前言
随着雲計算、人工智能、物聯網等新技術的應用普及,人類産生的資料呈現出了爆發式增長的态勢,對資料處理的需求能力也提出了越來越高的要求。資料成了重要資産,收集、處理資料的能力成為了核心競争力,比如:應用服務的運作監控,營運資料的分析,以及深度學習的資料過濾、預處理等,這些對已有資料的處理能力将直接影響服務的營運效率。我們可以使用現成的 ETL 系統完成上述目的,但是在很多情況下您可能希望自建服務。比如:
- 您的資料處理業務不定時運作,希望在無任務時,不消耗任何資源;
- 您的資料處理需求隻有簡單的幾個步驟,"殺雞焉用牛刀"?還是自建來的快點;
- 您的資料處理業務流程有較多的自定義步驟,但現成系統靈活性不足,自建才能滿足業務需求;
- 您不希望消耗過多精力搭建和維護系統中使用的各類開源資料處理子產品,但希望在大并發資料處理請求的場景下能夠有較為良好的性能表現。
如果您有上述需求,或者希望實作一個 高度靈活、高度可靠、低成本、高性能 的離線資料處理系統,那麼本文提供的 Serverless 技術方案将是您的最佳選擇。
業務場景簡介
場景:假設我們有一批待處理資料,資料的值為
data_1
或
data_2
。我們資料處理的目的是統計各類資料的出現次數,并将統計結果存儲到資料倉庫中。當資料量級達到一定程度,亦或資料源異構的情況下,我們很難一次性的通過一個程序在短時間内快速處理完成,在這種場景下,函數工作流 + 函數計算的組合提供了高效的解決方案。
在介紹方案細節前,先來了解下主要會使用到的兩款産品:
- 阿裡雲函數計算 是阿裡雲基于事件驅動的全托管計算服務,通過極強的彈性、多語言的支援、豐富的工具鍊幫助使用者快速搭建 serverless 服務,應對瞬時波峰并免去運維煩惱,讓您專注于業務邏輯。
- 阿裡雲函數工作流 是阿裡雲分布式任務協同的全托管雲服務,支援函數計算、自建服務(如 ECS 自建)等作為底層計算資源來實作您的業務編排。
為友善展示資料處理方面的核心能力,在資料倉庫的存儲方面,我們使用阿裡雲對象存儲(OSS)來代表各種類型的資料庫等作為基礎存儲設施。
下述方案将展示如何使用函數工作流 + 函數計算實作一個低成本高彈性的資料處理系統。在這個系統中,函數計算将根據資料量大小動态提供底層計算資源用于資料的處理、統計等工作,函數工作流将協助實作複雜業務上下遊的邏輯編排。
具體方案
在一般的資料處理業務中,主要關注點如下:
資料源:需要處理的資料源。一般情況下,我們的資料往往來源于各類資料庫、文本檔案(日志檔案)等;在本示例中,我們使用函數生成少量資料用作功能性的展示。在實際場景中,您可以使用各類自定義的資料源作為系統資料輸入來源。
處理架構/模式:MapReduce,本示例中使用函數工作流實作
目的端:資料倉庫。在本示例中,我們使用 OSS 作為資料倉庫,即最終處理後資料的目的端。
資料處理流程:
我們首先将原始資料随機分成 3 -5 個 shards,每個 shard 中兩種類型的資料都有。對每個 shard 先分别進行類型統計,并将中間結果存儲(map)。最後,我們統一處理各 shard 的統計結果,對結果求和并存儲最終結果(reduce)。業務流程如下:
- 從資料源擷取資料;
- 對資料按照某種規則(或随機)劃分 shard;
- 使用MapReduce(提高資料并行處理能力)對資料進行處理;
- 存儲至最終目的源。
結合我們所使用的阿裡雲服務,系統的子產品及互動關系如下圖:
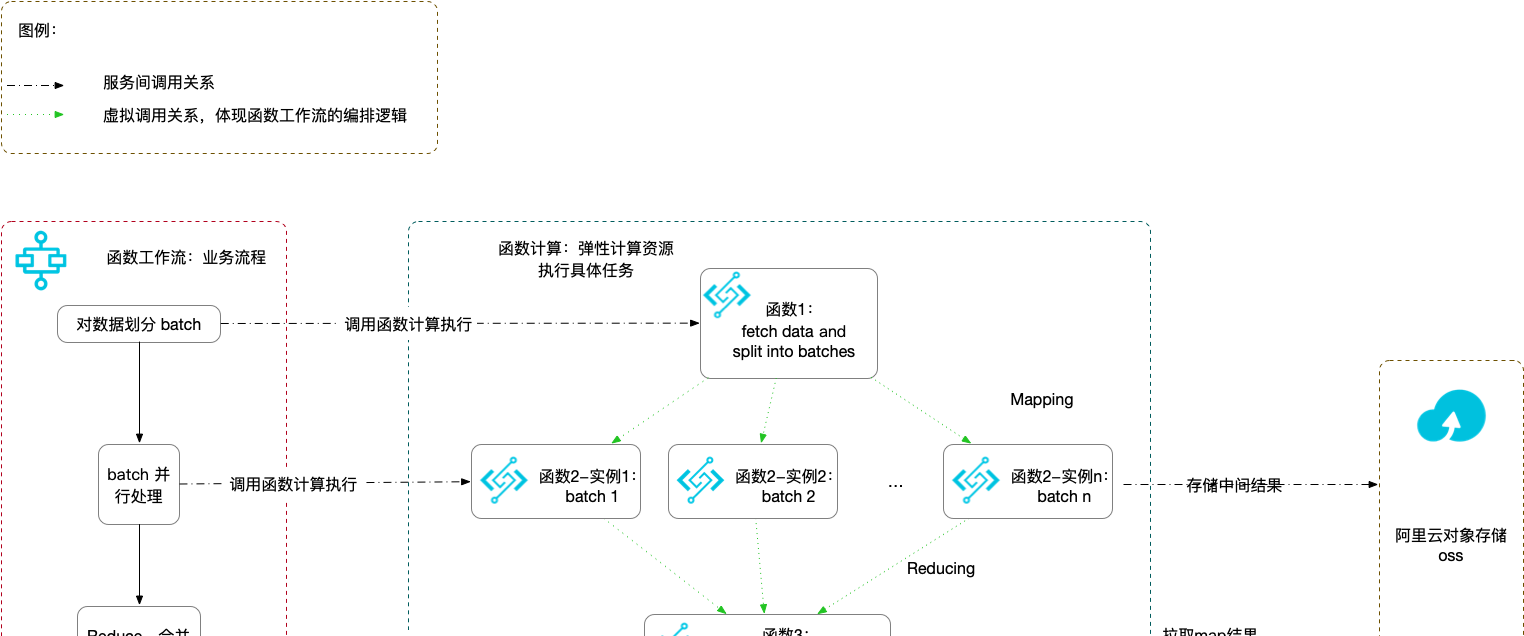
圖 1
方案示例
您可從
github擷取本示例的全部代碼。代碼庫中提供了一鍵搭建本示例全資源的工具,在使用前,請確定您已開通阿裡雲對象存儲、函數計算、函數工作流服務。
資源準備
一鍵搭建示例工程使用了阿裡雲的
資源編排 ROS工具。首先您需要配置好
ALIYUN CLI 工具,之後 clone 本項目後工程目錄下執行下述指令:
aliyun ros CreateStack --StackName=etl-stack1 --TemplateBody "$(cat ./ros.yaml)" --Parameters.1.ParameterKey=MainAccountID --Parameters.1.ParameterValue={YourAccountID} --Parameters.2.ParameterKey=RandomSuffix --Parameters.2.ParameterValue=stack1 --RegionId=cn-beijing --TimeoutInMinutes=10 其中,請将
{YourAccountID}
替換為您的主賬号ID。"stack1" 參數可以使用随機字元串等自定義參數。
執行該指令後,我們将建立以下資源用于本次示例工程:
-
通路控制 - RamRole
用于提供函數工作流的執行及函數計算的執行角色;
-
函數工作流
您可以從
demo-etl-flow.yaml擷取本文所用的流程示例。您可以在
函數工作流控制台檢視建立結果。
-
函數計算
示例工程會建立三個函數,執行上述指令後您可以在 函數計算控制台 檢視建立結果:- shards-spliter : 用于讀取資料源,并依據某種規則對源資料劃分 shard,将 shard 傳回給工作流;
- mapper : MapReduce 架構中的 Map 函數。在該函數中針對傳入的 shard 資料進行過濾、清洗、計算。往往一次資料處理流程中将會根據 shard 數并行生成多個函數執行個體提高資料處理速度。每個 map 函數處理結束後,結果将會被存儲到 oss 的特定目錄下;
- reducer : MapReduce 架構中的 Reduce 函數。在該函數中針對 map 的處理結果進行內建、合并,并推送最終結果至資料倉庫(OSS)。
-
對象存儲(OSS):
在本示例中對象存儲将作為中間資料及最終資料的存儲倉庫。本示例會在 OSS 控制台建立一個名為 demo-etl-stack1 的 bucket。
系統原理及運作示例
本系統的關鍵部分在于 MapReduce 架構的實作。我們使用了函數工作流提供的
并行循環步驟實作了根據資料 shard 數量動态建立 Map 執行個體的功能。在 shards-spliter.py 函數中,我們随機對資料進行了 shard 劃分,并将劃分結果傳回給流程,在下一個并行循環步驟中,流程擷取 shards-spliter.py 中的輸出,并行建立了多個執行個體進行對應 shard 資料的計算。在最後一個步驟中,reducing.py 讀取 OSS 中的中間結果進行聚合後,将最終結果存儲至 OSS。
運作示例及執行結果:

小結
本文介紹了在 ETL 等離線資料處理場景下使用函數計算(FC)、函數工作流(FnF)實作無服務化的解決方案。您可以充分享受到 Serverless 所帶來的高彈性、免運維、輕量化等技術紅利,專注業務場景,快速實作業務價值。
知識連結
函數工作流:
函數工作流文檔,官網客戶群(釘釘):23116481
函數計算:
函數計算文檔,官網客戶群(釘釘):11721331
歡迎加入函數計算、函數工作流官網客戶群,與我們共同交流 Serverless 技術。