1.什麼是Shell及其特點:
Shell是指令解釋器,它接收應用程式或使用者指令,然後調用作業系統核心。
Shell是一個功能強大的程式設計語言,易編寫、易調試、靈活性強。 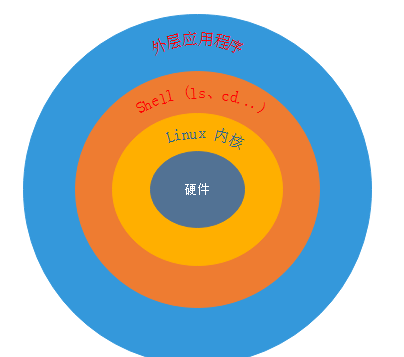
2.Shell類型檢視及配置:
檢視主機上有哪個shell:#cat /etc/shells
檢視目前所用shell:#echo $SHELL
更改目前shell: #chsh /bin/sh
sh是bash的軟連結:
[root@centos7 ~]#ll /bin/ |grep bash
-rwxr-xr-x. 1 root root 964608 Oct 31 2018 bash
lrwxrwxrwx. 1 root root 10 Jul 17 2019 bashbug -> bashbug-64
-rwxr-xr-x. 1 root root 6964 Oct 31 2018 bashbug-64
lrwxrwxrwx. 1 root root 4 Jul 17 2019 sh -> bash 3.Shell腳本:
(1)開頭:#!/bin/bash
(2)啟動shell及執行權限與否:
./*.sh等價于sh ./*.sh等價bash ./*.sh,腳本執行是在重新啟動一個子shell中執行。./*.sh需要加x權限則$0生效,sh與bash有無x對$0生效。
source ./*.sh等價于. ./*.sh,腳本執行是在目前shell程序中執行,無需重新啟動一個子shell。 $0則無效。
【./*.sh執行腳本需要腳本有執行權限,這由于本質是腳本需要自己執行,是以需要執行權限;
而其餘的則不需要,這由于是本質是bash解釋器幫你執行腳本,是以腳本本身不需要執行權限】
(3)多指令操作:可以一行一行的寫,不需要分号隔離或可以用上&&。 4.Shell變量:
(1)系統變量:
[root@centos7 ~]#echo $HOME $PWD $USER $SHELL
/root /root root /bin/bash
(2)自定義變量:變量=值 【等号兩邊沒有空格,這裡的等号是指派】
定義變量:a=10
檢視值: echo $a
撤銷變量:unset a
聲明一個靜态變量:readonly變量
【不能unset,但可以退出此session就撤銷了。靜态變量聲明時需要指派,否則聲明後不可指派
非靜态變量,可以轉化為靜态變量:readonly 變量名】
(3)變量定義規則:
變量名稱是由字母、數字和下劃線組成,但是不能以數字開頭;環境變量名建議用大寫。
等号兩側不能有空格。
在bash中,變量預設類型都是字元串類型,無法直接進行數字運算。
變量的值若有空格,需要使用雙引号或單引号括起來。
例子如下:
[root@centos7 ~]#4ab=123
bash: 4ab=123: command not found...
[root@centos7 ~]#
[root@centos7 ~]#_4ab=123
[root@centos7 ~]#echo $_4ab
123
[root@centos7 ~]#
[root@centos7 ~]#a =3
bash: a: command not found...
[root@centos7 ~]#a= 3
bash: 3: command not found...
[root@centos7 ~]#a=3
[root@centos7 ~]#echo $a
3
[root@centos7 ~]#
[root@centos7 ~]#b=3+8
[root@centos7 ~]#echo $b
3+8
[root@centos7 ~]#
[root@centos7 ~]#c=345 ad
bash: ad: command not found...
[root@centos7 ~]#c="345 ad"
[root@centos7 ~]#echo $c
345 ad
[root@centos7 ~]#
(4)可把變量提升為全局環境變量,可供其他shell程式使用:
export 變量名
【可以先聲明再指派或聲明的同時指派:export a或export a=100】
(5)特殊變量:
$n,n為數字,$0代表腳本名稱,$1-$9表示第一個到第九個參數,十及以上的參數需要用大括号${10}表示。 $n參數之間是以空格為分隔符。
$#,擷取所有輸入參數的個數,常用于循環。
$*與$@,都是擷取指令行中所有的參數,但$*把所有的參數看成一個整體;$@把每個參數區分對待。
$?,最後一次執行的指令傳回狀态。值為0,證明上一個指令執行正确;值為非0,證明上一個指令執行不正确。 5.運算符:
(1)基本文法:
一種:$((運算式))或$[運算式]。+、-、*、/、%對應加、減、乘、除、取餘。例子:$(((2+3)*4))等價于$[(2+3)*4]
另一種:expr +、-、\*、/、%對應加、減、乘、除、取餘。【expr運算符間要有空格】。例子:expr `expr 2 + 3` \* 4
【bc、expr、let可用于數值計算:bc可以用于整數或小數的計算,而expr與let隻能用于整數的計算
輸入:整數,let和expr都無法進行浮點運算,但是bc和awk可以。
輸出:bc、expr可直接顯示計算結果;let則丢棄計算結果,可通過傳遞結果到變量,取變量值獲得計算結果。
例子:let a=3+4.4 echo $a
expr `expr 2 + 3` \* 4
echo 9+4.4|bc 或echo 9+4.4"|bc
】 6.條件判斷:[ condition ] 或 [[ condition ]]
(1)基本文法:
[ condition ] 【注意condition前後要有空格,條件非空即為true,[ a ]傳回true;[]傳回false。】
condition中的條件操作:所判斷的内容與條件符号之間要空格。例子:a=abc [ $a == abc ];若是寫成了[ $a==abc ]這是恒為true,由于$a==abc相當于5==abc并不是比較判斷而是直接非空。
(2)[ ]與[[ ]]的差別:
相同點:二者都可以進行數字比較判斷或字元串比較判斷。
不相同點:-n或-z方式判斷變量是否為空時,[]形式,需要變量加上雙引号,而[[ ]]則不需要。例子:[ -n "var"] 或 [[ -n var]]
-a(and與)或-o(or或)對多個條件進行連接配接時,[]形式把-a或-o放在[]中,而[[ ]]不能使用-a或-o進行多條件連接配接。 例子:[ 4 -gt 2 -a 4 -lt 5 ]
&&或||進行多條件連接配接時,[]形式把&&或||放在[]外邊,而[[ ]]形式把&&或||放在[[]]裡邊。[ 4 -gt 2 ]&&[ 4 -lt 5 ]或[[ 4 -gt 2 && 4 -lt 5 ]]
使用符号"=~"比對正則表達時,隻能使用[[ ]]。例子:[[ $var =~ [0-9]{11} ]]
當使用">"或者"<"判斷字元串的ASCII值大小時,如果使用[]則加上轉義符\。例子:[ a \< b]
(3)常用判斷條件:
數字比較判斷:-lt(le)ss than)小于、 -gt(greater than)大于
-eq(equal)等于、 -le(less)小于
-le(less equal)小于等于、-ge(greater equal)大于等于
字元串判斷:【盡量把變量或字元串加上雙引号進行比較判斷】
當進行字元串判斷時,可以用[ condition ] 或[[ condition ]]進行判斷,但[ -n "var" ]或[ -z "var" ]時都需要加上雙引号;而[[ -n var ]]或[[ -z var ]]不需要加上雙引号。
=或==都可以表示字元串相同判斷。
!=是進行字元串不相同判斷。
-n是字元串為非空則真,可以了解為nozero。
-z是字元串為空則真,可以了解為zero。
(4)檔案測試判斷:【用相當路徑時,注意目前所處位置及檔案的路徑;建議用上絕對路徑】
-e是檔案或目錄存在為真。例子:[ -e path ]
-f是檔案存在為真。例子:[ -f file_path ]
-d是目錄存在為真。例子:[ -d dir_path ]
-r -w -x分别是讀寫執行。
-s檔案存在并且大小大于0為真。例子:[ -s file_path ] 7.單小括号( )、雙小括号( )、單中括号[ ]、雙中括号及大括号{ }:
小括号( ):
指令組:括号中的指令将會新開一個子shell順序執行,是以括号中的變量不能夠被腳本餘下的部分使用。括号中多個指令之間用分号隔開,最後一個指令可以沒有分号,各指令和括号之間不必有空格。
指令替換:等同于`cmd`,shell掃描一遍指令行,發現了$(cmd)結構,便将$(cmd)中的cmd執行一次,得到其标準輸出,再将此輸出放到原來指令。有些shell不支援,如tcsh。
初始化數組:如:array a1=(a b c d)。
雙小括号(( )):
整數運算:例子:echo $((4+5))或echo $((16#5f))結果為95(16進位轉十進制)。
重定義變量:a=4;((a++))可以a重定義為5。
雙括号中的變量可以不使用$符号字首。括号内支援多個表達式用逗号分開。例子:for((i=1;i<10;i++))。
單中括号[ ]:
條件判斷: [ condition ]。例子:[ $a == abc ]
在一個array 結構的上下文中,中括号用來引用數組中每個元素的編号。例子:a[1]
雙中括号[[ ]]:
條件判斷,[[ ]] 結構比[ ]結構更加通用。
大括号{ }:
大括号擴充:(通配(globbing))将對大括号中的檔案名做擴充。在大括号中,不允許有空白,除非這個空白被引用或轉義。例子:mkdir {a,b}或mkdir {a...d}。
代碼塊,又被稱為内部組,這個結構事實上建立了一個匿名函數 。與小括号中的指令不同,大括号内的指令不會新開一個子shell運作,即腳本餘下部分仍可使用括号内變量。括号内的指令間用分号隔開,最後一個也必須有分号。{}的第一個指令和左括号之間必須要有一個空格。
【幾種特殊的替換結構:${var:-string},${var:+string},${var:=string},${var:?string}】
${var:-string}:如果var為空或者未設定,傳回string,var不變
${var:+string}:如果var有值,傳回string,var不變
${var:=string}:如果var為空或者未設定,傳回string,且var=word
${var:?string}:如果變量var為空或者未設定,傳回string并退出shell,string沒有值則輸出:parameter null or not set,用于檢測var是否被正常指派。
${var#*pattern}:# 從左到右,删除字元串開頭至第一次出現的pattern部分
${var##*pattern}:# 從左到右,删除字元串開頭至最後出現pattern部分
${var%pattern*}:# 從右到左,删除字元串結尾至第一次出現pattern的部分
${var%%pattern*}:# 從右到左,删除字元串結尾至最後一次出現pattern的部分 ${ }引用變量的進階用法:
(1)字元串處理:【隻有在pattern中使用了通配符才能有最長最短的比對,否則沒有最長最短比對之分,隻有完整比對。】
【下面的隻是更改輸出的内容,而var原值并未修改。】
var=abcdefgabcdefg
${var#*pattern} # 從左到右,删除字元串開頭至第一次出現的pattern部分
${var##*pattern} # 從左到右,删除字元串開頭至最後出現pattern部分
例子如下:
[root@centos7 /data/shell]#var=abcdefgabcdefg
[root@centos7 /data/shell]#echo ${var#d}
abcdefgabcdefg
[root@centos7 /data/shell]#echo ${var#*d}
efgabcdefg
[root@centos7 /data/shell]#echo ${var##*d}
efg
${var%pattern*} # 從右到左,删除字元串結尾至第一次出現pattern的部分
${var%%pattern*} # 從右到左,删除字元串結尾至最後一次出現pattern的部分
例子如下:
[root@centos7 /data/shell]#var=abcdefgabcdefg
[root@centos7 /data/shell]#echo ${var%d}
abcdefgabcdefg
[root@centos7 /data/shell]#echo ${var%d*}
abcdefgabc
[root@centos7 /data/shell]#echo ${var%%d*}
abc
${var/pattern/substr} # 查找var存儲的字元串中,第一個被pattern比對到的字元替換為substr
${var//pattern/substr} # 查找var存儲的字元串中,所有被pattern比對到的字元替換為substr
${var/#pattern/substr} # 查找var存儲的字元串中,開頭被pattern比對到的字元替換為substr
${var/%pattern/substr} # 查找var存儲的字元串中,結尾被pattern比對到的字元替換為substr
例子如下:var=abcdefgabcdefg
[root@centos7 /data/shell]#var=abcdefgabcdefg
[root@centos7 /data/shell]#echo ${var/d/D}
abcDefgabcdefg
[root@centos7 /data/shell]#echo ${var//d/D}
abcDefgabcDefg
[root@centos7 /data/shell]#echo ${var/#a/A}
Abcdefgabcdefg
[root@centos7 /data/shell]#echo ${var/%g/G}
abcdefgabcdefG
${var/pattern/} # 查找var存儲的字元串中,删除第一次被pattern比對到的字元
${var//pattern/} # 查找var存儲的字元串中,删除所有被pattern比對到的字元
${var/#pattern/} # 查找var存儲的字元串中,删除開頭被pattern比對到的字元
${var/%pattern/} # 查找var存儲的字元串中,删除結尾被pattern比對到的字元
例子如下:var=abcdefgabcdefg
[root@centos7 /data/shell]#echo ${var/d/}
abcefgabcdefg
[root@centos7 /data/shell]#echo ${var//d/}
abcefgabcefg
[root@centos7 /data/shell]#echo ${var/#a/}
bcdefgabcdefg
[root@centos7 /data/shell]#echo ${var/%g/}
abcdefgabcdef
${var^^} # 将var存儲的字元串中的所有小寫替換為大寫
${var,,} # 将var存儲的字元串中的所有大寫替換為小寫,注意是英文逗号
例子如下:
[root@centos7 /data/shell]#echo $var
abcdefgabcdefg
[root@centos7 /data/shell]#varR=${var^^}
[root@centos7 /data/shell]#echo $varR
ABCDEFGABCDEFG
[root@centos7 /data/shell]#echo ${varR,,}
abcdefgabcdefg
(2)字元串切片:【下面的隻是更改輸出的内容,而var原值并未修改。】
${#var} # 引用字元串的長度
[root@centos7 /data/shell]#var=abcde
[root@centos7 /data/shell]#echo $var
abcde
[root@centos7 /data/shell]#echo ${#var}
5
${var:offset} # 從左到右,引用字元串從第offset(不包括offset)個字元開始到最後的部分
[root@centos7 /data/shell]#echo $var
abcde
[root@centos7 /data/shell]#echo ${var:3}
de
${var:offset:number} # 從左到右,引用字元串從第offset(不包括offset)個字元開始,長度為number的部分
[root@centos7 /data/shell]#echo $var
abcde
[root@centos7 /data/shell]#echo ${var:1:2}
bc
${var: -length} # 取字元串最右側length個字元,注意-length前有一個空格
[root@centos7 /data/shell]#echo $var
abcde
[root@centos7 /data/shell]#echo ${var:-3}
abcde
[root@centos7 /data/shell]#echo ${var: -3}
cde
[root@centos7 /data/shell]#echo ${var:}
-bash: ${var:}: bad substitution
[root@centos7 /data/shell]#echo ${var::}
[root@centos7 /data/shell]#echo ${var::5}
abcde
${var: -length:number} # 先從右到左取length個字元,在從前邊得到的字元中取長度為number的部分,同樣的注意length前的空格
[root@centos7 /data/shell]#echo $var
abcde
[root@centos7 /data/shell]#echo ${var: -3:2}
cd
字元串變量指派:【下面隻有=才會有可能更改var的值,其餘的都不人更改var的值】
${var:-value} # var為空或未設定,則傳回value;有值則傳回var的值
${var:+value} # var為空或未設定,則傳回空值;有值則傳回value
${var:=value} # var為空或未設定,則傳回value并指派給value;有值則傳回var的值
${var:?error_info} # var為空或未設定,則傳回error_info的資訊;有值則傳回var的值
以${var:=value}為例:
[root@centos7 /data/shell]#var=old #有值
[root@centos7 /data/shell]#echo $var
old
[root@centos7 /data/shell]#echo ${var:=new}
old
[root@centos7 /data/shell]#unset var #未設定
[root@centos7 /data/shell]#echo $var
[root@centos7 /data/shell]#echo ${var:=new}
new
[root@centos7 /data/shell]#echo $var
new
[root@centos7 /data/shell]#var= #為空
[root@centos7 /data/shell]#echo $var
[root@centos7 /data/shell]#echo ${var:=new}
new
[root@centos7 /data/shell]#echo $var
new
(3)變量間接引用:
如果var1=var2,var2=value,直接用變量var1引用value,這叫做變量的間接引用。
方法一:eval tmpvar=\$$var1 ;echo ${tmpvar}
方法二:引用${!var1}
例子如下:
[root@centos7 /data/shell]#var=old
[root@centos7 /data/shell]#var1=var2
[root@centos7 /data/shell]#var2=abc
[root@centos7 /data/shell]#echo $var1
var2
[root@centos7 /data/shell]#echo $var2
abc
[root@centos7 /data/shell]#echo \$$var1
$var2
[root@centos7 /data/shell]#eval tmpvar=\$$var1;echo $tmpvar #方法一
abc
[root@centos7 /data/shell]#echo $!var1
var1
[root@centos7 /data/shell]#echo ${!var1} #方法二
abc 7.流程控制:
(1)if:
基本文法:【if、[、condition、]之間要有空格】
if [ conditon ];then
執行xx程式
fi
或者
if [ condition ]
then
執行xx程式
fi
(2)case:
基本文法:
case $變量 in
"value1")
執行xx程式
;;
"value2")
執行xxx程式
;;
*)
執行xxxx程式
;;
esac
1)case行尾必須為單詞“in”,每一個模式比對必須以右括号“)”結束。
2)雙分号“;;”表示指令序列結束,相當于java中的break。
3)最後的“*”表示預設模式,相當于java中的default。
(3)for:
基本文法:
形式一:
for((初始值;循環控制條件;變量變化))
do
執行程式
done
形式二:
for 變量 in value1 value2 value3...
do
執行程式
done
【$*與$@,都是代表全部元素,當加上雙引号後則不同:"$*"表示元素一次輸出; "$@"表示元素一個一個地輸出。
以數組為例子:
【當${var[*]}與${var[@]}不加雙引号時,輸出結果都為元素一個一個地輸出。當加上雙引号後則前者全部輸出,後者一個一個輸出】
var=(a abc d e f 5)
for i in "${var[*]}"
do
echo $i
done
#最終結果為a abc d e f 5
echo “-===========”
for i in "${var[@]}"
do
echo $i
done
#最終結果為 a
abc
d
e
f
5
(4)while:
基本文法:
while [ condition ];do
執行程式
done
或者
while [ condition ]
do
執行程式
done
例子如下:
sum=0
i=1
while [ $i -le 100 ]
do
sum=$[$sum+$i]
i=$[$i+1]
done
echo $sum 8.read讀取控制台輸入:
基本文法:
read (選項) (參數)
選項:
-p:指定讀取時的提示符;
-t:指定讀取值時等待的時間(秒);時間一過就消失
參數:
變量:指定讀取值的變量名。
例子:
read -t 4 -p "please input something:" var;echo $var
9.函數:【函數也是指令,可以
或$()來引用 】
(1)系統函數:
basename:【别看是路徑,其實是對字元串的操作】
basename [string/pathname][suffix]則是删除所有的字首包括最後一個(‘/’)字元,然後将字元串顯示出來。選項suffix為字尾,如果suffix被指定了,basename會将pathname或string中的suffix去掉。
Examples:
basename /usr/bin/sort -> "sort"
basename include/stdio.h .h -> "stdio"
basename -s .h include/stdio.h -> "stdio"
basename -a any/str1 any/str2 -> "str1" followed by "str2"
dirname:【别看是絕對路徑,其實是對字元串的操作】
dirname 則是去掉最後一個非斜杠部分和尾部斜杠; 如果名稱中不包含 ‘/’,則輸出‘. ’(指工作目錄)。
Examples:
dirname /usr/bin/ -> "/usr"
dirname dir1/str dir2/str -> "dir1" followed by "dir2"
dirname stdio.h -> "."
(2)自定義函數:
基本文法:
[function]funname()
{
Action #後面可以加上分号,也可以不加上分号
[return int] #int這個數字在0-255(包括0與255)
}
funname #調用函數
例子如下:
[root@centos7 /data/shell]#cat function.sh
#!/bin/bash
test()
{
var=abc;
echo $var
return 144
}
test
[root@centos7 /data/shell]#bash function.sh
abc
[root@centos7 /data/shell]#echo $?
144
【函數的()不可少;先聲明函數,再調用函數,shell腳本是逐行運作的,不會像其它語言一樣先編譯。
函數的傳回值隻能通過$?系統變量獲得,也可能通過return傳回。如果不加,将以最後一條指令運作結果作為傳回值。return後跟數值(0-255)
】
第二個例子:
[root@centos7 /data/shell]#cat func2.sh
#!/bin/bash
test()
{
sum=$[$1+$2]
echo $sum
}
read -p "請輸入第一個數:" num1
read -p "請輸入第二個數:" num2
echo "這兩數的和:"`test $num1 $num2` #函數也是指令,也可以echo "這兩數的和:"$(test $num1 $num2) 10.shell工具:
(1)tr:translate的簡寫,主要用于壓縮重複字元,删除檔案中的控制字元以及進行字元轉換操作。
基本文法:tr [OPTION]... SET1 [SET2]
-s:squeeze-repleats壓縮重複字元。例如壓縮空格:echo "a b c e"|tr -s" ",結果為a b c e【壓縮是把連續相同的壓縮成一個】
-d: delete删除字元。例如:echo "aabcc"|tr -d "b",結果為aacc。
-t:truncate,将SET1中字元用SET2對應位置的字元進行替換,一般預設為-t。例如:echo "a b c"|tr -t " " ":" ,結果為a:b:c。
也可以利用字元集合進行轉換: echo abcd|tr -t [:lower:] [:upper:] ,其結果為ABCD(小寫轉換成大寫)。
(2)cut:切割,從檔案的每一行剪切位元組、字元和字段并輸出。【隻能以指定數目的制表符進行切割,如空格,要确定空格的個數】
基本文法:cut [選項參數] filename
選項參數:-f為列号,提取第幾列;
例如: -f 1(某列)或-f 2,3(某幾列)戒-f 3-(數字後負号從第三列往後)或-f -3(數字前負号從第三列之前)
-d為分隔符,按照指定分隔符分隔列;預設分隔符為制表符
(3)sort:排序
基本文法:sort (選項)(參數)
選項:-t指定排序時所用的分隔符;
-k指定需要排序的列;
-n依照數值的大小排序;
-r以相反的順序來排序;
參數:指定待排序的檔案清單。
例子:sort -t : -nrk 2 xxx
(4)grep:用于查找檔案裡符合條件的字元串。
基本文法:grep [選項參數] "match_pattern" filename 【match_pattern外的雙引号可無】
選項參數:-v 輸出除之外的所有行,相反輸出
-E=egrep 使用擴充正規表達式
-o 隻輸出檔案中比對到的部分
-n 輸出包含比對字元串的行數
-r 遞歸搜尋
-i 忽略大小寫
-e 多個比對樣式
-q 靜默
在grep搜尋結果中包括或者排除指定檔案:
#隻在目錄中所有的.php和.html檔案中遞歸搜尋字元"main()"
grep "main()" . -r --include *.{php,html}
#在搜尋結果中排除所有README檔案
grep "main()" . -r --exclude "README"
#在搜尋結果中排除filelist檔案清單裡的檔案
grep "main()" . -r --exclude-from filelist
列印出比對文本之前或者之後的行:
#顯示比對某個結果之後的3行,使用 -A 選項:seq 10 | grep "5" -A 3
#顯示比對某個結果之前的3行,使用 -B 選項:seq 10 | grep "5" -B 3
#顯示比對某個結果的前三行和後三行,使用 -C 選項:seq 10 | grep "5" -C 3
#如果比對結果有多個,會用“--”作為各比對結果之間的分隔符:echo -e "a\nb\nc\na\nb\nc" | grep a -A 1
(5)sed: 是一種流編輯器,一次處理一行内容。
基本文法:sed [選項參數] 'command' filename
選項參數:-n是靜默輸出;-e多個指令執行的時候;-i修改檔案内容;-r擴充正規表達式。
指令功能:p是顯示,一般與-n配合使用隻顯示比對到的行。
a是新增,a的後面可以接字元串,在下一行出現;'2a str'或'/str/a str2'
d是删除;'/str/d或2d'
s是替換;'s/str1/str2/g'
(6)awk: 文本分析工具,把檔案逐行的讀入,以空格為預設分隔符将每行切片,切開的部分再進行分析處理。
基本文法:awk [選項參數] 'pattern1{action1} pattern2{action2} ...' filename
選項參數:-F指定輸入檔案分隔符;-v指派一個使用者定義變量。
pattern: 表示AWK在資料中查找的内容,就是模式比對。
action:在找到比對的内容時,所執行的一系列指令。
例子如下:
awk -F: 'BEGIN{print "user===>""shell"} {print $1,$7} END{print "newuser","/bin/newshell"}' /etc/passwd
awk -F: '/^root/{print $0 " "NR,NF}' /etc/passwd 結果為:root:x:0:0:root:/root:/bin/bash 1 7
ifconfig ens33|awk '/netmask/{print $2}'列印ip,預設是以空格分隔符 ![Java String.format方法的簡單使用[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)