Fivetran簡介
公司發展
Fivetran提供SaaS服務,它連接配接到業務關鍵資料源,提取并處理所有資料,然後将其轉儲到倉庫中,以進行SQL通路和必要的進一步轉換。
參考
今年9月的融資消息,這家公司過去一兩年裡發展很迅速:
- 2012年由Y Combinator發起,種子輪融資$4M。
- 2018年12月,A輪融資額$15M,有80名員工。
- 2019年9月,B輪融資額$44M,有175名員工。過去12個月收入增長3倍,目前有750多個客戶。
核心理念
Fivetran要打造的是基于雲的資料分析平台,其設計哲學可以概括為三點:
- 選擇合适的資料(倉)庫:基于雲的資料存儲,存儲與計算分離,例如Snowflak、BigQuery、Redshift。
- 将資料源可靠的複制到資料倉庫,Ingest階段盡量少地涉及資料轉換。類似思想的還有Kafka Connect等系統,但Fivetran更強調自動化,包括:自動字段映射,資料與schema的同步。
- 徹底的踐行E-L-T模式,用SQL語言在資料倉庫上做業務層分析。
架構
與其核心理念一緻,Fivetran是完全建構在雲基礎設施上的一套服務,使用到虛拟機、函數、對象存儲、VPC、日志等服務。
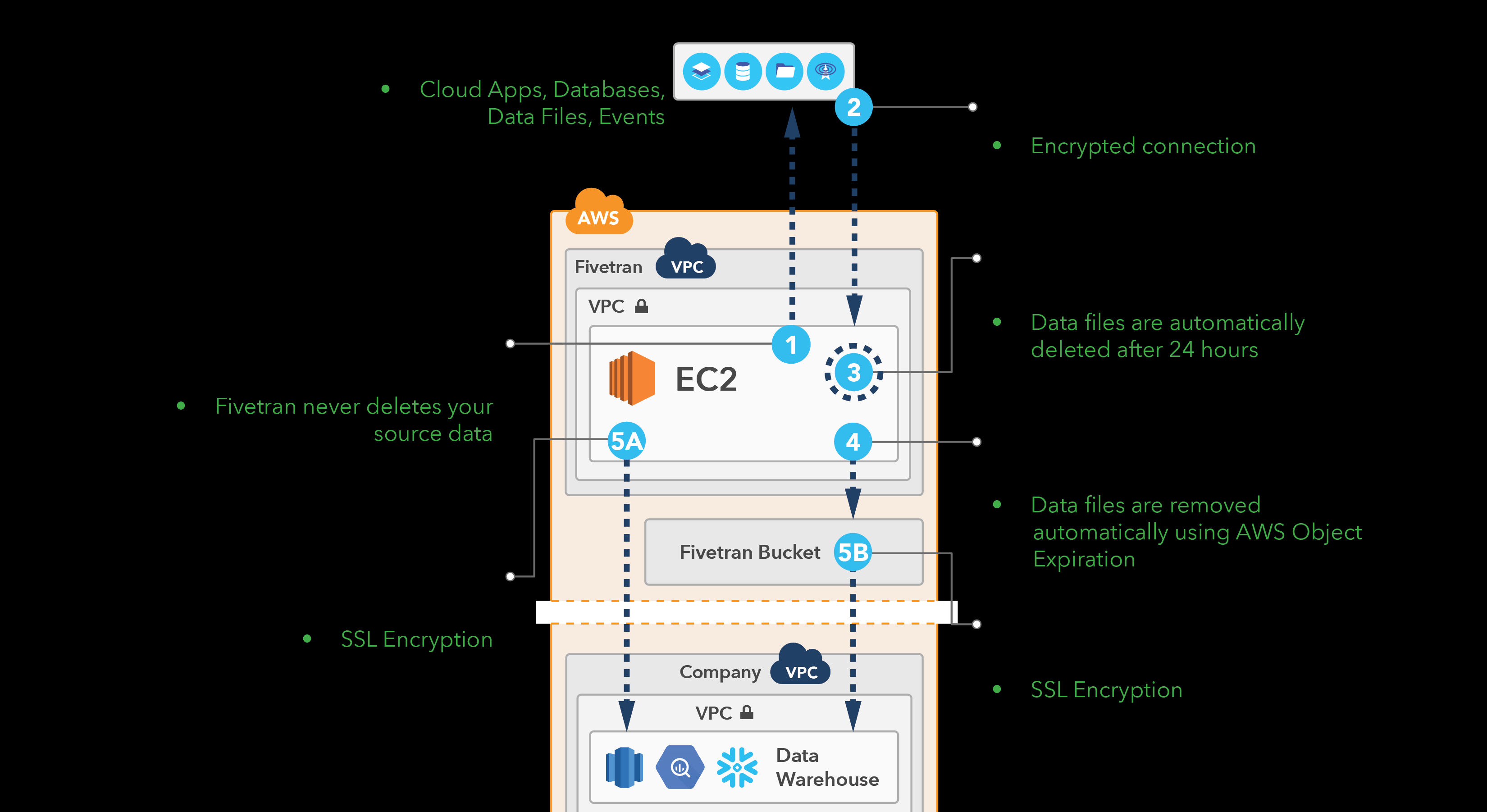
這張圖非常清晰描述了三個階段:
- 擷取源資料到工作節點,圖例1、2、3。
- 準備資料寫到臨時存儲,圖例4。
- 将臨時存儲資料加載到目标資料倉庫,圖例5A、5B。
攝入與準備資料
支援150多種connector,分兩大類:
- pull connector:Fivetran主動發起請求下載下傳資料,以固定時間間隔做周期排程。例如:通過ODBC/JDBC通路資料庫,通過API通路web服務。
- push connector:從源主動寫資料到Fivetran,例如Webhook、Snowplow。接收到事件後,Fivetran以JSON格式存儲資料到對象服務的檔案。
connector擷取到資料後,Fivetran會對資料做一些準備工作,包括:簡單的過濾、排序和去重。在這個過程中,資料會緩存落盤,使用臨時秘鑰做加密。
加載資料到臨時存儲
Fivetran将準備完成的最終資料記錄到檔案,存儲到bucket(可配置雲廠商)。bucket歸Fivetran所有,存儲檔案是經過加密的。
值得一提的是加密使用的秘鑰是臨時的,且秘鑰隻存放在connector程序内。為什麼這麼做?
加載資料到數倉
Fivetran将檔案拷貝至目标數倉,同時該處理程序将秘鑰也傳遞給數倉用于解密資料。當資料倉庫完成對使用者表的資料插入或修改後,connector程序運作完成并結束,scheduler在下一次觸發時再次啟動connector程序。
至此,回答上一節的問題。密鑰隻存在于connector程序的記憶體中,即使背景系統的VPC、Bucket、EC2被入侵,使用者的資料也能保證不被洩露。
系統生成内容
Fivetran會為使用者生成一些系統表格、列。例如fivetran_audit表格記錄每次任務的運作概覽,包括:任務id、起止時間、狀态、唯一的update_id、處理資料行數等。
系統為目标數倉表添加的保留列有:
- fivetran_synced (UTC TIMESTAMP):資料處理時間。
- fivetran_deleted (BOOLEAN) :資料在源中是否被删除。
- fivetran_index (INTEGER):對于無主鍵表,辨別update發生的順序。
- fivetran_id (TEXT) :系統配置設定的唯一ID,用于無主鍵表的去重。
- fivetran_id2 (TEXT) :系統配置設定的唯一ID,在null主鍵情況下,用于再區分。
這些保留字段的加入,主要用意還是透明化,幫助使用者了解資料內建幹了哪些事,友善問題追溯。
日志
Fivetran記錄connector的操作事件,可以存儲到AWS CloudWatch、GCP Stackdriver、Azure Log Analytics。
資料內建
資料源
Fivetran将資料源分為四類:
- Application:例如Google Ads等軟體服務商上記錄了一些系統資料,可以通過API擷取。
- Database:RDS、NoSQL。
- File:包括Azure、AWS、GCP三家的對象存儲,DropBox,FTP等資料源。
- Event:網頁、移動App、郵件等資料源,如下圖,Fivetran額外建構了網關用于接收資料。

Function
如果一定要在資料內建階段就做一些轉換操作,支援AWS、Azure、GCP三家函數服務。這與AWS Kinesis Firehose內建Lambda的方式一緻。函數的實作要求做到幂等性,系統會重試請求直到成功,再把結果寫到bucket。
數倉分析
connector的目标包括單機資料庫(MySQL、SQLServer,PostgreSQL)和分布式數倉(推薦)。
connector程序将資料從源複制到base table,base table是資料在使用者數倉上的第一站。Fivetran的同步是帶狀态的,通過和系統内部資料對比可以避免對目标表做全量scan。使用者不直接在base table上做修改,因為可能導緻後續的sync政策失效。是以,如果有修改base table再讀需求,推薦用view來實作。
Schema遷移
在一次數倉update中,比較新讀取的源資料與已經投遞給數倉的系統内部資料,可以實作schema的同步。
- 表改動:新的object會自動建立數倉表。rename解釋為一次delete和create組合。
- 列改動:新加列會觸發一次對表中的所有行的全量導入。删除列在資料倉庫中保持不變,該列在新增資料行中設為null。但如果伴随着其它改動并觸發了表的重新全量導入,那麼已删除列中的先前的資料會被清除掉。
- 列類型改動:如果是寬轉換(例如int轉bigint)的,那麼直接在數倉更新列的類型。而窄轉換(例如從varchar(100)轉varchar(20))的改變會觸發一次全表的重新導入。
Transformation
同樣是做資料轉換,與Function差別是:Function發生在資料Ingest階段,Transformation則是E-L-T的T,發生在資料到達目标數倉的分析階段。
Transformation完全使用SQL,通過觸發器(新資料被load到數倉後)或基于時間的排程政策,自動觸發表轉換。
觀察與總結
雲數倉
Fivetran是新派的ETL玩家,不僅自己的服務系統基于雲建構,連使用者側分析也是雲上的數倉。
Hadoop、AWS Athena走資料湖線路,可以快速完成初期系統的搭建,但可能因為缺乏資料schema規劃、缺少計算下推的輔助,犧牲了一定的分析效率。
以AWS Redshift、Hive為代表的數倉,提供高效率的壓縮存儲以及存儲、計算的一體化,提升了分析效率,但系統搭建依賴前期表和schema設計,以及在将來schema變化時伴随着維護成本。
Fivetran選擇适配多數倉系統,由使用者根據業務場景自主選擇用什麼做分析。使用SQL(被廣泛支援的數倉語言)統一使用者的Transform、Analytics使用體驗。
E-L-T
這也是雲數倉帶來的另一個好處,水準擴充的計算和存儲。這簡化了對資料內建的使用,資料隻需要安全達到數倉base table即可。而隻要base table資料存在,通過互動式的查詢可以動态修正業務分析的政策,并快速拿到結果。
自動化管道
無論是資料的導入還是schema的同步,自動化都在嘗試解決ETL pipeline維護複雜的問題,這個功能具有現實意義。Fivetran CEO表示他們在幕後驅動自動化的過程非常複雜,但服務會努力向客戶隐藏這種複雜性。
安全很重要
涉及到PII資訊或是滿足GDPR等合規要求,服務對資料加密通路做了細緻的設計,可以看到安全性在這樣的第三方廠商擺在了很高的優先級。
參考資料
個人學習總結,了解不到位處請斧正。