本次給大家介紹兩個實用的函數:時序補點函數、異常對比函數;
一、時序補點函數
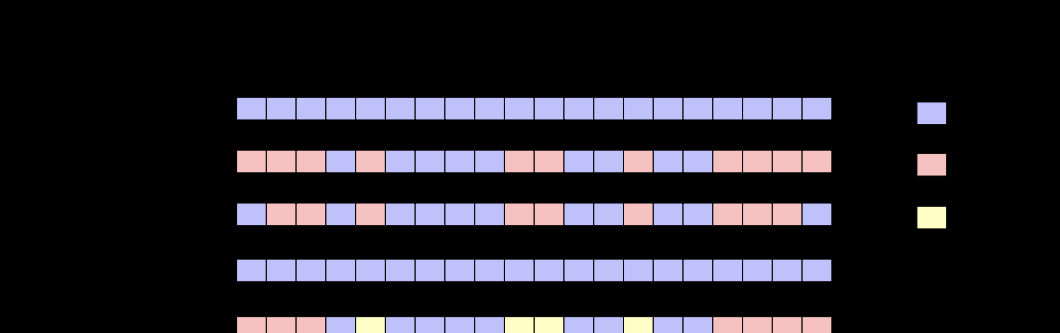

- 上圖的中的名額說明
- 日志事件事件 T0 :日志産生的最早事件
- 日志事件事件 T1 :日志産生的最晚事件
- 實際點資料:在某個時刻有确定的資料
- 缺失點資料:在某個時刻缺失資料點
- 補點資料:在不同算法執行結果中,補出的資料
1. time_series
- 函數的使用說明文檔: https://help.aliyun.com/document_detail/63451.html
- 說明:該函數必須和group by time order by time 一起使用,且order by不支援desc排序方式
- 資料補全的時間範圍是:使用者查詢的時間窗
2. series_padding
- https://help.aliyun.com/document_detail/160983.html
- 說明:該函數是将缺失的内部點資料按照一定的政策進行補點;支援group by模式
二、版本對比函數
2. 使用場景
2.1 某個服務更新
- 該場景可以總結為是單個觀測對象,在比較更新前後某個觀測名額的變化異常情況
- 需要提供的資料如下:
- 某個名額的時序觀測資料
- 某服務變更時的時間點
例子如下:某個服務複雜在某個叢集做了一次變更,變更時間是 2020-04-20 07:59:00,在這個時間點後,我們發現該叢集的請求延時升高很多,相關研發同學也許就要緊急處理。那麼是否有辦法可以通過一個函數自動的幫我幫我判别變更前後,觀測對象的名額是否發生變化。
- 先通過SQL整理出觀察資料,觀察出設定的異常點數值
* |
SELECT date_trunc('minute', __time__ - __time__ % 60) AS TIME,
avg(Latency) AS Latency
FROM log
GROUP BY TIME
ORDER BY TIME
LIMIT 10000 我們使用對應的函數進行檢測:
* |
SELECT anomaly_compare(TIME, array[ Latency ], 1587340740, 60)
FROM
(SELECT __time__ - __time__ % 60 AS TIME,
avg(Latency) / 1000.0 AS Latency
FROM log
GROUP BY TIME
ORDER BY TIME) {
"results": [{
"attribute": "column_0",
"score": 0.9999840724556095,
"details": {
"left": [{
"key": "mean",
"value": 248.79610181477835
}, {
"key": "std",
"value": 41.9981113960846
}, {
"key": "median",
"value": 236.34852017385737
}, {
"key": "variance",
"value": 1763.8413608379317
}],
"right": [{
"key": "mean",
"value": 294.9041720361495
}, {
"key": "std",
"value": 47.074409675083004
}, {
"key": "median",
"value": 299.6439639513877
}, {
"key": "variance",
"value": 2216.0000462575485
}]
}
}]
} 2.2 灰階釋出更新
- 該場景可以總結為在叢集中灰階服務時,觀察不通灰階對象之間的異常差别
-
- 可以标示具體機器的釋出狀态的标簽字段
-
相同觀測名額
例子如下:某基礎的存儲服務在做版本更新時,往往會進行逐漸的灰階操作,在選擇幾台機器先進行灰階,然後觀察後在進行整體的更新釋出,在做這個操作前是需要将對釋出機器的名額狀态做相關的判别,确定是否已經符合預期?是否同其它相同服務的機器的名額有較大差異?或者是否這個版本線上上是有有明顯的性能提升?
這時我們把問題轉換成部分的觀測對象之間的相同觀測名額資料之間的比較問題。
- 針對這個場景,我們先想資料進行達标(這裡我模拟一個打标的場景,通過請求延時的大小來确定标簽)
* |
SELECT date_trunc('minute', __time__ - __time__ % 60) AS TIME,
avg(Latency) / 100000.0 AS Latency,
label
FROM
(SELECT __time__,
Latency,
CASE
WHEN Latency > 1500000.0 THEN 1
ELSE 0
END AS label
FROM log)
GROUP BY TIME,
label
ORDER BY TIME
LIMIT 10000 * |
SELECT anomaly_compare(TIME, array[ Latency ], array[ 'Latency' ], label)
FROM
(SELECT __time__ - __time__ % 60 AS TIME,
avg(Latency) / 100000.0 AS Latency,
label
FROM
(SELECT __time__,
Latency,
CASE
WHEN Latency > 1500000.0 THEN 1
ELSE 0
END AS label
FROM log)
GROUP BY TIME,
label
ORDER BY TIME) {
"results": [{
"attribute": "Latency",
"score": 0.981385450748068,
"details": {
"left": [{
"key": "mean",
"value": 2.083975172731342
}, {
"key": "std",
"value": 0.26912348059219504
}, {
"key": "median",
"value": 2.0386681871982004
}, {
"key": "variance",
"value": 0.07242744780605757
}],
"right": [{
"key": "mean",
"value": 36.19678922429
}, {
"key": "std",
"value": 6.139164754357247
}, {
"key": "median",
"value": 37.03196953882403
}, {
"key": "variance",
"value": 37.68934388114228
}]
}
}]
}