前言
在
資料庫代碼化(Database-as-Code)實戰一文中介紹了如何借助
Flyway實作 migration based 的資料庫遷移。但在實踐過程中,發現了如下問題:
- 随着項目的發展,遷移腳本數量會越來越多,而全新部署時由于要執行所有的曆史變更,部署時間會越來越長。
- 由于資料庫的最終狀态是由變更腳本依次執行形成的,這就導緻了開發人員無法通過源碼直覺看到資料庫的目前狀态。
- 因為很多資料遷移場景涉及到字段的解析以及和第三方系統或工具的互動,使用 Python 腳本實作遷移過程會更加友善。但目前 Flyway 隻支援執行 SQL 類型的遷移腳本。
為了解決上述問題,我們基于 migration based 方法,并借鑒了 Flyway 的設計思想,改進了原有的資料庫代碼化方案。
資料庫代碼化改進方案
遷移腳本命名規範
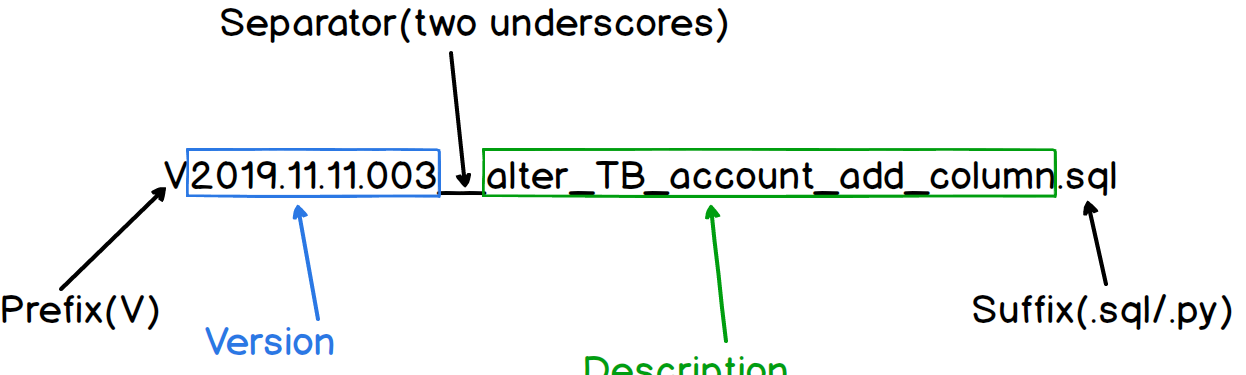
遷移腳本命名規範參考了 Flyway 的标準,但也增加了一些限制,下面對其進行說明:
- Prefix - 固定為
V
- Version - 由日期和索引組成,格式固定為
yyyy.mm.dd.index
- Separator - 固定為兩個下劃線
__
- Description - 描述資訊,文字之間可以用下劃線或空格分隔。
- Suffix - 字尾辨別,支援
.sql
.py
中繼資料表結構
和所有 migration based 方案類似,該方案會在目标資料庫中建立一個名為
schema_version_history
的中繼資料表用于記錄變更資訊,具體表結構如下。
mysql> describe schema_version_history;
+--------------+--------------+------+-----+-------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+-------------------+-------+
| version | bigint(20) | NO | PRI | NULL | |
| description | varchar(200) | YES | | NULL | |
| installed_on | timestamp | NO | | CURRENT_TIMESTAMP | |
| type | varchar(20) | YES | | NULL | |
+--------------+--------------+------+-----+-------------------+-------+ 下面對各字段的含義作簡要說明。
- version - 已成功應用到資料庫上的遷移腳本的版本資訊,字段值會從遷移腳本名中提取。例如,
2019.11.11.003
20191111003
- description - 已成功應用到資料庫上的遷移腳本的描述資訊,字段值會從遷移腳本名中提取。
- installed_on - 遷移腳本成功應用到資料庫上的時間。
- type - 遷移腳本的類型辨別(NORMAL、LEGACY、PRE INSTALL、POST INSTALL、UPGRADE EMPTY、OUT OF ORDER)。
遷移腳本組織結構
改進方案的遷移腳本組織結構如下:
|--{db1}
|--db.conf
|--init_scripts
|--a.sql
|--b.sql
|...
`--z.sql
|--upgrade_legacy_private_cloud_scripts
|--V0666.00.00.000__alter_TB_a_add_column.sql
|--V0666.00.00.001__change_to_new_index.py
`--V0666.00.00.002__alter_TB_c_add_column.sql
|--upgrade_scripts
|--V2019.11.11.000__alter_TB_b_add_column.sql
|--
|--V2019.11.11.001__TB_c_insert.sql
`--V2019.11.13.000__migrate_legacy_alert_rule.py
|--{db2}
|--db.conf
...
|--common
|--procedure.sql
`--schema_version_history.sql 下面對其進行說明:
- 每個資料庫對應一個獨立的目錄,包含了該資料庫的遷移腳本和配置資訊。
- 資料庫目錄下的檔案
{db}/db.conf
- 子目錄 init_scripts 用于存放資料庫的最新 schema。
- 子目錄 upgrade_legacy_private_cloud_scripts 用于存放專有雲老版本到新版本的遷移腳本。版本号需要小于全新部署時的前置版本号
10000000000
- 子目錄 upgrade_scripts 統一存放公有雲和專有雲的後續遷移腳本。版本号由目前日期和索引組成,大于全新部署時的後置版本号
20000000000
可以看到,和原方案相比,新方案有如下改變:
- 增加了 SQL 檔案
common/schema_version_history.sql
- 去掉了用于存放存量 schema 的目錄
{db}/base_scripts
- 建立目錄
{db}/init_scripts
- 支援執行 SQL 和 Python 類型的遷移腳本。
執行流程
基于上述遷移腳本的管理模式,公有雲和專有雲不同場景的執行流程如下:

版本号編制
為了友善處理公有雲、專有雲各類新老版本的部署和更新場景,通過如下方法對版本号進行編制。
- 資料庫全新安裝前置版本号設為
10000000000
- 資料庫全新安裝後置版本号設為
20000000000
- 專有雲老版本到新版本的遷移腳本版本号小于
10000000000
06660000007
- 公有雲和專有雲新增的遷移腳本以目前期間和索引作為版本号,大于
20000000000
20191111003
全新安裝 or 更新
不能單純根據資料庫是否為空判斷目前應該執行全新安裝步驟還是更新步驟,因為程式有可能在執行全新安裝步驟時建立了若幹張表後異常退出。這裡采用的方案如下:
- 在執行 init_scripts 中的腳本之前,向中繼資料表
schema_version_history
10000000000
- 如果 init_scripts 中的腳本全部執行成功,則将 upgrade_scripts 目錄中腳本的最新 version 插入
schema_version_history
- 如果 upgrade_scripts 目錄為空,則向
schema_version_history
20000000000
這樣即使程式中途退出,再次啟動後隻要發現資料庫的版本為
10000000000
,就繼續執行全新安裝的步驟。
腳本的可重入性
每一個遷移腳本的成功執行都對應着
schema_version_history
中的一條記錄。如果遷移腳本是 SQL 檔案,并且是單純的 DML,則可以将遷移腳本和遷移記錄的插入封裝在一個事務中執行,進而避免出現狀态不一緻。但對于包含 DDL 的 SQL 或是 Python 類型的遷移腳本,顯然無法通過事務保證遷移腳本和遷移記錄的插入同時成功或失敗。是以,這裡采用了先執行遷移腳本,再進行遷移記錄插入的政策。這就對遷移腳本的可重入性提出了要求。讓腳本具備可重入性的通用方法可參考
幂等性實踐遷移腳本執行時機
應用更新過程中的資料遷移可能發生在多個階段,下圖展示了某個常見的更新場景。
- 應用開始更新前需要進行一些表結構的變更(資料遷移),支援應用更新後資料以新的格式寫入。
- 應用的更新過程是分批次灰階進行的,此時資料有可能以舊的格式寫入。
- 應用的全部執行個體完成更新後,需要對更新過程中産生的舊資料進行訂正(資料遷移)。
如果嚴格按 version 大小判斷腳本是否需要執行,則有可能出現資料修正腳本無法執行的情況。為此,我們将遷移腳本分成了 pre_upgrade 和 post_upgrade,對于 post_upgrade 中的腳本,隻要在
schema_version_history
中不存在對應的執行記錄,就允許它執行。
總結
和原方案相比,改進後的方案讓全新部署場景下資料庫的初始化時間不會随着遷移腳本的增加而延長,同時也可以通過源碼直覺看到資料庫的目前狀态,另外也支援了 Python 類型遷移腳本的執行。但這些改進也是有一定代價的,它要求開發人員在進行資料庫變更時,既要增加遷移腳本,也要修改資料庫初始化腳本。為了防止開發人員的遺漏,建議對資料庫代碼化部分執行更加嚴格的代碼合入和代碼 review 政策。