DataFlux是上海駐雲自研發的一套大資料統一分析平台,可以通過對任何來源、類型、規模的實時資料進行監控、分析和處理,釋放資料價值。
DataFlux中有多種圖表類型,表格就是其中之一,這個圖表就是将資料以表格的形式進行展示,它具有三種模式,分别是時序模式、集合模式以及分組模式,三種模式是以三個不同次元來檢視資料,接下來讓我們看看這三種模式的差別。
建立表格
首先讓我們先從建立表格圖表開始,以下圖檔是建立表格圖表的界面:
可以看到,圖表資料的查詢支援名額選擇模式和sql模式,然後将每個查詢的資料進行合并顯示組合成一個表格圖表。預設表格圖表就是時序模式,假如我們需要切換模式,可以在設定中選擇其他模式進行切換,如下圖:

時序模式
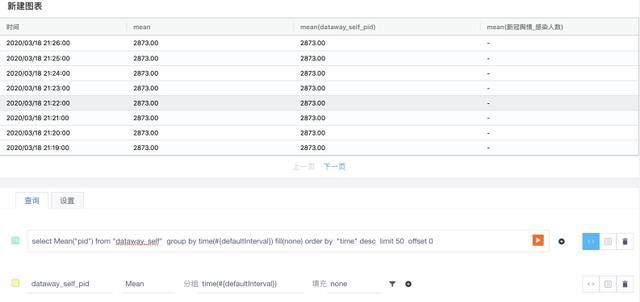
時序模式,表格圖表預設就是該模式,資料是基于時間的。在該模式下,我們多個查詢出來的資料會以時間為次元進行合并,将各個查詢傳回的資料列作為表的列名,注意,一個查詢在分組後可能傳回多個列,比如下圖的第一個查詢,根據醫院進行分組,則傳回了三個資料列:
通過上圖,我們還可以看到,第二個查詢也當做一個列放到最後,因為它沒有進行分組,是以隻有一列資料,假如它也進行了分組,那它傳回的多列也會依次放在後面。這就是我們的時序模式,在時序模式下,還有一個特性,它支援相同時間的資料顯示與合并,假如第一個查詢傳回的資料和第二個查詢傳回的資料分别如下:
這種資料的情況下,我們将通過我們的算法,将多個查詢分别當做列并根據時間進行合并,同時保留重複資料,那最終我們的得到的資料結構如下:
進而保證表格圖表資料的完整性。
聚合模式
聚合模式是我們表格圖表的第二個顯示模式,聚合模式每條查詢将會聚合成一個資料點,并與查詢名稱一同作為一條記錄顯示在表格中。如下圖:
在該模式下,每條查詢語句在名額查詢選擇的UI下最終傳回的資料點永遠隻有一個,但在SQL下,因為無法控制使用者傳回的資料結構,是以隻會去取最後一個時間序列下的最後一個資料點作為它的最終資料。在聚合模式下,分組是無效果的,即使查詢确實傳回了多個序列資料,但是最終渲染的隻有一個資料點,每個查詢将于它傳回的資料點的數字組成表格圖表的一行記錄。
分組模式
分組模式是我們表格圖表中的第三個顯示模式,該模式是通過分組名稱進行資料合并,以實作多個名額在相同分組下的資料對比。如下圖:
我們可以看到,第一個查詢和第二個查詢分别使用了“醫院”和“症狀”兩個Tag,第三個查詢雖然是直接寫的SQL,但是它還是加了一個“省份”的分組,這個時候,結果集會根據算法先将所有的Tag當成表格的資料列放到前面,然後再将每個查詢作為一個列放在Tag列的後面,友善我們在表格上可以清楚看到各個Tag進行組合後的資料對比。
在該模式下,還有一種查詢,那就是沒有Tag的查詢,那該查詢會直接當做一個資料列顯示在後面,起資料将于無Tag的列進行合并,如下圖的第二和第三個查詢:
假如查詢中有兩個查詢名額相同,并且别名也設定相同,此時在後面出現的同名列名中會标記其查詢位置“#位置”,如下圖,第二個查詢和第三個查詢别名相同,則在第三個查詢名稱前面會出現一個位置辨別:
最後,我們表格圖表在時序模式和分組模式下還支援分頁查詢,多個查詢條件隻要有一個查詢時有分頁的,這下面的分頁會顯示下一頁,但是假如某個查詢在是沒分頁的,那當我們點選分頁後,将看不到無分頁資料的查詢記錄。