對于經常從事資料開發工作的同學而言,阿裡巴巴大資料研發平台Dataworks應該都比較熟悉,作為集大資料設計開發、運維監控、資料安全、資料品質管理,以及資料應用建構等全方位能力為一體的的一站式資料研發生态平台,Dataworks極大提升了資料開發工作的效率。而資料內建作為Dataworks生态系統内的子系統,為大資料綜合治了解決方案提供底層資料鍊路支援,以其穩定高效、彈性可擴充的資料同步能力,目前已經廣泛應用與集團内、公共雲、專有雲的各種資料同步場景。
項目背景
業務場景
通常來說,資料內建服務的業務場景如下
- 資料上雲:使用者需要把自己的雲下資料快速安全的遷移到雲上存儲并做進一步的業務分析,如線下mysql、oracle到雲上Maxcompute
- 異構資料源間的同步:使用者的原始資料需要轉移存儲系統存儲,或利用目标存儲系統的查詢、分析能力,如Maxcompute資料回流到線上mysql做線上查詢
基于這些業務場景,資料內建一直以來都扮演着資料搬運工的角色,為各種各樣的資料同步需求提供了強大高效的一站式解決方案。
但對于很多資料開發工作而言,将資料從源端同步到目标端隻是完成了整個資料開發鍊路中的一個環節。限于資料內建以往僅支援資料讀寫的能力,如果需要對同步的源資料進行一些資料過濾、簡單邏輯加工或者資料增強等一些資料處理操作,除非源資料存儲系統支援,否則隻能先将源原始資料全量同步到目标存儲系統,再利用目标系統的能力進行資料加工。這就增加了資料開發工作的複雜度,也降低了資料處理鍊路的時效。
舉一個例子,oss上的大量資料要同步到Mysql做線上查詢,同時期望對原始資料進行一些資料過濾和簡單加工。
原有方案
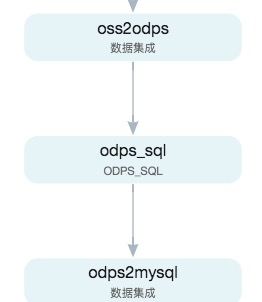
- oss本身不具備資料加工能力,需要配置資料同步任務1,将oss資料同步到Maxcompute上;
- 在Dataworks上開發SQL處理任務,然後運作SQL任務進行資料處理,将結果輸出到Maxcompute新表
- 配置資料同步任務2,将Maxcompute新表資料同步到目标mysql存儲
有上可見,為了完成這樣的資料開發需求,使用者需要開發資料同步,SQL處理等兩種任務、三個節點,開發成本高。而在任務執行時,則是順序依賴的運作三個任務節點,資料同步+處理的效率很差且運作成本也很高。
全域資料內建
為了提供給使用者更好的資料開發體驗,降低使用者進行資料同步、上雲、以及處理的鍊路成本,全域資料內建應運而生。
全域資料內建的目标是提供使用者一站式的資料同步和資料處理的能力,允許使用者在資料內建界面上通過簡單高效的一站式操作完成這樣的資料開發和運維工作,且能有效降低運作成本。
整體架構

如上圖示,全域資料內建的大體組成如下
- 資料源端:對接各種網絡環境下(IDC、雲上、端)的各種異構資料源(流、批),支援資料從目标端讀出
- 核心服務層:全域資料內建核心服務基于Dataworks基礎服務建構,充分利用Dataworks已有的子系統或子子產品(streamstudio、uniflow、排程、運維管理等)的能力,将資料同步、資料處理的開發和運維能力整合起來
- 同步引擎層:資料同步引擎利用Datax、Streamx的強大的讀寫能力和對異構網絡資料源的支援能力,實作流批資料的讀寫
- 緩存層:緩存層作為計算層和同步引擎層的資料讀寫交換
- 計算層:利用Flink強大的流批統一的計算能力實作資料處理
- 目标端:對接雲上以及各種網絡環境的異構資料源,将資料寫入目标端
資料同步和處理過程
- 利用現有資料同步引擎(Datax、Streamx)的強大讀能力将源資料同步到源端緩存層
- 在資料處理層,啟動Flink任務執行對源資料的過濾、加工以及資料增強的處理,并輸出處理結果到目标端緩存層
- 利用現有資料同步引擎(Datax、Streamx)的強大寫能力将目标端緩存層資料同步到目标端存儲或計算引擎
開發态構成
全域資料內建在以往資料內建開發界面的基礎上,增加了資料處理開發子產品。全域資料內建整體界面構成如下:
-
資料源選擇子產品
包括資料源選擇,以及讀寫參數的指定
- 同步政策子產品
- 配置同步政策,預設是以往的列映射模式,配置需要同步的資料列,僅做資料同步;
- 激活“進行資料處理”按鈕,則進入到資料處理模式,通過元件可視化方式進行處理邏輯開發;
- 列映射模式和進行資料處理是獨立并存互不影響的,在任何情況下使用者均可在兩種模式下進行切換。
-
通道控制子產品
配置資料同步的并發、資源組等任務運作時參數
資料處理模式
在同步政策子產品,激活“進行資料處理”開關時即進入到資料處理開發模式,界面如下:
全域資料內建基于Flink的強大計算能力進行資料處理,在處理邏輯開發層,将Flink SQL的基本API封裝成可視化的DAG算子,以DAG元件托拉拽、元件參數配置、元件連線的方式進行資料處理邏輯開發。
-
左側元件面闆
提供DAG元件的選擇能力。
目前提供9種資料處理元件用于資料加工,同時資料源表元件支援使用者在同步源表資料過程中join其他表資料做資料增強,資料目标表支援使用者在将資料結果到同步到目标存儲系統的同時,多路輸出到其他表
-
右側DAG編輯面闆
提供基于DAG元件的處理邏輯編排能力。
從列映射模式首次切換到資料處理模式時,預設展示源頭表和目标表兩個節點,用于配置需要同步的字段。從元件面闆拖拽資料處理元件、配置元件以進行處理邏輯開發,如下圖示:
DAG模式支援處理邏輯實時檢查,及時提醒節點以及DAG任務配置的正确性,如果節點配置有錯誤(如圖節點上的紅叉),右擊節點選擇“檢視錯誤提示”可以檢視錯誤詳情。
當DAG圖中的所有節點均配置正确,即完成了全域資料內建任務的開發。
通過以上方式,全域資料內建以DAG元件模式提供了使用者一站式開發資料同步和資料處理任務的能力
運維态構成
- 釋出運維
- 全域資料內建任務在運維态為一個完整的獨立節點存在。使用者對全域資料內建任務的運維操作(起停任務、檢視日志),同其他節點一樣是單節點的整體操作。
- 實際執行
- 全域資料內建任務同時啟動了三個階段的工作:将源資料讀取到讀端緩存、将讀端緩存資料利用Flink引擎進行處理并輸出結果到寫端緩存,将寫端緩存資料同步到目标存儲。
- 資料在三個階段的處理過程以類似流資料的方式進行鍊路式處理。是以差別于以往方式以獨立的三個依賴任務節點進行順序處理,全域資料內建任務同步資料+處理資料是連續不間斷的,不需要等待所有資料處理在前一步驟全部完成,同步效率大大提高。
效果展示
總結展望
全域資料內建的整體目标是提供一站式的資料同步+資料處理的能力。目前一期功能作為先期探索,已經實作了批資料一站式同步和處理的能力,打破了資料內建原有的功能邊界,也降低了使用者的資料同步、上雲以及處理的整體成本,未來為實作全域資料內建能力全面、輕便易用、成本集約的整體目标,會在以下幾個方面繼續努力:
- 提供豐富的任務開發能力:字段映射、DAG拖拽編輯、SQL編輯
- 流資料與批資料同步處理能力全面支援
- 提供豐富的任務運作模式:單機運作、分布式運作、叢集模式運作
-
輕量級部署,低成本輸出,靈活對接使用者的運作環境以及場景
目前全域資料內建已經率先在公有雲上線,期待後續給大家帶來更多精彩。