Cassandra最佳實踐細節(1)常見CQL使用(1)
資料類型
CQL_TYPE包含如下幾類:
- native type;
- collection type;
- user defined type;
- tuple type;
- Custom type;
native type
| 類型 | 變量可用類型 | 描述 |
|---|---|---|
| ascii | string | ASCII 字元串 |
| bigint | integer | 64位有符号long |
| blob | 任意位元組 | |
| boolean | true、false | |
| counter | counter 列(64位有符号) | |
| date | integer、string | 日期常量類型 |
| decimal | integer、float | 可變精度小數 |
| double | 64位IEEE-754浮點 | |
| duration | duratio | 納秒精确度的持續時間 |
| float | 32位IEEE-754浮點 | |
| inet | IP位址、ipv4或者ipv6,因為沒有ip類型,是以用string作為輸入 | |
| int | 32位 有符号int | |
| smallint | 16位有符号int | |
| text | UTF-8編碼string | |
| time | 納秒精度的時間 | |
| timestamp | 毫秒時間戳 | |
| timeuuid | uuid | |
| tinyint | 8位有符号int | |
| varchar | UTF8string | |
| varint | 任意精度證書 |
使用counter
可以用來定義counter 列,這個列支援2種操作:incrementing 以及decrementing,使用限制是:
- primary key不可以包含counter 列;
- 一個表如果包含了counter,那麼就隻能包含counter,換句話說就是:如果primary key外的列要麼全是counter,要麼就沒有;
- counter列不支援過期;
- counter列支援delete,但是隻能支援delete一次;
- counter理論上是不是很理想的,如果逾時等可能影響準确性。
使用timestamp
timestamp 類型是64位的有符号的int,代表的是從1970年00:00:00以來的毫秒時間戳。在CQL裡面timestamp可以使用integer以及string表示,比如2011年3月21号 04:05:00 AM, GMT;
-
1299038700000
-
'2011-02-03 04:05+0000'
-
'2011-02-03 04:05:00+0000'
-
'2011-02-03 04:05:00.000+0000'
-
'2011-02-03T04:05+0000'
-
'2011-02-03T04:05:00+0000'
-
'2011-02-03T04:05:00.000+0000'
使用date
date類型的value 可以是string或者integer的類型,基本的表述格式:yyyy-mm-dd
使用時間類型 times
times的類型value是可以是string或者integer,它的使用格式是:hh:mm:ss[.ffffffff],舉個例子,可以如下表示一個時間:
-
'08:12:54'
-
'08:12:54.123'
-
'08:12:54.123456'
-
'08:12:54.123456789'
使用duration
duration類型的資料是由3個有符号的integer組成的,第一個表示的是month,第二個表示的是天,第三個表示的是納秒。duration的的輸入可以如下:
- 時間單元可以比如:12h30m,相關的時間單元可以如下:
- y:年(12個months)
- mo:months(1 month)
- w: weeks(7 days)
- d:days (1 day)
- h:hours(3,600,000,000,000納秒)
- m:分鐘(60,000,000,000 納秒)
- s:秒(1,000,000,000納秒)
- ms:毫秒(1000,000 納秒)
- us: 微妙(1000納秒)
- ns:納秒(1納秒)
- ISO 8601 格式:
P[n]Y[n]M[n]DT[n]H[n]M[n]S or P[n]W
- ISO 8601 可選格式:
P[YYYY]-[MM]-[DD]T[hh]:[mm]:[ss]
列子:
INSERT INTO RiderResults (rider, race, result) VALUES ('Christopher Froome', 'Tour de France', 89h4m48s);
INSERT INTO RiderResults (rider, race, result) VALUES ('BARDET Romain', 'Tour de France', PT89H8M53S);
INSERT INTO RiderResults (rider, race, result) VALUES ('QUINTANA Nairo', 'Tour de France', P0000-00-00T89:09:09); 注意 : duration的列無法做為primary key,主要原因是因為在沒有date類型保序的情況下無法将duration的相關資料進行排序;
Collection type
Cassandra 支援3種集合類型:Maps、Lists、Sets,對于使用這幾個類型有一些需要的建議如下:
- 對于一些有限的排序/denormalizing 的資料,可以使用collection,但是無限的資料不建議用這個類型存;
- 單個集合内部元素并沒有被索引,是以如果需要讀取單個集合内部的某個元素會将整個元素都讀取出來;
- 對于sets以及maps的寫操作不會引起read-before-write,但是對于list操作來說可能會存在。是以對于有的情況下的list操作并不建議,反之set之類可能更合适。
maps
map是一個以key排序的k-v對,使用方式如下:
CREATE TABLE users (
id text PRIMARY KEY,
name text,
nametoaddress map<text, text>
);
INSERT INTO users (id, name, favs)
VALUES ('id1', 'gcc', { 'xl' : 'hz', 'gc' : 'bj' });
UPDATE users SET nametoaddress = { 'xl' : 'china' } WHERE id = 'id1'; map類支援:
- update 或者insert 單個或者多個元素:
UPDATE users SET nametoaddress['gc'] = 'earth' WHERE id = 'id1';
UPDATE users SET nametoaddress = nametoaddress + { 'll' : 'sh', 'nn' : 'sz' } WHERE id = 'id1'; - 删除單個或者多個元素:
DELETE nametoaddress['xl'] FROM users WHERE id = 'id1';
UPDATE users SET nametoaddress = nametoaddress - { 'xl', 'll'} WHERE id = 'id1'; - 支援TTL操作
sets
set是有序的值排序,類似我們常見的set集合類型:
CREATE TABLE images (
name text PRIMARY KEY,
owner text,
tags set<text>
);
INSERT INTO images (name, owner, tags)
VALUES ('cat.jpg', 'gcc', { 'pet', 'cute' });
UPDATE images SET tags = { 'kitten', 'cat', 'lol' } WHERE name = 'cat.jpg'; set操作支援下面:
- 給集合添加以及删除一個或者多個元素:
UPDATE images SET tags = tags + { 'gray', 'cuddly' } WHERE name = 'cat.jpg';
UPDATE images SET tags = tags - { 'cat' } WHERE name = 'cat.jpg'; lists
list和我們常見的了解的list集合類型類似:
CREATE TABLE plays (
id text PRIMARY KEY,
game text,
players int,
scores list<int>
)
INSERT INTO plays (id, game, players, scores)
VALUES ('123-afde', 'quake', 3, [17, 4, 2]);
UPDATE plays SET scores = [ 3, 9, 4] WHERE id = '123-afde'; list支援下面操作:
- 将值添加到清單:
UPDATE plays SET players = 5, scores = scores + [ 14, 21 ] WHERE id = '123-afde';
UPDATE plays SET players = 6, scores = [ 3 ] + scores WHERE id = '123-afde'; - 設定list中某個特定位置的值:
UPDATE plays SET scores[1] = 7 WHERE id = '123-afde'; - 删除某個特定位置上的值:
DELETE scores[1] FROM plays WHERE id = '123-afde'; - 删除相關存在的值:
UPDATE plays SET scores = scores - [ 12, 21 ] WHERE id = '123-afde'; UDT (user-defined-type)
支援使用者自定義的類型,這個需要指定特定的keyspace下面進行對應的create 操作,對于udt,支援create、alter、drop等操作。
create udt
一定要在一個具體的keyspace下面使用,參考:
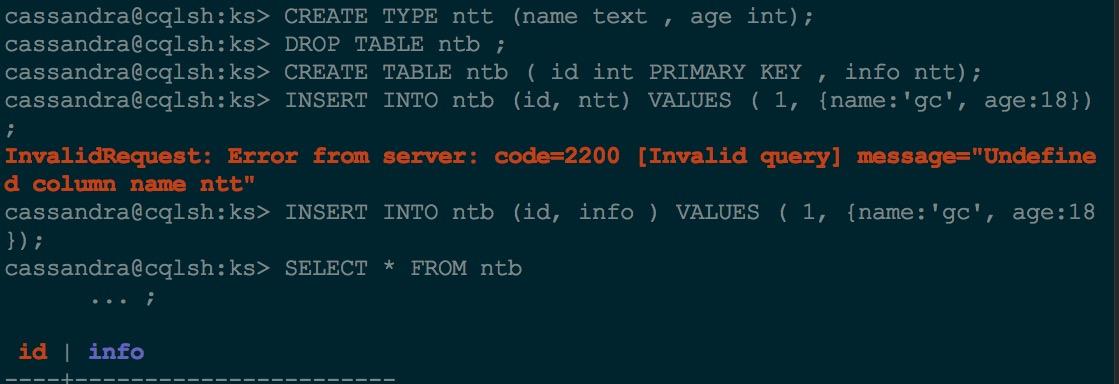
此外還支援alter以及drop操作。
注意:如果一個udt被一個具體的表使用,如果想drop這個udt,那麼需要對應的表也要drop;
tuple
使用參考下面的列子:
