雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
對于創業公司來說,有使用者注冊是好事情,但是當使用者從零擴充到成千上萬之後,Web 應用程式又該如何支援呢?
通常來說,這種情況的解決方案要麼是來自突然爆發的緊急事件,要麼是系統出現瓶頸進行更新改造。雖然方式不同,但是我們也發現了,一個邊緣項目發展成高度可擴充項目,其更新方案是有一些普适的“公式”可以套用,本文以 Graminsta 為例,為大家介紹當使用者從 1 位發展到 10 萬,應用程式如何擴充?
1 位使用者:1 台機器
無論是網站還是移動應用,應用程式幾乎都包括這三個關鍵元件:API、資料庫和用戶端,其中資料庫用來存儲持久資料,API 服務于資料及與其有關的請求,而用戶端負責将資料呈現給使用者。
在現代應用程式開發中,用戶端往往會被視為一個獨立于 API 的實體,這樣一來就可以更輕松地擴充應用程式了。
當剛開始建構應用程式時,可以讓這三個元件都運作在一個伺服器上,類似于我們的開發環境,一位工程師在同一台計算機上運作資料庫、API 和用戶端。
當然,理論上我們可以把它部署到雲上的單個 DigitalOcean Droplet 或 AWS EC2 執行個體上,如下所示:
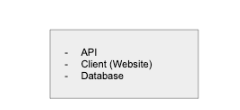
但是,當我們的使用者未來不止 1 個的時候,其實剛開始就應該考慮是否要将資料層拆分出來。
10 個使用者:拆分資料層
拆分資料層,并将其作為一個類似于 Amazon 的 RDS 或 Digital Ocean 的托管資料庫的托管服務。這樣做的話,雖然成本會比在一台機器上或 EC2 執行個體上自托管高一些,但是我們可以獲得很多現成且友善的東西,例如多區域備援、隻讀副本、自動備份等等。
Graminsta 現在的系統如下所示:

100 個使用者:拆分用戶端
當網站流量變得穩定之後,就到了拆分用戶端的時候了。
需要注意的是,拆分實體是建構可擴充應用程式的關鍵所在。當系統中的某一部分獲得了更多流量,那麼就應該把它拆分出來,根據其自身的特定流量模式來處理服務的擴充。這也是我會把用戶端和 API 看作是互相獨立的元件的原因,這樣,我們就可以輕松為多平台建構産品,例如 web、移動 web、iOS、Android、桌面應用、第三方服務等,它們都是使用相同 API 的用戶端。
現在,Graminsta 的系統如下所示:
1000 個使用者:負載均衡器
當新使用者越來越多,如果隻有一個 API 執行個體可能滿意滿足所有的流量,這時我們需要更多的計算能力。
這時,負載均衡器該上場了,我們在 API 前面添加一個負載均衡器,它會把流量路由到該服務的一個執行個體上,我們就可以進行水準擴充(通過添加更多運作相同代碼的伺服器來增加可以處理的請求數量)。
我們在 web 端和 API 前面添加了一個獨立的負載均衡器,這意味着我們擁有了多個運作 API 和 web 用戶端代碼的執行個體。該負載均衡器會把請求路由到任何一個流量最小的執行個體上。并且,我們還可以從中得到備援,當一個執行個體當機(過載或崩潰)時,其他執行個體還可以繼續運作,響應傳入的請求,而不是整個系統當機。
負載均衡器還支援自動擴充,在流量高峰時可以增加執行個體的數量,當流量低谷時,減少執行個體數量。借助負載均衡器,API 層實際上可以無限擴充,如果請求增加,我們隻需要不斷增加執行個體就可以了。
編者注:到目前為止,我們擁有的産品和 PaaS 公司(如 Heroku 或 AWS 的 Elastic Beanstalk)提供的開箱即用産品非常類似。Heroku 把資料庫托管在單獨的主機上,用自動擴充來管理負載均衡器,并允許我們把 API 和 web 用戶端分開托管。對于早期初創企業來說,使用 Heroku 等服務來做項目是一個不錯的選擇,所有必需的、基本的東西都是開箱即用。
10000 個使用者:CDN
對于 Graminsta 來說,處理和上傳圖像為伺服器帶來了很大的負擔。是以,Graminsta 選擇了使用雲存儲服務來托管靜态内容,例如圖像、視訊等(AWS 的 S3 或 Digital Ocean 的 Spaces),而 API 應該避免圖像處理和圖像等業務。
另外,使用雲存儲服務,我們還可以使用 CDN,可以在遍布全球不同的資料中心自動緩存圖像。我們的主資料中心可能托管在
我們從雲存儲服務得到的另一樣東西是 CDN(在 AWS,這是一個被稱為 Cloudfront 的插件,但是很多雲存儲服務都以開箱即用的方式提供它)。CDN 将在遍布全球不同的資料中心自動緩存我們的圖像。
雖然我們的主資料中心可能托管在俄亥俄州,如果有人在日本對圖像發出了請求,那麼雲供應商就會進行複制,将其存儲在位于日本的資料中心,下一個請求該圖像的日本使用者就會很快收到圖像。
10 萬個使用者:擴充資料層
負載均衡器在環境中添加了 10 個 API 執行個體,使得 API 的 CPU 和記憶體消耗都很低,CDN 幫助我們解決了世界各地圖像請求的問題。但是現在,我們有一個問題需要解決,那就是請求延遲。
通過研究,我們發現資料庫 CPU 的消耗占比達到了 80%-90%,是以擴充資料層成為了當務之急。資料層的擴充是一件很棘手的事情,雖然對于服務無狀态請求的 API 伺服器來說,隻需要添加更多執行個體即可,但是對于大多數資料庫系統來說,卻不是這樣。
緩存
要從資料庫獲得更多資訊的最簡單方法之一是給系統引入一個新的元件:緩存層。實作緩存最常用的方法是使用記憶體中的鍵值存儲(如 Redis 或 Memcached),且大多數雲廠商都會提供資料庫服務的托管版本。
當該服務正在進行對資料庫相同資訊的大量重複調用時,就是緩存大顯身手的時候了。當我們通路資料庫一次時,緩存就會儲存資訊,之後再進行相同請求時,就不必再通路資料庫了。
例如,如果有人想在 Graminsta 中通路 Mavid Mobrick 的個人資料頁面時,我們把從資料庫中得到的結果,緩存在 Redis 中關鍵字 user:id 下,到期時間為 30 秒。之後,每當有人通路 Mavid Mobrick 的個人資料時,我們會首先檢視 Redis,如果存在相關資料,那就直接從 Redis 提供資料。
大多數緩存服務的另一個優點是,與資料庫相比,更容易擴充。Redis 有個内建的 Redis 叢集(Redis Cluster)模式,用的是跟負載均衡器類似的方式,可以把我們的 Redis 緩存分布到多台機器上 。
所有高度擴充的應用程式幾乎都充分利用了緩存的優勢,緩存是建構快速 API 不可或缺的部分,可以提供更好的查詢和更高效的代碼,如果沒有緩存,我們可能很難擴充到數百萬使用者的規模。
隻讀副本
由于對資料庫的通路相當多,是以我們需要在資料庫管理系統來添加隻讀副本。借助上面提到的托管服務,隻需要點選一下就可以完成。隻讀副本将和主資料庫保持一緻,并且能夠用于 SELECT 語句。
未來展望
随着應用的不斷擴充,我們會把重點放在拆分獨立擴充的服務。例如,如果我們使用了 websockets,那麼會把 websockets 處理代碼抽取出來,放在新的執行個體上,同時安裝負載均衡器。該負載均衡器可以根據 websocket 連接配接打開或關閉的數量來上下擴充,與我們收到的 HTTP 請求數量無關。
如果未來還會遇到資料層的限制,我們就會對資料庫進行分區和分片。
我們會使用 New Relic 或 Datadog 等服務安裝監控程式,并通過監控程式發現比較慢的請求,改進它。同時,随着擴充的不斷進行,我們希望能夠發現更多的瓶頸并解決它。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/zhibo立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-03-26
本文作者:Alex Perato
本文來自:“
InfoQ”,了解相關資訊可以關注“
”