可能性。
作者簡介
車漾 阿裡雲進階技術專家,從事 Kubernetes 和容器相關産品的開發。尤其關注利用雲原生技術建構機器學習平台系統,是 GPU 共享排程的主要作者和維護者;
顧榮 南京大學副研究員,Alluxio 項目核心開發者,研究方向大資料處理,2016 年獲南京大學博士學位,曾在微軟亞洲研究院、英特爾、百度從事大資料系統實習研發。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/live立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-05-13
本文作者:阿裡巴巴雲原生
本文來自:“
掘金”,了解相關資訊可以關注“掘金”