最近在讀《資料挖掘》,其中關于資料預覽和預處理(preprocessing)的内容沒有介紹時序資料的處理,但這恰是很重要的應用場景。
例如這道捕魚題
https://tianchi.aliyun.com/competition/entrance/231768/information我将根據書中和網絡上找到的資料,嘗試去清理其中的資料,并将思路記錄下來,以備後查。
題目說明
*初賽
初賽提供11000條漁船北鬥資料,資料包含脫敏後的漁船ID、經緯度坐标、上報時間、速度、航向資訊,由于真實場景下海上環境複雜,經常出現信号丢失,裝置故障等原因導緻的上報坐标錯誤、上報資料丢失、甚至有些裝置瘋狂上報等。
資料示例:
漁船ID x y 速度 方向 time type
1102 6283649.656204367 5284013.963699763 3 12.1 0921 09:00 圍網
漁船ID:漁船的唯一識别,結果檔案以此ID為标示
x: 漁船在平面坐标系的x軸坐标
y: 漁船在平面坐标系的y軸坐标
速度:漁船目前時刻航速,機關節
方向:漁船目前時刻航首向,機關度
time:資料上報時刻,機關月日 時:分
type:漁船label,作業類型
原始資料經過脫敏處理,漁船資訊被隐去,坐标等資訊精度和位置被轉換偏移。
選手可通過學習圍網、刺網、拖網等專業知識輔助大賽資料處理。*
一,屬性類型
屬性(attribute)分為四種,二值屬性(binary),标稱屬性(nominal),數值屬性(numeric),序數屬性(ordinal)。四種屬性都可以使用數字,其中序數屬性有先後,但沒有大小之分;标稱屬性沒有先後也沒有大小含義;數值屬性則具有先後和大小的含義。
機器學習方法中還會使用連續(continuous)和離散(discrete)來分類屬性。
| 漁船ID(ordinal) | x(numeric) | y | 速度(numeric) | 方向(numeric) | time(time) | type(nominal) |
|---|---|---|---|---|---|---|
因為原文中沒有讨論時間,是以我将時間單獨列為一類,它也确實不符合其他幾種屬性的含義。
資料描述(statistical description)
在資料預處理之前,先進行資料預覽(overall picture of your data),可以對資料有個大體的了解。對非時序資料,主要觀察資料的中心性質(central tendency)和分散性質(dispersion)。
中心性質包括平均數(mean),中位數(median),衆數(mode)。标準對稱資料(symmetric data)即為3M為同一值的分布(distribution),如正态分布。Positively skewed和Negatively skewed分别指Mean>Mode和Mean
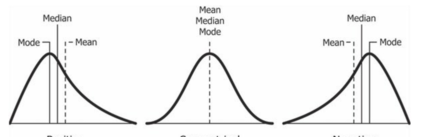
分散性質包括四分位數(quartiles),百分位數(percentiles),方差(variance),标準差(standard deviation)等,描述資料的分散情況。還有五數(five-summary number)和箱圖(boxplot)可以直覺的看到資料分布。
常用圖示包括四分位圖(quantile plot)(1 attri),四分位四分位圖(q-q plot)(1 attri in 2 branchs),直方圖(histograms)(1 attri),散點圖(scatter plots)(2 attri)等。他們各有各的作用和優勢,就不在這裡贅述了。
資料相似性(similarity)和不相似性(dissimilarity)暫時跳過,在時序資料上似乎也沒有意義。
遺憾的是我發現時序資料沒法适用上面的知識。對一條船一天内的行進坐标或速度求平均值沒什麼直覺的意義,求方差也就更沒有意義了。
在processing章節中我找到了一些相關的思路。
預處理(preprocess)
預處理的目的是檢查資料的準确性(accuracy),完整性(completion)和一緻性(consistency)。及時性(timeliness)和可解釋性(interpretability)也會影響資料的品質。
針對這幾個性質,我可以試着提出幾個方法,衡量這批時序資料品質。
0.準确性:中繼資料檢測
中繼資料(metadata)指的是對于該列資料我們已有的知識,例如日期的取值範圍。(Use any knowledge you may already have regarding properties of the data, such knowledge or "data about data " is referred to as metadata)。漁船正常速度,方向取值,時間取值,類型取值等錯誤都是可以首先進行檢測和轉換(transformation)的。
1.準确性:坐标錯誤
根據r1和上一條記錄(record)r0的時間間隔,速度和方向,檢測目前坐标正确性。設定偏差門檻值,如果偏差超過門檻值,則标記并跳過此資料,從下一條資料重新檢查。這裡也可能是時間/速度等字段錯誤,看情況修正。
2.準确性:時間序列
考慮到是時間序列資料,資料順序應該準确按照時間先後排列。如果順序錯誤,應該根據時間調整排序。
3.完整性:資料重複
将資料按照時間長度分桶,特定桶内保留一定條數的資料,其他資料删除。或者,如果目前記錄與前一條記錄時間間隔小于1分鐘,則删除該資料。
4.完整性:資料丢失
一段時間内沒有記錄。書中提出了6種填補缺失值的方法。忽略(ignore the tuple),手動填充(fill in the missing value manually),用特定值填充(global constant),根據中心趨勢填充(central tendency),用均值填充(mean,median,mode),用最可能的值填充(most probable value)(regression,decision tree,Bayesian formalism)。
我把部分訓練資料畫出路線觀察,缺失資料往往畫出簡單的幾何圖形,不同的label對應的幾何圖形常常相同,是以首先嚴重缺失的資料可以直接删除,例如低于10條的行船記錄,或者間隔時間大于5小時的記錄。對于其它确實的記錄,可以用線性插值的方法,根據前後兩條記錄的坐标補全。因為這是行船路線,是以複雜的拟合似乎也沒有必要。
5.綜合:置信度
除了明顯錯誤的資料外,每條資料的可信度也可以有所區分。例如間隔時間較長,移動速度過快的記錄(record),包含有效記錄條數少的行船日志,都應該有較低的置信度。在使用資料時,低置信度的資料對模型産生的影響應該更小。
清理(cleaning)過程
0.中繼資料檢測
經過了解,漁船速度一般在20以下。資料中有一批30以上,甚至100的。我将20以上的速度用上下兩條資料的平均速度替換掉。
方向沒有[0,360]範圍外的資料。
時間有相距較長的,都是跨天的資料,沒有很大的問題。
根據(r0.position-r1.porsition)/(r0.time-r1.time)計算出移動速度(這裡的兩點距離使用曼哈頓距離,為了減少計算量和防止溢出)。發現有數條明顯坐标偏移的資料,與前後記錄的坐标的相距甚遠。計劃用前後記錄生成合理值代替之。
記錄順序沒有問題。
确實存在“瘋狂上報坐标”的情況,例如持續幾分鐘内每秒都上報一條記錄。大部分記錄間隔為600,以此為标準,間隔100以下的記錄可以進行合并。是否恢複這項轉換将視測試結果而定。
如上所述,存在部分記錄間隔時間遠大于600s。在260萬條記錄之中,有60條記錄間隔超過10小時,5條超過20小時,可以以手工的方式決定如何處理這些資料。對于間隔過大的資料可以以600s為标準生成補間值。
資料轉換(transformation)
在錯誤資料清理完成後,還需要對資料進行加工,使他們更易于挖掘。書中提出了平滑(smoothing),屬性建構(attribute construction),聚合(aggregation),正則化(normalization),離散化(discretization),标稱概念建構(concept hierarchy generation for nominal)(例如身高180·200cm 替換為“高”)
根據本題資料和題意,我準備進行資料平滑和正則化兩個加工。
1.平滑
平滑操作的對象是離群點,在本題中是坐标和速度資料的離群點,那些明顯不正确的資料點可以用前後記錄生成合理數值進行替換。
-
标準化(standardize/normalize)
标準化的目的是縮小資料的範圍(range)。目前坐标資料範圍寬度是300W左右。使用的度量機關可能會影響資料分析。例如,将測量機關的高度從米更改為英寸,或者将重量的機關從千克更改為磅,可能會導緻非常不同的結果。通常,以較小的機關表示屬性會導緻該屬性的範圍更大,是以傾向于賦予此類屬性更大的效果或“權重”。為避免依賴于度量機關的選擇,應将資料标準化或标準化。這涉及将資料轉換為落入較小或常見的範圍内,例如[-1,1]或[0.0,1.0]。在設計神經網絡的挖掘方法中,标準化的資料有助于加快學習速度。
書中介紹了三種正則化方法
2.1 根據最大,最小值标準化Min-max normalization
2.2 根據均值,方差标準化 z-Score normalization(在最值是離群點的資料中非常有用)
2.3 根據最值絕對值,移動小數點 decimal normalization(例如最值是985,則所有資料除1000)
對于方法2和3需要儲存所使用的參數,以便對後續資料統一标準化
3.時間标準化
根據和起始時間之間的秒數,将時間标準化到[0,1]的範圍内,使用2.1方法。因為在不同漁船的記錄序列之間,絕對時間沒有意義。
4.時間對齊
不同船隻上報資料的時間間隔不同,整理為RNN的訓練資料輸入時,
5.資料擴充(scaling)
在書中沒有提到這步。因為原資料比較少,三個類别的序列數大概是(1500,4000,1500)。一方面不同類型之間資料不平衡,另一方面資料總量也比較少。因為應用場景是海上,不受到道路限制,是以我想到對坐标進行中心旋轉,比如每0.1度生成一套新資料,看看訓練效果如何。
使用RNN進行訓練和測試
![Anaconda:Matpotlib工具安裝[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)