作者:李呈祥,花名司麟,阿裡雲智能EMR團隊進階技術專家,Apache Hive Committer, Apache Flink Committer,目前主要專注于EMR産品中開源計算引擎的優化工作。
并發地向目标存儲系統寫資料是分布式任務的一個天然特性,通過在節點/程序/線程等級别的并發寫資料,充分利用叢集的磁盤和網絡帶寬,實作高容量吞吐。并發寫資料的一個主要需要解決的問題就是如何保證資料一緻性的問題,具體來說,需要解決下面列出的各個問題:
1.在分布式任務寫資料的過程中,如何保證中間資料對外不可見。
2.在分布式任務正常完成後,保證所有的結果資料同時對外可見。
3.在分布式任務失敗時,所有結果資料對外不可見且能正确清理。
4.開啟預測執行時,保證多個執行相同任務的task隻有一份結果資料在最終結果中。
此外,還要一些作業的異常情況需要處理,例如task失敗重試,作業重新開機等等。Job Committer是MapReduce用來實作分布式寫入一緻性的保證,通過Job Committer的各種實作,保證MapReduce任務在各種異常場景中資料寫出的一緻性。Spark支援MapReduce的JobCommitter,同樣也是通過JobCommitter實作Spark作業寫出資料的一緻性。
JobCommitter接口
MapReduce有V1和V2兩套API接口,在包名中以
mapred
和
mapreduce
區分,v1和v2版本的JobCommitter抽象接口基本一緻,下面以
org.apache.hadoop.mapreduce.OutputCommitter
為例介紹主要的接口定義:
| Modifier and Type | Method and Description |
|---|---|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
根據接口的調用時機和順序,我們可以大緻梳理出MapReduce任務是如何通過JobCommitter的工作機制。
1.在job初始化時,調用setupJob,進行一些作業級别的初始化工作,例如設定job的工作目錄等等。
2.如果已有相同作業正在執行,調用isCommitJobRepeatable判斷是否繼續。
3.在task初始化時,調用setupTask,進行一些作業級别的初始化工作,例如設定task工作目錄,task輸出目錄等。
4.如果task輸出已存在,通過isRecorverySupport判斷是否支援recovery,是的話,調用recoverTask,避免task的計算。
5.如果task執行失敗,調用abortTask,清理task輸出。
6.如果task執行成功,調用commitTask。
7.如果所有task都全部完成,調用commitJob。
8.如果job失敗,調用abortJob。
可以看到,JobCommitter的基本機制是基于一種類似于分布式資料庫中的兩階段送出協定的方式,task首先commit,主要的工作在task中完成,在appmaster收到所有task成功送出的資訊後,進行job commit完成最後的送出工作。通過兩階段送出協定實作資料一緻性有兩個主要的需求需要滿足:
1.在commit job以前,資料對外不可見,且可回退。
2.commit job過程要盡量短,最好是原子操作,較長的commit job過程,中間發生失敗的風險較大,一旦失敗,會導緻資料處于某種中間狀态,無法滿足資料一緻性的要求。
在MapReduce中,
FileOutputCommitter
是最常使用的一個Job Commiter實作,在寫入資料到HDFS上時,完全滿足兩階段送出協定的兩個要求。
FileOutputCommitter
下面簡單介紹
FileOutputCommitter
主要接口的一些具體實作細節。
FileOutputCommitter
主要涉及到四個目錄:
- 最終目錄:$dest/
- Job臨時目錄:$dest/_temporary/$appAttemptId/
- Task臨時目錄:$dest/_temporary/$appAttemptId/_temporary/$taskAttemptID/
- Task輸出目錄:$dest/_temporary/$appAttemptId/$taskAttemptID/
整個JobCommitter執行過程如圖所示:
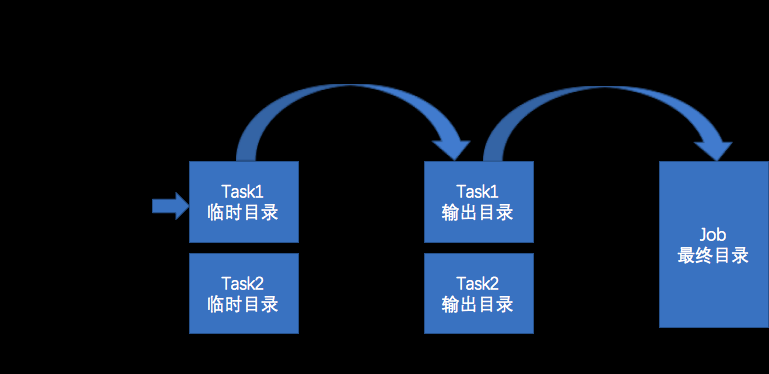
1.setupJob:設定Job臨時目錄。
2.setupTask:确定Task臨時目錄和輸出目錄。
3.commitTask:将Task臨時目錄rename到輸出目錄。
4.abortTask:清理Task臨時目錄。
5.commitJob:将Job臨時目錄中的資料(包含所有Task輸出目錄中的檔案)合并到Job最終目錄。
6.abortJob:清理Job臨時目錄。
根據以上FileOutputCommitter的實作,在可以看到,在commitJob之前,所有mapreduce任務寫的資料都在臨時目錄中,讀取Job最終目錄不會讀到臨時資料,在Job執行的任意過程失敗,清理臨時目錄檔案即可。FileOutputCommitter在Job執行的過程中,每一個産生的檔案需要進行兩次Rename操作,第一次是commitTask,在Task中執行,多個節點中執行的task可以并發地進行Rename。第二次是commitJob,MapReduce或者Spark的Job Driver端執行的,是個單點操作。在commitJob時,由于需要将Job臨時目錄中的檔案移動到最終目錄,會有一個時間視窗,在過程中失敗的話,會導緻部分資料對外可見,這個時間視窗随着檔案數量的增加也會随之增加。對于HDFS這類分布式檔案系統來說,rename是一個十分高效的操作,隻涉及到NameNode上相關中繼資料的修改,是以這個時間視窗非常小,可以滿足絕大部分場景的需求。
在對于S3,OSS等公有雲上的對象存儲系統來說,并不直接支援Rename操作,檔案系統級别的Rename操作一般會轉換成Copy+Delete操作,這個代價相對于HDFS會大大增加。commitJob是在MapReduce或者Spark的Job Driver端執行的,是個單點操作,雖然有實作線程級别的并發優化,但是在寫入S3/OSS的場景中,commitJob的時間視窗會非常長,檔案數量較大時,可能達到分鐘,甚至小時級别,這對于Job的性能會産生嚴重的影響,為了解決寫S3/OSS等對象存儲系統的性能問題,Hadoop社群引入了FileOutputCommitter V2版本。
FileOutputCommitter V2
FileOutputCommitter V2版本整個job commit的過程如下:

1.setupJob:設定Job臨時目錄。
2.setupTask:确定Task臨時目錄。
3.commitTask:将Task臨時目錄檔案rename到Job最終目錄。
4.abortTask:清理Task臨時目錄。
5.commitJob:無需Rename操作。
6.abortJob:清理Job臨時目錄。
可以看到在V2版本中,最大的差別是去掉了Task輸出目錄,在commitTask的時候将檔案直接rename到Job最終目錄,整個Job Commit過程,對于所有的檔案隻需進行一次Rename操作,而且Rename操作是在叢集節點的所有task上并發執行的,消除了Job Driver單點執行rename的瓶頸。
FileOutputCommitter V2在寫入資料到S3/OSS等場景中大大提高了性能,但是由于byPass了Task輸出目錄,無法保證資料的一緻性,在Job執行過程中,部分檔案就移動到了Job最終目錄。當部分task成功,部分task失敗時,也會在最終目錄中殘留中間檔案。
針對寫入S3/OSS等的場景,Hadoop社群和各個工業界也都提出了非常多的解決方案,基本的目标是保證資料一緻性的前提下,完全避免Rename操作。下面主要介紹S3ACommitter和JindoOssCommitter,分别是hadoop社群和阿裡雲EMR團隊針對S3和OSS實作的Job Committer,主要是基于S3/OSS的Multipart Upload特性實作,基本思想一緻,在這裡一并介紹。此外,還有Databricks基于DBIO的方案,Netflix的Staging committer方案等等,篇幅有限,這裡就不過多介紹了。
對象存儲系統的Multipart Upload
除了通過PUT Object接口上傳檔案到S3/OSS以外,S3/OSS還提供了另外一種上傳模式——Multipart Upload。主要應用在檔案較大,需要斷點上傳或者網絡不好等場景中,以OSS為例,Multipart Upload上傳的流程如下:
1.InitiateMultipartUpload:使用Multipart Upload模式傳輸資料前,必須先調用該接口來通知OSS初始化一個Multipart Upload事件。指定目标檔案位址作為參數,擷取一個uploadId用作後續upload使用。
2.UploadPart:初始化一個MultipartUpload之後,可以根據指定的Object名和Upload ID來分塊(Part)上傳資料。可重複調用uploadPart接口上傳不同的分塊資料,而且可以并發調用。
3.CompleteMultipartUpload:在将所有資料Part都上傳完成後,必須調用CompleteMultipartUpload接口來完成整個檔案的MultipartUpload。完成completeMultipartUpload後,檔案在oss上對外可見,在completeMultipartUpload傳回之前,該檔案對外不可見。
4.AbortMultipartUpload:AbortMultipartUpload接口用于終止MultipartUpload事件,在CompleteMultipartUpload之前可随時中止MultipartUpload。
5.ListMultipartUploads:ListMultipartUploads用來列舉所有執行中的Multipart Upload事件,即已經初始化但還未Complete或者Abort的Multipart Upload事件。
基于Multipart Upload的No-Rename Committer實作
通過Multipart Upload功能提供的支援,結合S3/Oss檔案系統層面的定制支援,可以實作在保證資料一緻性前提下無需Rename操作的Job Committer實作,具體的Job Commit流程如下:
1.setupJob:設定Job臨時目錄。
2.setupTask:設定Task臨時目錄,Task執行過程中寫檔案使用MultiUpload接口直接寫到Job最終目錄,在close檔案時,不調用CompleteMultipartUpload接口,将所有Upload分塊資訊記錄在Task臨時目錄的檔案中。
3.commitTask:将Task臨時目錄檔案中的多個檔案Upload分塊資訊合并成一個檔案,寫到Job臨時目錄。
4.abortTask:清理Task臨時目錄,使用AbortMultipartUpload接口,abort所有該task寫的檔案。
5.commitJob:通路Job臨時目錄中所有的Upload分塊資訊,調用CompleteMultipartUpload接口,完成所有檔案的MultipartUpload。
6.abortJob:調用ListMultipartUploads,abort所有該task寫的檔案分塊,清理Job臨時目錄。
在Task執行過程中,由于通過Multipart Upload相關接口初始化upload和上傳分塊資料,但是知道commitJob時,才會調用CompleteMultipartUpload。根據Multipart Upload特性,在調用CompleteMultipartUpload前檔案是不可見的,進而保證了資料一緻性。同FileOutputCommitter類似,由于有多個檔案需要CompleteMultipartUpload,在commitJob時也會有一個可能導緻資料不一緻的時間視窗。檔案的上傳過程都已經在task中分布式的完成了,在Job Driver中commitJob時CompleteMultipartUpload是一個非常輕量級的請求,是以這個時間視窗會非常短,失敗的可能較低,可以滿足絕大部分業務場景的需求。對比FileOutputCommitter V1,在jobCommit時,CompleteMultipartUpload相對于Rename代價小很多,可能導緻資料不一緻的時間視窗也會少很多。對比FileOutputCommitter V2,V2并不保證資料一緻性,JindoOssCommitter可以适用于更多對資料一緻性有要求的場景。
性能方面,這種方式分布式的在task中并發寫資料到OSS中,并且不需要Rename操作,對比FileOutputCommitter V1/V2分别需要的兩次和一次Rename操作,也有大幅的性能提升。
總結
通過對象存儲系統普遍提供的Multipart Upload功能,實作的No-Rename Committer在資料一緻性和性能方面相對于FileOutputCommitter V1/V2版本均有較大提升,在使用MapRedcue和Spark寫入資料到S3/Oss的場景中更加推薦使用。S3ACommitter在Hadoop社群版本的3.1.2中已經可以使用,JindoOssCommitter也在阿裡雲的EMR環境2.5.0以上版本中預設開啟。
阿裡巴巴開源大資料技術團隊成立Apache Spark中國技術社群,定期推送精彩案例,技術專家直播,問答區近萬人Spark技術同學線上提問答疑,隻為營造純粹的Spark氛圍,歡迎釘釘掃碼加入!
對開源大資料和感興趣的同學可以加小編微信(下圖二維碼,備注“進群”)進入技術交流微信群。
Apache Spark技術交流社群公衆号,微信掃一掃關注