在消息系統中,消息的生成和消費通常支援三種模式: at-most-once,at-least-once 和 exactly-once。 這幾種模式的差別主要在于當系統發生錯誤的時候,系統表現何種行為。前兩種模式,非常容易了解,出錯後不處理或者不停重試直到成功為止,對于exactly-once的模式,系統在出錯的時候,則需要進行特殊處理來保證一條消息隻被處理一次。
發生錯誤的場景
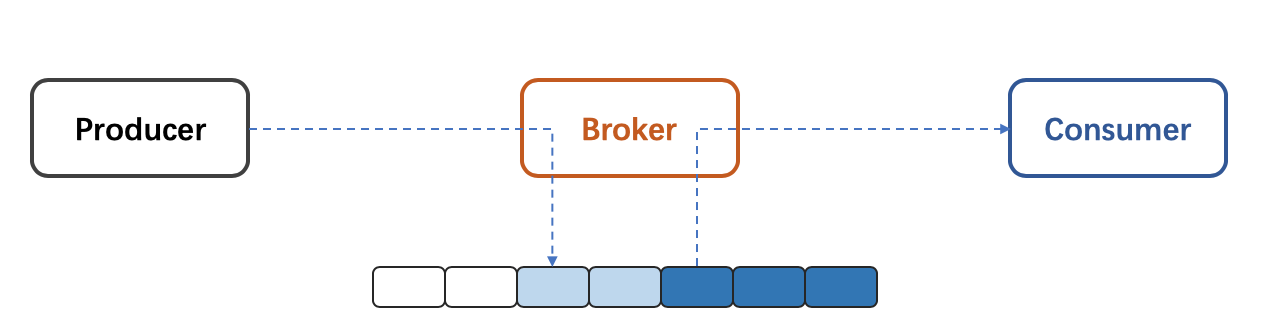
上圖是常見的消息系統(如Kafka/Plusar/sls loghub等)的架構,消息(message)由生産者(Producer)發送至消息系統的接收者(Broker),Broker将Message持久化到特定分區(Partition)後,供消費者(Consumer)進行消費。在這個過程中,任意階段都可能出錯。
- Broker 錯誤:Broker作為系統的主要組成部分,負責資料的接收和讀取,當單個broker fail的時候,不同的系統表現行為也不同,可能會重新選舉Leader或進行broker的failover,在這個過程中,消息的讀寫可能發生失敗
- Producer到Broker RPC錯誤 : Producer将資料發送至Broker後,需要收到Broker的ack才能确定消息寫入成功,在Broker出錯,或Producer到Broker網絡異常等情況下,Producer可能無法收到ack資訊,這時,Producer無法确認消息是否已經正确持久化,如果Producer忽略錯誤,這表現為at-most-once模式,進行重試直到成功,則可能是at-least-once
- Producer :消息的生産者本身也可能會因為程式異常、機器當機等行為導緻異常,在Producer記憶體中尚未發送的消息,如果不做特殊處理,則會丢失
- Consumer :作為消息的消費者,在發生錯誤的時候如何恢複消費的狀态以及從哪個位置再次開始消費資料,則決定消費情況系統表現那種模式
寫入模式下Exactly-Once
從上面的錯誤場景可以看到,錯誤在任意階段都可能發生,要做到任意情況下完全的exactly-once寫入代價極其昂貴,線上上大規模生産系統中,很難承受:
- 每條消息有一個唯一的ID
- Broker在接收到一條消息後,進行全局校驗ID是否重複
- Broker對于消息ID的校驗和寫入原子操作
在分布式場景下,做全局全量資料的原子排他性操作,成本無法接受的。那退而求其次,在一定限定條件下,則可以更高效達到exactly-once的效果。可以從以下兩方面進行限定:
- Producer 發送的一條消息,在各種錯誤情況下,限定隻到某個Broker下的确定Partition。這樣消息無需做全局的校驗,隻需要在Partition級别即可;
- 單個Producer 到單個Partition的消息ID(Sequence ID)單調遞增,這樣雖然降低了單個Producer到單個Partition的吞吐(串行),但是每個Partition對于Producer消息的ID校驗大大簡化,隻需要效驗一個ID即可,無需維護曆史所有ID

通過以上兩個簡化,在Partition級的exactly-once的寫入操作,隻需要額外一次HashMap的查詢即可,而持久化的資料,也隻會增加極少量的字段(ProducerID, Sequence ID)。
Broker Failover 處理
在Broker Failover的時候,必須将Broker記憶體中各個Producer目前寫入的SequenceID完全恢複出來,才能保證資料exactly-once寫入。在持久化的資料中,有每條消息的ProducerID和SequenceID資訊,可以通過掃描持久化資訊進行恢複,同時為了加快恢複速度,可以定期将Broker記憶體中的HashMap作為snapshot儲存下來,在恢複的時候,首先恢複snapshot,然後隻需要讀取少量的資訊完成ProducerID和SequenceID映射重建。
Producer Failover 處理
當Producer Failover的時候,對于部分資料源和SequenceID可映射的場景,可以根據ProducerID從Broker中擷取最新的SequenceID,根據該ID對資料源進行重置(如Producer的資料源是檔案,SequenceID 和檔案行号能進行映射),Producer可以從上次最後寫入成功的位置繼續寫入。
消費模式下 Exactly-Once
在完成exactly-once寫入後,為了支援端到端的exactly-once處理, 同樣需要消費端的配合,這裡主要指在消費端failover時,如何確定每條消息隻被處理一次。 雖然不少消息系統提供ack機制,消費者隻需關系資料的處理即可,如Plusar提供的consumer會自動拉取消息供應用消費,應用隻需要關心消息的處理,在處理完畢後,對消息進行ack即可。
Consumer consumer = client.subscribe(...);
while (true) {
Message msg = consumer.receive();
// Process the message...
consumer.acknowledge(msg);
} 但是,這種簡單的消費模式,無法支援exactly-once,核心在于消息的處理和ack是非原子操作。當消息處理完畢尚未進行ack時,consumer可能crash,重新開機後,這條消息将被重複消費(broker尚未收到這條消息的ack資訊)。
是以,為了支援exactly-once消費,需要将消息處理的結果(通常使用狀态表示)和消息的ID持久化到其他外部系統中,以確定failover能恢複到某個完全精确的狀态繼續消費,如flink使用的checkpoint機制,将flink内部某時刻狀态以及消費的位置資訊進行持久化。
即使如此,如果在消費過程中,會額外産生結果并寫入其他下遊系統時,如果這些系統不支援幂等操作,那麼在failover時,consumer重複消費資料時,下遊系統還可能看到at-least-once的結果(如消費資訊進行短信報警的場景)。
以上是對于消息系統的端對端支援exactly-once的簡單探讨,通過一定的條件限定,寫入端支援相對容易,而消費端除了較複雜的checkpoint機制外,還依賴消費産出下遊系統的支援。