一、Multi-Range Read(MRR)
1、MRR優化原理
1)在沒有使用MRR時,MySQL處理思路的僞代碼
#SQL
select * from tb where key_column=xx ;
#僞代碼
for each row r in R do
if r satisfy the where condition
then output the tuple <r>
#處理流程
1.根據索引過濾,擷取到滿足條件的記錄的結果集<r>
2.周遊結果集通過主鍵進行回表,此時為離散掃描,傳回用戶端需要的字段資訊
2)MRR算法實作僞代碼處理流程
#SQL
select * from tb where key_column=xx ;
#僞代碼
for each row r in R do
if r satisfy the where condition
then output the tuple <r> order by rowid
#處理流程
1.根據索引過濾擷取到滿足條件的記錄<r>
2.将滿足條件的記錄放至read_rnd_buffer_size,并根據rowid進行排序,得到一個有序的結果集<r> order by rowid
3.周遊結果集通過主鍵進行回表查詢,此時為順序掃描,傳回用戶端滿足條件的記錄 2、MRR的特點
1)MRR算法主要是針對基于二級索引的過濾查詢的優化,若過濾條件無索引則進行全表掃描。
2)MRR的特點就是将通過索引擷取到滿足條件的結果集(二級索引,主鍵索引)按照主鍵索引進行排序,将随機IO轉換為順序IO,進而再後續回表查詢時帶來性能上的提升。
3、MRR參數控制
mysql> show variables like 'optimizer_switch'\G
mrr=on //mrr優化,預設打開
mrr_cost_based=on //mrr基于代價評估是否使用mrr算法,預設打開。MySQL優化器CBO一般會認為mrr資源消耗較大而放棄使用mrr,若需要使用mrr,可以将該參數打開。
mysql> set optimizer_switch='mrr=on,mrr_cost_based=off'; //開啟mrr 4、示例
root@mysql57 15:39: [db2]> explain select * from sbtest1 where k<10000 ;
+----+-------------+---------+------------+-------+---------------+-------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+-------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | sbtest1 | NULL | range | idx_k | idx_k | 4 | NULL | 194 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+---------------+-------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
root@mysql57 15:39: [db2]> set session optimizer_switch='mrr=on,mrr_cost_based=off';
Query OK, 0 rows affected (0.00 sec)
root@mysql57 15:39: [db2]> explain select * from sbtest1 where k<10000 ;
+----+-------------+---------+------------+-------+---------------+-------+---------+------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+-------+---------+------+------+----------+----------------------------------+
| 1 | SIMPLE | sbtest1 | NULL | range | idx_k | idx_k | 4 | NULL | 194 | 100.00 | Using index condition; Using MRR |
+----+-------------+---------+------------+-------+---------------+-------+---------+------+------+----------+----------------------------------+
1 row in set, 1 warning (0.00 sec) 二、Simple Nested-Loop Join(SNLJ)
1、SNLJ原理
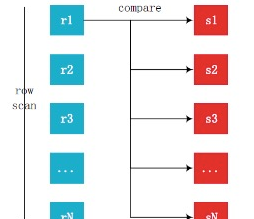
1)僞代碼
##SQL
select * from tb_r join tb_s on tb_r.r=tb_s.s
##僞代碼
for each row r in R do
for each row s in S do
if r and s satisfy the join condition
then output the tuple <r,s> 2)處理流程
1.周遊驅動表滿足條件的所有記錄
2.對于驅動表的每一行記錄,對被驅動表進行周遊,擷取到滿足join條件的所有記錄<r,s>
3.根據滿足join條件的結果集,通過主鍵回表掃描,擷取需要字段 2、SNLJ特點
1)該算法下SQL執行資源消耗最大,對于掃描次數來講,驅動表掃描1次,被驅動表掃描次數取決于驅動表記錄數(對于驅動表中每行記錄都要周遊被驅動表一次);對于SQL掃描記錄數來講,SQL執行掃描行數 = 驅動表行數 + 驅動表記錄數 * 被驅動表記錄數(笛卡爾積)
2)該算法主要是針對被驅動表關聯字段無索引的情況,但是MySQL對該情況做了優化,利用join buffer并通過BNL算法減少對被驅動表的掃描次數
3、示例
##手動關閉BNL,資料庫會使用SNLJ算法
root@mysql57 15:55: [db2]> set session optimizer_switch='block_nested_loop=off';
Query OK, 0 rows affected (0.00 sec)
root@mysql57 15:55: [db2]> explain select * from sbtest1 r join sbtest2 s on r.k=s.k;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | r | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | s | NULL | ALL | NULL | NULL | NULL | NULL | 200 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
##可以看到SQL掃描記錄數=100+100*200=20100
# Time: 2020-04-14T16:02:13.707953+08:00
# User@Host: root[root] @ localhost [] Id: 24
# Query_time: 0.007069 Lock_time: 0.000140 Rows_sent: 47 Rows_examined: 20100
SET timestamp=1586851333;
select * from sbtest1 r join sbtest2 s on r.k=s.k;
三、Index Nested-Loop Join
1、INLJ原理

1)僞代碼實作
##SQL
select * from tb_r join tb_s on tb_r.r=tb_s.s
##僞代碼
for each row r in R do
lookupr in S index
if found s == r
then output the tuple <r,s> 1.周遊滿足過濾條件的驅動表中所有的記錄
2.對于驅動表中每一條記錄,通過索引進行關聯查詢,找到所有滿足join條件的記錄<r,s>
3.周遊結果集,通過主鍵回表掃描,擷取需要的字段資訊 2、INLJ特點
1)該算法主要針對被驅動表關聯列有索引的情況
2)該算法基本上是MySQL在進行表關聯時使用最多的算法,對SQL的掃描資料來講,驅動表掃描次數為1,被驅動表掃描次數為0;對于SQL的掃描記錄數來講,SQL執行掃描行數 = 驅動表記錄數 + 驅動表的記錄 * 索引關聯滿足條件記錄數
##對于驅動表關聯字段有索引的情況,預設使用IBLJ算法
root@mysql57 16:04: [db2]> explain select * from sbtest1 r join sbtest2 s on r.k=s.k;
+----+-------------+-------+------------+------+---------------+-------+---------+---------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------+---------+---------+------+----------+-------+
| 1 | SIMPLE | r | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | s | NULL | ref | idx_k | idx_k | 4 | db2.r.k | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------+---------+---------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
##可以看到該算法下SQL掃描記錄數=100+47(滿足join條件記錄數)
# Time: 2020-04-14T16:05:29.890558+08:00
# User@Host: root[root] @ localhost [] Id: 24
# Query_time: 0.000714 Lock_time: 0.000144 Rows_sent: 47 Rows_examined: 147
SET timestamp=1586851529;
select * from sbtest1 r join sbtest2 s on r.k=s.k;
四、Block Nested-Loop Join(BNL)
1、BNL原理
##SQL
select * from tb_r join tb_s on tb_r.r=tb_s.s
##僞代碼
for each tuple r in R do
store used columns as p from R in join buffer
for each tuple s in S do
if p and s satisfy the join condition
then output the tuple <p,s> 1.周遊滿足過濾條件的驅動表中所有的記錄(SQL查詢的所有字段),并放入至join buffer
2.若所有驅動表滿足條件記錄放入join buffer,周遊被驅動表所有記錄,擷取滿足join條件的記錄結果集
3.若join buffer無法一次性存儲全部驅動表記錄,可分批讀取記錄至join buff,重複2步驟 2、BNL特點
1)BNL主要是針對被驅動表關聯字段無索引時的優化,如果我們在執行計劃中看到“Using join buffer (Block Nested Loop)”說明被驅動表表表關聯字段缺少索引或索引失效無法有效利用索引。
2)該算法是對SNLJ算法的優化,并且可将該算法BNL提升至INLJ進行優化。對SQL的掃描資料來講,驅動表掃描次數為1,被驅動表掃描次數為 驅動表記錄大小 / join_buffer_size ;對于SQL的掃描記錄數來講,SQL執行掃描行數 = 驅動表記錄數 + (驅動表記錄/join_buffer_size) * 被驅動表記錄數
3)在一定的程度上,提高join_buffer_size的大小是可以提高使用BNL算法SQL的執行效率,但是join_buffer_size是會話連接配接上去就會提前進行配置設定的,若SQL為N個表join,那其配置設定的join buffer大小為 join_buffer_size * (N-1),是以生産環境中我們不可對該參數設定過大。
3、相關參數
mysql> show variables like 'optimizer_switch'\G
block_nested_loop=on //BNL優化,預設打開
mysql> set optimizer_switch='block_nested_loop=on'; //開啟BNL ##打開BNL算法
root@mysql57 16:07: [db2]> set session optimizer_switch='block_nested_loop=on';
Query OK, 0 rows affected (0.00 sec)
##可以看到執行計劃中使用了BNL算法
root@mysql57 16:07: [db2]> explain select * from sbtest1 r join sbtest2 s on r.k=s.k;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | r | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | s | NULL | ALL | NULL | NULL | NULL | NULL | 200 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
##該算法下SQL掃描記錄數=100+1*200
# Time: 2020-04-14T16:08:33.345173+08:00
# User@Host: root[root] @ localhost [] Id: 24
# Query_time: 0.002777 Lock_time: 0.000144 Rows_sent: 47 Rows_examined: 300
SET timestamp=1586851713;
select * from sbtest1 r join sbtest2 s on r.k=s.k;
##手動調整join_buffer_size的大小
root@mysql57 16:08: [db2]> show variables like '%join_buffer_size%';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.00 sec)
root@mysql57 16:11: [db2]> set session join_buffer_size=1024;
Query OK, 0 rows affected (0.00 sec)
##縮小join_buffer_size大小後,可以發現SQL掃描記錄數上漲,10100=100+5*200
# Time: 2020-04-14T16:11:33.191980+08:00
# User@Host: root[root] @ localhost [] Id: 24
# Query_time: 0.005209 Lock_time: 0.000148 Rows_sent: 47 Rows_examined: 10100
SET timestamp=1586851893;
select * from sbtest1 r join sbtest2 s on r.k=s.k; 五、Batched Key Access Join(BKA)
1、BKA原理
for each row r in R do
lookupr in S index
if found s == r
then get the tuple <r,s>
use mrr interface output the <r,s> order by rowid 1.周遊滿足過濾條件的驅動表中所有的記錄
2.對于驅動表中每一條記錄,通過索引進行關聯查詢,找到所有滿足join條件的記錄<r,s>
3.通過mrr結果對以上結果集的rowid進行排序
4.周遊結果集,通過主鍵回表掃描(順序讀),擷取需要的字段資訊 2、BKA特點
1)BKA算法是對INLJ算法的一個優化,其差別就是在擷取到滿足join條件記錄的結果集後,通過MRR接口對rowid進行排序,以保證後續的回表操作為順序讀來提高
2)BKA算法算法預設關閉。BKA算法的優化基于MRR,是以若需要打開BKA算法,需要打開MRR并關閉mrr_cost_based。
mysql> show variables like 'optimizer_switch'\G
batched_key_access=off //BKA優化,預設關閉
mysql> set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on'; //開啟BKA root@mysql57 16:19: [db2]> set session optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
Query OK, 0 rows affected (0.00 sec)
root@mysql57 16:19: [db2]> explain select * from sbtest1 r join sbtest2 s on r.k=s.k;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | r | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | s | NULL | ALL | NULL | NULL | NULL | NULL | 200 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
root@mysql57 16:20: [db2]> alter table sbtest2 add index idx_k(k);
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
root@mysql57 16:20: [db2]> explain select * from sbtest1 r join sbtest2 s on r.k=s.k;
+----+-------------+-------+------------+------+---------------+-------+---------+---------+------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------+---------+---------+------+----------+----------------------------------------+
| 1 | SIMPLE | r | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | s | NULL | ref | idx_k | idx_k | 4 | db2.r.k | 1 | 100.00 | Using join buffer (Batched Key Access) |
+----+-------------+-------+------------+------+---------------+-------+---------+---------+------+----------+----------------------------------------+
2 rows in set, 1 warning (0.00 sec)
##BKA算法是對INLJ算法的優化,其SQL掃描記錄數隻是驅動表的記錄數?
# Time: 2020-04-14T16:20:49.212383+08:00
# User@Host: root[root] @ localhost [] Id: 24
# Query_time: 0.000680 Lock_time: 0.000145 Rows_sent: 47 Rows_examined: 100
SET timestamp=1586852449;
select * from sbtest1 r join sbtest2 s on r.k=s.k; 六、Hashjoin
Hashjoin從MySQL8.0.18後才開始支援,M一SQL 8.0.18之前隻支援NLP相關的算法。Hashjoin主要是針對表關聯字段無有效索引可利用時進行的一種優化算法。
1、In-Memory Join(CHJ)原理及特點
1)建構階段,周遊驅動表,以join條件為key,查詢需要的列作為value建立hash表。
2)探測階段,根據驅動表建構出來的hash表,對被驅動表的關聯列進行周遊,并計算關聯列的hash值判斷是否滿足join條件,擷取到滿足條件的所有記錄的結果集
3)CHJ主要适用于被驅動表關聯字段無索引,切驅動表可一次性讀取到join_buffer_size的情況,該情況下隻需要對驅動表掃描1次,被驅動表掃描1次。
2、On-Disk Hash Join原理及特點
1)如果驅動表的記錄無法一次性存儲到join_buffer_size中,建構階段會首先利用hash算将驅動表進行分區,并産生臨時分片寫到磁盤上;
2)在探測階段,對被驅動表使用同樣的hash算法進行分區,保證相同的分區中,驅動表和被驅動表滿足表關聯的等值條件的情況下,其hash算法将其配置設定到相同的分區中。
3)On-Disk Hash Join是基于CHJ,對join_buffer_size無法滿足一次性存儲所有的驅動表記錄情況下的優化
4)當驅動表記錄超過記憶體時,MySQL通過hash算法對其進行分區處理,若分區後部分分區資料仍然超出join_buffer_size的大小,則MySQL會分批次讀取該分區的記錄,每次處理完後清理hash表,重複以上操作直到處理完所有分區資料。
5)該算法下驅動表掃描次數為1,被驅動表掃描次數與hash算法分區個數以及每個分區下驅動表記錄大小/join_buffer_size個數相關,驅動表資料越大其被驅動表掃描次數越多
## MySQL 8.0.19預設開啟hashjoin,可以使用explain format=tree檢視SQL執行計劃
root@mysql57 17:16: [db2]> explain format=tree select * from sbtest1 r join sbtest2 s on r.k=s.k;
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Inner hash join (s.k = r.k) (cost=9661.47 rows=2000)
-> Table scan on s (cost=76.21 rows=200)
-> Hash
-> Table scan on r (cost=42.50 rows=100)
|
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
##可以看到hashjoin算法下,SQL掃描記錄數為100+1*200,該算法相對于SNLJ和BNL都有所提高
# Time: 2020-04-14T17:16:34.857120+08:00
# User@Host: root[root] @ localhost [] Id: 17
# Query_time: 0.001235 Lock_time: 0.000206 Rows_sent: 47 Rows_examined: 300
SET timestamp=1586855794;
select * from sbtest1 r join sbtest2 s on r.k=s.k; 文章參考:
姜承堯大佬公衆号:https://mp.weixin.qq.com/s?__biz=MjM5MjIxNDA4NA==&mid=205923864&idx=1&sn=63b97a02def11c3e4fceb67d25c79628&scene=21#wechat_redirect
【mysql】關于ICP、MRR、BKA等特性:https://www.cnblogs.com/chenpingzhao/p/6720531.html
MySQL8.0 新特性 Hash Join:https://www.cnblogs.com/cchust/p/11961851.html