presto資源管理介紹
oomKiller
presto會監控sql整個生命周期資源的使用(mem,cpu),worker也會周期性彙報自身mem使用狀況,當worker的free memory降為0及以下時,觸發叢集oom邏輯。
- 正常場景下,ClusterMemoryManger也會周期性檢查query 記憶體使用量,如果超過2TB,直接殺死。
- oom場景下,lowMemoryKiller 會選擇記憶體使用量最大的query,然後将其殺死。
資源組(resource-group)
可按使用者劃分資源組,可簡化模型,一個組管理一個使用者所有查詢。 每個 Group 可以自定義了三項資料
- CpuQuota:使用cpu時間片配額,分軟硬限
- MemoryQuota:使用記憶體配額,僅有硬限。
- query并發數:一個組可以并發執行查詢個數。
從三個次元限制一個 Group 的最大資源使用量, 同時可以配置一系列的選擇器, 每個選擇器可以根據請求上下文比如使用者名, 來源,用戶端tag等資訊唯一确定歸屬于某個 Group, 是以該架構其實是具備提供多租戶隔離的能力的.
示例配置
https://prestodb.io/docs/current/admin/resource-groups.html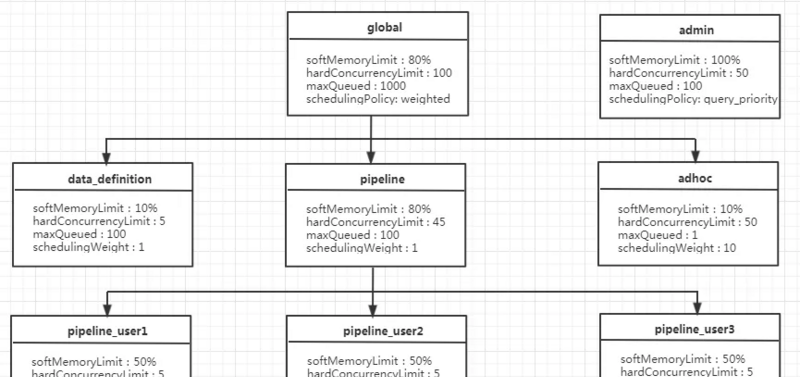
執行主要流程:
- 先判斷query屬于哪個資源組
- 看看目前組有沒有quota執行該query,有直接運作,沒有則塞入隊列,等待資源。
- 執行的query周期性彙報資源使用情況,資源組更新quota,減去已使用部分。當quota減為0了,新進入的查詢隻能進入等待隊列,等待有quota了,被manager排程執行。該資源組處于封禁狀态,等待query執行完解禁。
- mananger輪詢有quota的組,排程組裡面處于隊列中的query。
公平排程
sql排程層面
預設情況下manager采用round-robin公平排程group,當然你也可以配置權重,讓一些group得到更多的排程機會。group内部采用fifo方式排程query。group資源如果超阈了,短時間會封禁,不再繼續發起query執行,直到先前query執行完。
task執行層面
Presto在每個Worker節點上排程許多并發任務,以實作多租戶,并且使用了一個協作的多任務處理模型。任意給定的split隻能在一個線程上最多運作1秒鐘,之後必須放棄該線程并傳回隊列中。當輸出緩存已滿(下遊階段無法足夠快地消耗資料),輸入緩存為空(上遊階段可能無法足夠快地生成資料),或系統記憶體不足時,本地排程器會在目前任務CPU運作時間(指運作1秒中)到達之前切換到另一個任務。這樣釋放了那些正在處理split的線程,幫助Presto最大限度的利用CPU,進而适應不同的查詢。
當一個split放棄目前的線程時,查詢引擎會确定一下個要被執行的task(與一個或多個split相關聯)。Presto并沒有提前預測完成一個新的查詢所需的資源,而隻是使用任務的總CPU時間,将一個多級優先隊列劃分成五個層級。随着task累積的CPU時間越來越多,它将被劃分到更高的級别。每個級别都指定了一個可配置的CPU時間。在實際應用中,要在任意負載下公平的協調多任務的處理是相當有挑戰性的。不同的split使用的IO和CPU的差異性相當的大,即便在相同的任務中也是如此,而複雜的函數(如正規表達式)相對于其他的split可能會消耗更多的線程時間。而某些Connector不提供異步的API,是以有的工作線程會被保留數分鐘。
在處理這些限制條件時,排程程式必須是自适應的。系統提供了低成本的信号量,是以在一個operator中可以暫停長時間的運算。如果operator中的停止時間超過特定的值,排程器會将實際的線程時間計入目前task,并且會暫時調低這個任務将來的執行頻率。這種自适應的特性允許我們在Interactive Analytics 以及Batch ETL的案例中處理不同類型的查詢,其中presto可以為消耗最低資源的查詢提供更高的優先級。我們也可以這樣來了解,使用者隻希望低成本的查詢可以被快速執行,而不必擔心高成本的查詢的運轉時間。同時運作更多的查詢,即使以犧牲更多上下文切換為代價,也可以減少總的排隊時間,因為低成本的查詢會被快速的執行并退出。
資源隔離
無資源隔離,worker上的TaskExecutor線程被每個task共享使用。從task視角,底層線程都是共用的,做不到實體意義上的隔離。
結論及潛在問題
資源管理三個核心問題
- 避免過度配置設定:
- presto沒有cbo,無法預估一個查詢資源使用情況,沒法避免過度配置設定
- 資源隔離:一個worker上的任務可能會争奪資源并而互相幹擾。如何互相間互不幹擾至關重要。
- presto共享任務線程模式,無法真正意義上做到資源隔離
- 排程不同的負載:不同使用者對DLA使用情況不盡相同,query有大有小,如何讓不同負載使用者查詢得到公平排程。
- 使用一個使用者一個資源組模式,query能得到公平排程,基本不存在大查詢餓死小查詢問題
- 當大家共用一個全局資源組,查詢是fifo方式排程,查詢多的使用者是會餓死小使用者。
潛在問題
- presto的資源組管理是一個前置quota檢查,執行前無法判斷其資源使用情況。放行後,可能是大query,資源不夠,這屬于過度配置設定問題。
- 隻在請求送出階段做了隔離, 且沒有預估請求的資源使用量. 即隻考慮請求所屬 Group 目前的資源占用量是否超限, 未超限則放行, 不考慮放行後未來執行過程中資源使用是否會超限
- cpu使用是延時回報, 是在請求結束後再回報 CPU 使用, 但增加 CPU 資源是實時的
- 叢集資源使用率問題
- 一個使用者對應資源組quota是硬配,不可動态調整,容易導緻叢集資源使用率低。
- 如果每個資源組quota配額都很高,超出叢集負載,超頻排程SQL執行,導緻oomkiller頻繁殺大sql。
![龍珠訓練營task04[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)