雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
DAS 是信也科技自研的資料庫通路架構。它包括資料庫控制台 das console,資料庫用戶端 das client 和資料庫服務端 das server 三部分。DAS 是基于 Java 語言開發的,支援資料庫管理,ORM,SQL 建立,分庫分表操作的一體化資料庫通路解決方案。
DAS 項目從去年開始已經在 GitHub 上開源:
https://github.com/ppdaicorp/das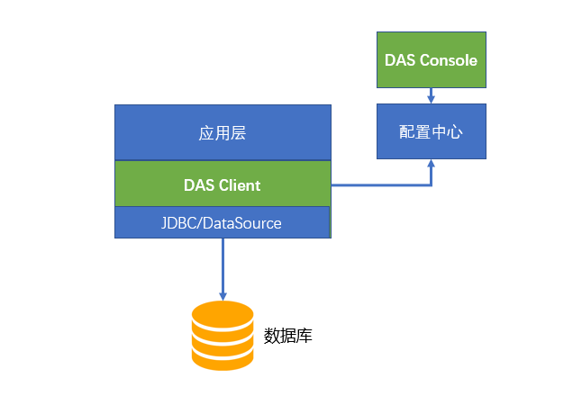
信也科技的應用大量使用 DAS 作為資料庫通路中間件,目前幾百個應用接入了 DAS。
作為公司的标準資料庫通路技術,DAS 上線以來一直運作穩定。作為 DAS 團隊,我們在接入的衆多應用實戰中積累了不少資料庫通路相關的經驗。
雖然我們這裡分享的是 DAS 的真實技術支援的案例,但是我認為它的經過和結果對類似的情景仍舊很有借鑒的意義。
問題背景
去年公司有一個使用了 DAS 的對接外部系統的應用,應用開發人員反映系統會時不時地發生資料庫慢查詢。我們通過日志系統發現這些慢查詢發生的比率極低,甚至低于千分之一。
如果這是個普通的應用,低于千分之一的慢查詢比率是可以接受的。但是這一個對接外部系統的應用,外部系統對延時要求非常高,即使千分之一的高延遲仍舊不滿足需求。
問題定位
首先,我們聯系了 DBA,從資料庫日志角度檢視是資料庫端是否有慢查詢發生。DBA 團隊在 MySQL 上面有專門記錄慢查詢的日志。慢查詢的日志結果是否定的,而且資料庫的資料量也在合理的水準。如果資料庫端沒有發生慢查詢,那一定是整個鍊路其他地方發生了延時,随後我們把精力回到應用端。
通過研究日志,我們發現了和直覺相反的現象:延時沒有發生在資料庫操作頻率比較高的操作上,而是發生在一些操作頻率很低的操作上。
問題很可能和程式狀态變遷有關。在應用端,DAS 本身是一個無狀态的架構,它主要依賴于無狀态的 JDBC 和 DataSource。DataSource 是典型有狀态的程式,是以問題發生在 DataSource 的可能性最大。
DataSource 的本質是為了節省程式的時間和空間,對資料庫連接配接做的緩存。它的設計思路和其他軟體緩存的設計思路是一樣的:要把執行個體放到緩存池管理,隻不過這裡的執行個體是資料庫連接配接。每種資料庫緩存池都有一系列的配置參數,它們都是用來調節緩存池的行為,通過不同的參數配置就能為不同的場景服務。
通過分析 DataSource 的配置,我們找到了原因。原因是由于資料庫資料庫兩次操作間隔空閑時間太長,導緻連接配接池裡所有的 idle 連接配接被清空。後續新連接配接需要建立實體連接配接,每次建立實體連接配接,需要建立 socket 以及資料庫的安全認證這些費時操作。
既然問題定位在 DataSource 對 idle 連接配接的行為上,那麼我們就從 idle 的配置着手。DAS 使用 Tomcat 的 DataSource 擷取資料庫連接配接執行個體。Tomcat 的資料源提供了有很多的配置參數,這些參數決定了資料源的行為。
我們最後把參數定位在 minIdle 這個參數上。從 Tomcat 官方文檔上這樣解釋這個參數:
The minimum number of established connections that should be kept in the pool at all times.
如果把資料源看做一個緩存,那麼 minIdle 就是這個緩存的 minimum pool size。當時我們這個 minIdle 參數設定的是 0,設定成 0 的目的在于節省資料庫連接配接。資料庫連接配接是一種寶貴的資源,一個程式保持 idle 的連接配接太多不釋放是一種浪費,對資料庫這個共享的資源更是浪費,一個資料庫往往同時被多個應用共同使用。
DBA 會設定每個資料庫的最大連接配接數(max_connections)用以保護資料庫不被請求壓垮。當一個應用占據過多 idle 的連接配接,勢必會影響其他應用的連接配接擷取。
當 minIdle 參數設定成 0,固然節約連接配接,但是它在極端情況下可能産生效果就是:當連接配接池中的連接配接長久不用時,連接配接池内所有 idle 連接配接全部被清空。Tomcat 資料源會在背景定時啟一個線程清理 idle 的連接配接,将 idle 的連接配接數降到 minIdle。
在設定成 0 之後,相當于連接配接池會被清空,于是後續第一個連接配接就需要建立真正的實體資料庫連接配接,導緻耗時飙高。在這個案例中,就是發生了這個情況。
解決方案
我們将參數 minIdle 從 0 改為 1,這樣一來連接配接池中至少有一個連接配接可以被複用,而且保持一個 idle 連接配接也不算浪費。同時,我們通過增大了 minEvictableIdleTimeMillis 的參數把連接配接池中 idle 連接配接的最小空閑時間從 30 秒增大到 10 分鐘。這樣的話,位于緩存池裡的 idle 連接配接生命周期延長了,池子裡的 idle 數變多,增加了緩存命中率。需要注意的是 minEvictableIdleTimeMillis 這個參數控制的是 evict 掉緩存池裡大于 minIdle 數的連接配接,在 minIdle 範圍裡面的連接配接是不會被它 evict 的。
是不是完美解決問題?不,故事未完。
遇到新問題
當我們在測試的時候發現,程式會報異常:
Caused by:
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException:
The last packet successfully received from the server was 9,969,393 milliseconds ago.
這是由 minIdle 設定為 1 造成的。通過調查發現,這是由于 MySQL 伺服器有一個 wait_timeout 的參數,預設是 8 小時。這也是一個保護 MySQL 資料庫自我節省資源的行為。我們的資料庫設定的 30 分鐘,是也就是說一個連接配接空閑超過 30 分鐘,MySQL 伺服器将主動斷開該連接配接。例子中的 9,969,393 毫秒相當于好幾個小時,遠超 30 分鐘,是以導緻了這種異常。這時應用從 DataSource 取連接配接的話,取到的就是那個失效的連接配接。minIdle 設定成 1 以後,那個長時間 idle 的連接配接就一直呆在連接配接池裡面,甚至被 MySQL 伺服器端斷掉。
那加大 wait_timeout?加大 wait_timeout 是不符合 DBA 規範。怎麼辦?Tomcat 資料源提供了另一個有用的參數 testOnBorrow,官方文檔上這樣解釋這個參數:
The indication of whether objects will be validated before being borrowed from the pool.
If the object fails to validate, it will be dropped from the pool, and we will attempt to borrow another.
如果把這個預設 false 值變為 true 之後,連接配接池會把連接配接從連接配接池拿出的時候會做驗證連接配接有效性。這樣就保證了從池裡出來都是有效的連接配接。
驗證與上線
最後,我們在本地開發環境驗證了解決這個連接配接逾時的方案。首先,先把本地測試 MySQL 伺服器的 wait_timeout 的參數調低便于模拟逾時,然後通過代碼邏輯控制,将兩次通路資料庫的時間間隔超過 wait_timeout 參數時間,觀察資料源在這種場景下的表現。在兩個不同的資料源配置測試條件下,觀察兩次程式的結果。
本地驗證成功之後,為了避免修改配置之後引發新的問題,我們首先進行了 JUnit 單元回歸測試,保證基本功能完整。通過這幾百個 JUnit 單元測試之後,把新配置部署到正式的測試環境進行觀察。确認測試環境運作正常以後,最後才把配置更新到預發和生産環境。正規完善的流程是軟體品質的保證。
至此,完美解決了這個問題。
其他資料源?
有人會問如果我沒用 Tomcat 的資料源,用的是其他的資料源實作該如何做呢?
對于一個成熟的資料源産品來說,Idle connection handling 和 Validation 都是必有的功能。市面上大部分主流的資料源産品都有這些類似的參數。
譬如說流行的 Druid 和 DBCP2,他們也都有一模一樣的 minIdle,minEvictableIdleTimeMillis 和 testOnBorrow 配置項。HikariCP 的類似配置項是 minimumIdle 和 idleTimeout。
感悟與總結
解決這個延時突高的問題,隻是我們中間件團隊衆多日常技術支援的一個案例。
我們中間件團隊和其他技術團隊相比有特别之處,在于需要服務于公司各種不同的業務線和技術線。我們的使用者有着不同的需求和特性,應用場景不同,技術要求也不同,也就會産生各種各樣的問題。有對并發要求高的,有對延時要求高的,有對 API 易用性要求高的,有對監控資料要求高的,等等。
雖然遇到故障和問題各色各樣,但是我們還是從這些實戰中總結出一些共性的地方。我們可以把解決問題的過程總結為:反複地假設問題和論證,最後定位解決問題的過程。拿這個案例來說,起初使用者來找到我們報問題的時候,我們也一頭霧水:為啥低并發的延時比高并發還高?起初,因為沒有明确的懷疑點,是以我們将鍊路上的每一點都檢查了一下。從資料庫到網絡,甚至咨詢了做監控的同學,以确認延時時間的正确性。通過反複調查,我們才将問題定位在用戶端。
在排查問題的過程中,好的監控起到了關鍵作用。一般監控有兩類輸出:警告和日志。應用團隊就是通過警告及時發現了問題,而我們中間件團隊利用日志排查問題。日志的品質往往決定了定位問題的效率。好的監控能夠提高你從表面現象到找到背後原因(從 what 到 why)的效率。
在這個解決這個延時突高的案例上,我們也是從日志上得到蛛絲馬迹。DAS 本身會打詳細的日志,通過這些日志,我們可以看到 DAS 的代碼和它底層 JDBC 消耗的時間,進而定位耗時發生在 DAS 的更底層。我們還有個集中式日志系統,能在上面看到異常日志的原始資訊,也可以在這個系統上面看各種次元的統計資料,譬如說,對這個案例至關重要的 999 線和 QPS。如果我們沒有這些資訊,我懷疑還能不能定位這個問題。
希望我們的這次排查問題的經曆經過對大家有所幫助!
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/zhibo立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-03-27
本文作者:盧聲遠,赫傑輝
本文來自:“
InfoQ”,了解相關資訊可以關注“
”
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)