01. 前言
寫過或者學過 SQL 的人應該都知道 left join,知道 left join 的實作的效果,就是保留左表的全部資訊,然後把右表往左表上拼接,如果拼不上就是 null。除了 left join 以外,還有 inner join、outer join、right join,這些不同的 join 能達到的什麼樣的效果,大家應該都了解了,如果不了解的可以看看網上的文章或者随便一本 SQL 書都有講的。今天我們不講這些 join 能達到什麼效果,我們主要講這些 join 的底層原理是怎麼實作的,也就是具體的效果是怎麼呈現出來的。
join 主要有 Nested Loop、Hash Join、Merge Join 這三種方式,我們這裡隻講最普遍的,也是最好的了解的 Nested Loop,Nested Loop 翻譯過來就是嵌套循環的意思,那什麼又是嵌套循環呢?嵌套大家應該都能了解,就是一層套一層;那循環呢,你可以了解成是 for 循環。
Nested Loop 裡面又有三種細分的連接配接方式,分别是 Simple Nested-Loop Join、Index Nested-Loop Join、Block Nested-Loop Join,接下來我們就分别去看一下這三種細分的連接配接方式。
在正式開始之前,先介紹兩個概念:驅動表(也叫外表)和被驅動表(也叫非驅動表,還可以叫比對表,亦可叫内表),簡單來說,驅動表就是主表,left join 中的左表就是驅動表,right join 中的右表是驅動表。一個是驅動表,那另一個就隻能是非驅動表了,在 join 的過程中,其實就是從驅動表裡面依次(注意了解這裡面的依次)取出每一個值,然後去非驅動表裡面進行比對,那具體是怎麼比對的呢?這就是我們接下來講的這三種連接配接方式。
02.Simple Nested-Loop Join
Simple Nested-Loop Join 是這三種方法裡面最簡單,最好了解,也是最符合大家認知的一種連接配接方式,現在有兩張表 table A 和 table B,我們讓
table A left join table B,如果是用第一種連接配接方式去實作的話,會是怎麼去比對的呢?直接上圖:
上面的 left join 會從驅動表 table A 中
依次取出每一個值,然後去非驅動表 table B 中從
上往下依次比對,然後把比對到的值進行傳回,最後把所有傳回值進行合并,這樣我們就查找到了 table A left join table B 的結果。是不是和你的認知是一樣的呢?利用這種方法,如果 table A 有10行,table B 有10行,總共需要執行 10 x 10 = 100 次查詢。
這種暴力比對的方式在資料庫中一般不使用。
03.Index Nested-Loop Join
Index Nested-Loop Join 這種方法中,我們看到了 Index,大家應該都知道這個就是索引的意思,這個 Index 是要求非驅動表上要有索引,有了索引以後可以減少比對次數,比對次數減少了就可以提高查詢的效率了。
為什麼會有了索引以後可以減少查詢的次數呢?這個其實就涉及到資料結構裡面的一些知識了,給大家舉個例子就清楚了。
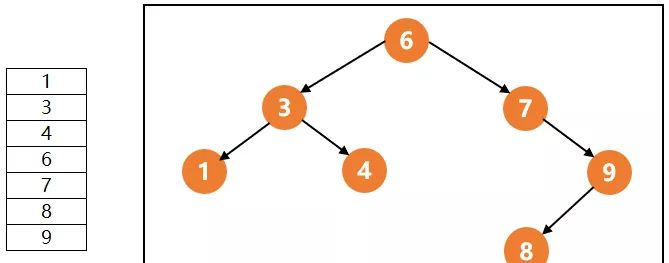
上圖中左邊就是普通列的存儲方式,右邊是樹結構索引,什麼是樹結構呢?就是資料分布的像樹這樣一層一層的,樹結構有一個特點就是左邊的資料小于頂點的數,右邊的數大于頂點的數,你看右圖中,左邊的數3是不是小于頂點6,右邊的數7是不是大于頂點6;左邊的數1是不是小于頂點3,右邊的數4是不是大于頂點3。
假如我們現在要比對數值9,如果是左邊這種資料存儲方式的話,我們需要從第一行依次比對到最後一行才能找到數值9,總共需要比對7次;但是如果我們是用右邊這種樹結構索引的話,我們先拿9和最上層頂點6去比對,發現9比6大,我們就去頂點的右邊去找,再去和7比對,發現9仍然比7大,再去7的右邊找,就找到了9,這樣我們隻比對了3次就把我們想要的9找到了。是不是相比比對7次節省了很多時間。
資料庫中的索引一般用 B+ 樹,為了讓大家更好的了解,我上面畫的圖隻是最簡單的一種樹結構,而非真實的 B+ 樹,但是原理是一樣的。
如果索引是主鍵的話,效率會更高,因為主鍵必須是唯一的,是以如果被驅動表是用主鍵去連接配接,隻會出現多對一或者一對一的情況,而不會出現多對多和一對多的情況。
04.Block Nested-Loop Join
理想情況下,用索引比對是最高效的一種方式,但是在現實工作中,并不是所有的列都是索引列,這個時候就需要用到 Block Nested-Loop Join 方法了,這種方法與第一種方法比較類似,唯一的差別就是會把驅動表中 left join 涉及到的所有列(不止是用來on的列,還有select部分的列)先取出來放到一個緩存區域,然後再去和非驅動表進行比對,這種方法和第一種方法相比所需要的比對次數是一樣的,差别就在于驅動表的列數不同,也就是資料量的多少不同。是以雖然比對次數沒有減少,但是總體的查詢性能還是有提升的。
參考連結:你知道 Sql 中 left join 的底層原理嗎?