最近又遇到一個資料相關的咨詢項目,為一家企業整理資料服務目錄,今天就來讨論下企業資料目錄架構和它的部署方式。
企業資料目錄(EDC)旨在幫助企業與IT人員通過統一的中繼資料視圖(包括技術中繼資料、業務中繼資料、使用者釋義、關聯關系、資料品質和用途)來釋放企業資料資産的最大能量。
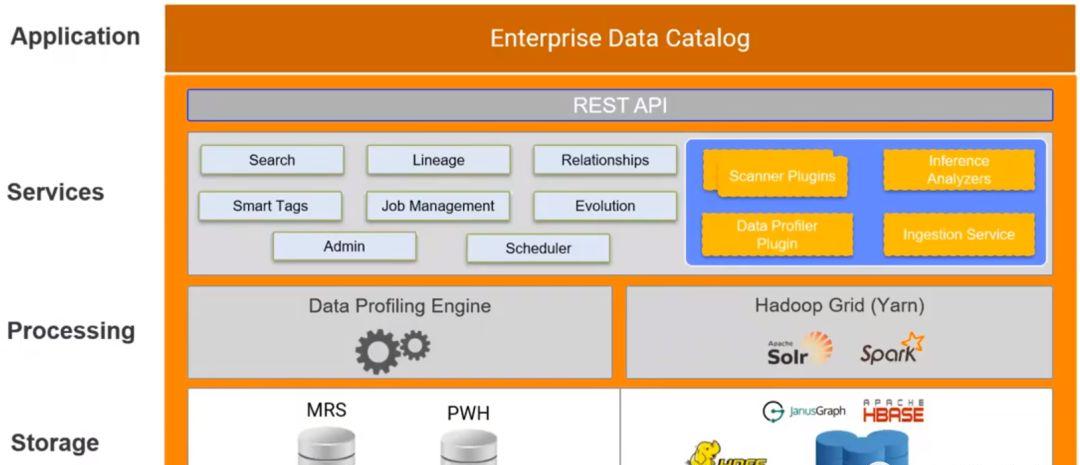
我們從下至上來看下EDC的一個架構,最下面是存儲層,在這一層,EDC包含了傳統的結構化資料庫用來存儲EDC的管理者資料、可視化配置資料、資料域的規則,runtime統計資料等等,其中一部分結構化資料來自于各接入應用的中繼資料,稱為模型庫服務(Model Repository Service,MRS)使所有接入的應用可以在一個關系型資料庫中進行協同;另一部分結構化資料稱為資料剖析倉庫(Profiling Warehouse,PWH),用來存儲資料剖析資訊,例如剖析結果和計分卡結果。在存儲層EDC也可以接入各種非結構化資料,例如Hadoop分布式存儲系統以及其上的HBASE等開源産品。
 淺談企業資料目錄
淺談企業資料目錄 往上一層,對于接入的結構化資料的資料源,有剖析引擎(Data Profiling Engine)對資料集的唯一性,特征值頻率以及資料集所屬的資料域進行分析;在另一邊Hadoop社群有自己的分布式引擎系統,例如用來快速将各類中繼資料加載到HBase的Spark元件,以及支援多條件搜尋并建立實時索引的Solr元件。
所有的資料處理都是為了能提供資料服務,最通用的不外乎搜尋,包括資料間關系、血緣的搜尋,資料域的搜尋。還有就是生成報表作業的管理計劃。除了直接對外提供服務外,這一層還有一些插件對資料進行進一步加工,例如對跨資料集的資料相似性進行比較的分析器,對資料集進行到資料域的歸集,以及将非結構化中繼資料導入到HBase的攝入服務。最終服務層有統一的對外API接口将資料域轉化成資料目錄作為EDC的主體。
EDC支援的分布式Hadoop産品包括Cloudera,Hortonworks以及Azure HDInsight,在Hadoop上,EDC可以部署自己的HBase,Solr以及Spark執行個體作為Yarn應用。不過市面上的一些EDC産品,例如Informatica有自帶的Hadoop叢集,和自身的HBase,Solr和Spark可以打包部署。
 淺談企業資料目錄
淺談企業資料目錄 EDC的資料源通常來自各業務系統、BI系統、資料庫、數倉和資料內建總線,經過存儲層的中繼資料提取及資料剖析在EDC叢集内建立中繼資料叢集、建立中繼資料處理架構(内容包括MRS,監控模型庫服務,叢集服務,目錄服務以及内容管理服務)以及資料域建制(Profiling)即資料內建服務。
淺談企業資料目錄 上圖是EDC服務的架構圖。Profiling伺服器需要連接配接PWH和通過内容管理服務關聯的參考資料庫(REF)。架構伺服器(Infrastructure Server)需要連接配接MRS資料庫,其上的EDC服務通過到Spark、HBase和Solr的連接配接器對接企業的非結構化資料;通過MRS關聯資料內建服務深入資料湖對接企業的結構化資料。MRS對外提供開發接口可對資料內建方式及作業管理進行客制化,同時通過分析服務對外輸出業務術語表(Business Glossary)。而EDC的對外接口可以給管理者提供對資料域的定義,也可以開放給使用者對業務場景進行客制化。
由于EDC牽涉到全域的資料,對于安全管控也是不可忽視的一環,在EDC中往往會通過Kerberos,即三方驗證的方法對通路進行權限控制。
淺談企業資料目錄 上面這張圖比較複雜,簡單的說即時使用者通路憑證通過一個第三方機構來保管,以保證驗證的獨立性。
淺談企業資料目錄 以Informatica為例,以上是EDC的儀表盤,點選各個圖示可以檢視具體的源資料和曆史資料。并且通過對大資料的AI分析,可以對未來趨勢做出預判。