為什麼要分庫分表?
随着近些年資訊化大躍進,各行各業無紙化辦公産生了大量的資料,而越來越多的資料存入了資料庫中。當使用
MySQL
資料庫的時候,單表超出了2000萬資料量就會出現性能上的分水嶺。并且實體伺服器的CPU、記憶體、存儲、連接配接數等資源有限,某個時段大量連接配接同時執行操作,會導緻資料庫在處理上遇到性能瓶頸。為了解決這個問題,行業先驅門充分發揚了
分而治之
的思想,對大表進行分割,然後實施更好的控制和管理,同時使用多台機器的CPU、記憶體、存儲,提供更好的性能。而
分而治之
則有兩種方式:
垂直拆分
和
水準拆分
。
垂直拆分
垂直拆分分為
垂直分庫
垂直分表
。先說說
垂直分庫
。垂直分庫其實是一種簡單邏輯分割。比如我們的資料庫中有商品表Products、還有對訂單表Orders,還有積分表Scores。接下來我們就可以建立三個資料庫,一個資料庫存放商品,一個資料庫存放訂單,一個資料庫存放積分。如下圖所示:
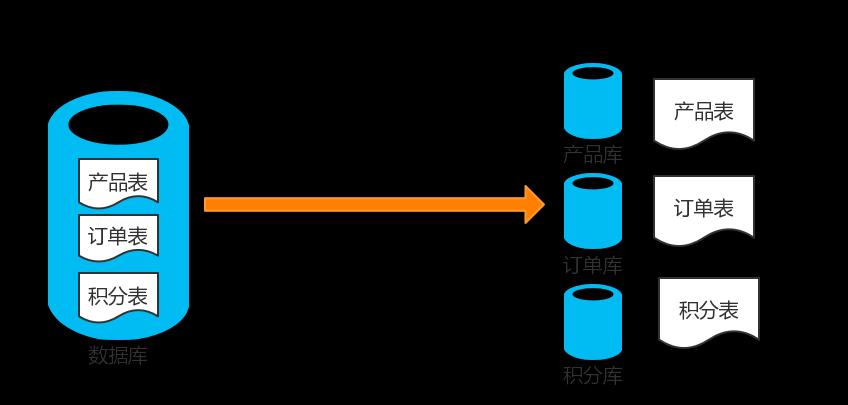
垂直分庫
有一個優點,他能夠根據業務場景進行孵化,比如某一單一場景隻用到某2-3張表,基本上應用和資料庫可以拆分出來做成相應的服務。
再來說說
垂直分表
,比較适用于那種字段比較多的表,假設我們一張表有100個字段,我們分析了一下目前業務執行的SQL語句,有20個字段是經常使用的,而另外80個字段使用比較少。這樣我們就可以把20個字段放在主表裡面,我們在建立一個輔助表,存放另外80個字段。當然主表和輔助表都是有主鍵的。他們通過主鍵進行關聯合并,就可以湊成100個字段的表。

垂直分表
可以解決
跨頁
的問題。在Oracle中叫行連結。怎麼了解呢?就是你字段少的情況下,原本一行資料隻需要存在一個頁裡面就行了,但是字段多的情況就存不下了,就需要跨頁。這樣就會造成額外尋址,造成性能上的開銷。另外将這麼長的一行資料載到記憶體中,往往是幾個頁面,結果咱們經常隻通路其中的幾個字段,對記憶體也是一個極大的開銷。是以為了讓記憶體緩存更多資料,減少磁盤I/O,
垂直分表
就是很好的手段。
總體來說:
垂直拆分
有以下優點:
- 跟随業務進行分割,和最近流行的微服務概念相似,友善解耦之後的管理及擴充。
- 高并發的場景下,垂直拆分使用多台伺服器的CPU、I/O、記憶體能提升性能,同時對單機資料庫連接配接數、一些資源限制也得到了提升。
- 能實作冷熱資料的分離。
垂直拆分
的缺點:
- 部分業務表無法join,應用層需要很大的改造,隻能通過聚合的方式來實作。增加了開發的難度。
- 當單庫中的表資料量增大的時候依然沒有得到有效的解決。
- 分布式事務也是一個難題。
水準拆分
當某張表資料量達到一定的程度的時候,前面曾說過MySQL單表出現2000萬以上資料就會出現性能上的分水嶺。此時發現沒有辦法根據業務規則再進行拆分了,就會導緻單庫上的讀寫性能出現瓶頸。此時就隻能進行水準拆分了。
水準拆分又分為
庫内分表
分庫分表
庫内分表
。假設當我們的Orders表達到了5000萬行記錄的時候,非常影響資料庫的讀寫效率,怎麼辦呢?我們可以考慮按照訂單編号的order_id進行rang分區,就是把訂單編号在1-1000萬的放在order1表中,将編号在1000萬-2000萬的放在order2中,以此類推,每個表中存放1000萬資料。如下圖所示:
雖然我們可以通過
庫内分表
把單表的容量固定在1000萬,但是這些表的資料仍然存放在一個庫内,使用的是該主機的CPU、IO、記憶體。單庫的連接配接數也有限制。并不能完全的降低系統的壓力。此時,我們就要考慮另外一種技術叫
分庫分表
。分庫分表在庫内分表的基礎上,将分的表挪動到不同的主機和資料庫上。可以充分的使用其他主機的CPU、記憶體和IO資源。并且分庫之後,單庫的連接配接數限制也不在成為瓶頸。但是“成也蕭何敗也蕭何”,如果你執行一個掃描不帶分片鍵,則需要在每個庫上查一遍。剛剛我們按照order_id分成了5個庫,但是我們查詢是name='AAA'的條件并且不帶order_id字段時,它并不知道在哪個分片上查,則會建立5個連接配接,然後每個庫都檢索一遍。這種廣播查詢則會造成連接配接數增多。因為它需要在每個庫上都創立連接配接。如果是高并發的系統,執行這種廣播查詢,系統的thread很快就會告警。
水準拆分
的優點有以下:
- 水準擴充能無線擴充。不存在某個庫某個表過大的情況。
- 能夠較好的應對高并發,同時可以将熱點資料打散。
- 應用側的改動較小,不需要根據業務來拆分。
水準拆分
- 路由是個問題,需要增加一層路由的計算,而且像前面說的一樣,不帶分片鍵查詢會産生廣播SQL。
- 跨庫join的性能比較差。
- 需要處理分布式事務的一緻性問題。
一起使用
目前我們的系統,
垂直拆分
水準拆分
都在使用,
垂直拆分
主要是做業務上的分割,把業務的各個子系統都規劃好,能解耦就解耦。而垂直拆分之後。我們再做水準分庫分表。通過取模算法将大表資料拆到若幹個庫中。
邏輯庫和實體庫
介紹了上述的分庫分表,我們有必要說一下幾個概念,一個是
邏輯庫
實體庫
的概念。我們還是拿水準拆分中的
分庫分表
來說。我們在實體層面,将一個庫的資料分割到了5個資料庫中。這5個資料庫就是
實體庫
,而它們對上層應用的展現則是一個庫。這個對上層展現的庫就叫
邏輯庫
。邏輯庫對應用層是透明的。應用不需要了解底層的情況,直接使用就行了。
邏輯表和實體表
還是拿水準拆分中的
分庫分表
來說,orders表總共被分成了5份,分别在底層是orders_1~5。這底層的5個表就是實體表。但是對應用層面來說,隻有orders表。這就是
邏輯表
總結:這一篇主要是講述一些分庫分表之後的概念。需要加深一些了解,因為我們的項目也才是剛剛開始拆分,是以有寫的不對的地方還希望小夥伴們提出意見指正。