HBase使用者福利
新使用者9.9元即可使用6個月雲資料庫HBase,更有低至1元包年的入門規格供廣大HBase愛好者學習研究,更多内容請
參考連結前沿
HBase原生提供了主鍵索引,使用者可以根據rowkey進行高效的單行讀、字首比對、範圍查詢操作。但若需要使用屬性列進行查詢時,則隻能使用filter在查詢範圍内進行逐行過濾。在掃描範圍較大時,會浪費大量的IO,請求RT也無法保證。為此,HBase增強版推出了原生二級索引來解決非rowkey查詢的性能問題。
雲HBase增強版是基于阿裡内部的HBase分支(亦稱Lindorm)建構的,二級索引是其核心能力之一,曆經多年雙11大考,在性能、吞吐、穩定性等方面都具備核心競争力。
下面,我們從一組示例出發來了解索引的使用及其能力。
功能簡介
從表設計和查詢設計的角度看,HBase增強版二級索引的使用與RDBMS的二級索引基本一緻。下面我們看一個簡單的示例:大學生資訊表(
Students
),該表的主鍵(即rowkey)是學号,非主鍵是學生姓名和所屬的學院名稱。學生與學院是多對一的關系。
通過
HBase shell建表,建索引:
# 建立主表student,列族名為f
create 'student', 'f'
# 建立索引表department,為department列建索引
# COVERED_ALL_COLUMNS是HBase增強版引入的新屬性關鍵字,
# 意味備援主表student中的所有列,以此來避免回查主表
create_index 'department', 'student', {INDEXED_COLUMNS => ['f:departement']}, {COVERED_COLUMNS => ['COVERED_ALL_COLUMNS']} 通過Java API進行資料通路
// 定義一些常量
String id = "11"; // 一個随機的學号
String studentName = "Harry";
String department = "CS";
byte[] f = Bytes.toBytes("f");
byte[] qStudent = Bytes.toBytes("name");
byte[] qDepartment = Bytes.toBytes("department");
// 寫入一個學生的資料
Put put = new Put(Bytes.toBytes(id));
put.addColumn(f, qStudent, Bytes.toBytes(studentName));
put.addColumn(f, qDepartment, Bytes.toBytes(department));
Table t = conn.getTable("student");
t.put(put); // put成功傳回意味着主表和索引表都成功更新,變更立即可見
// 按department進行查詢
Scan scan = new Scan();
SingleColumnValueFilter where = new SingleColumnValueFilter(
f, qDepartment, EQUAL, Bytes.toBytes(department));
scan.setFilter(where);
ResultScanner rs = t.getScanner(scan);
// 處理查詢結果... 從上例可見,用HBase API直接描述查詢請求即可使用索引。HBase增強版會自動根據filter以及索引schema來比對到最合适的索引進行查詢,必要時,在查完索引後也會回查主表(上例中,如果不是全備援索引,則會回查主表來補全列)。更多使用上的說明請參考
二級索引開發手冊。
HBase增強版二級索引的主要特性有:
- 支援為單個主表建多個索引
- 支援單列和多列索引(組合索引)
- 支援備援索引:可顯式指定備援列,或備援所有列,避免回查主表的性能損耗
- 查詢優化:根據scan和filter自動選擇合适的索引表進行查詢,必要時會自動回查主表
- online schema change:支援給已經在使用的表建索引,對主表讀寫無影響
- 支援TTL:索引表會自動繼承主表的TTL,主表和索引表資料一起過期
- 支援自定義資料版本:使用者自定義資料時間戳寫入(暫未開放)
産品優勢
高性能
HBase增強版二級索引直接内置于核心中,并做了深度優化,提供了強大的吞吐與性能。下圖是HBase增強版二級索引與Apache Phoenix的全局索引的性能對比:
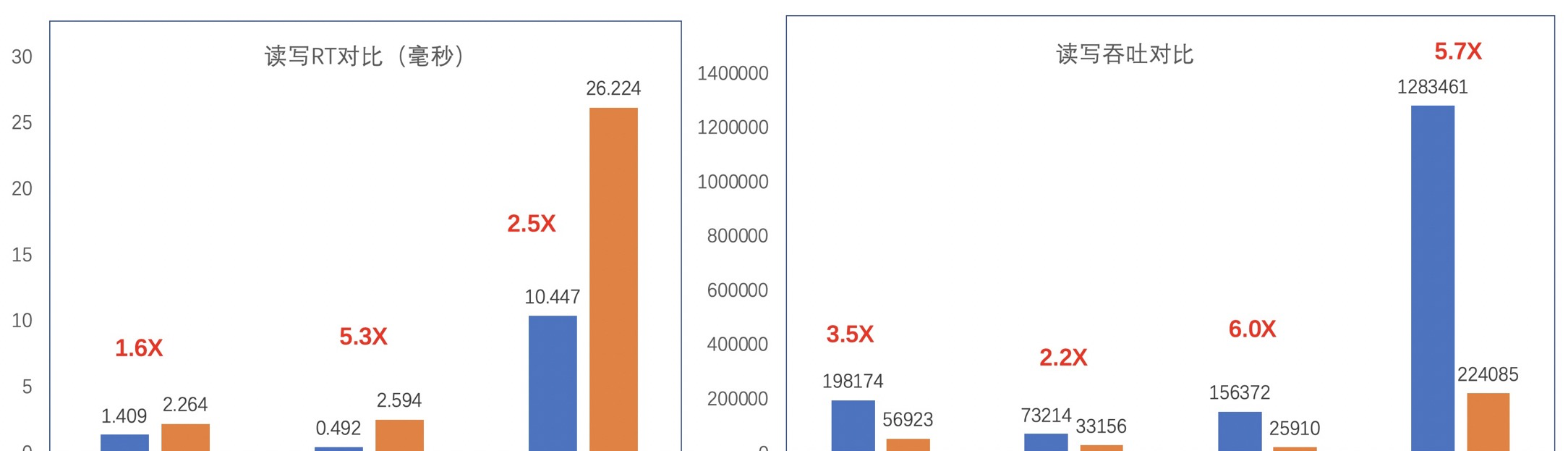
從上圖可見,無論RT還是吞吐,HBase增強版二級索引均遠超Apache Phoenix。
寫後可讀
資料寫入傳回成功後,則索引資料可立即被讀到,消除傳統異步建索引方案中的資料延遲,提供具有一定程度的強一緻性語義(主表和索引表的資料一緻性),具體語義如下:
- 傳回用戶端寫入成功,之後可立即讀到剛寫入的資料(包括主表和索引資料);寫入過程中不保證同時可見
- 傳回逾時或IO出錯,則在一段時間内,該資料在主表和索引表中的可見性無法确定,但保證最終一緻,即要麼全成功,要麼全不成功
HBase增強版提供的”寫成功後更新立即可見的語義“,可用于一些分布式協同的任務,比如spark,在某些節點更新資料,另外一些節點讀取上一輪計算寫入的資料。此時,一定可以讀到剛寫入的資料。
全備援索引
全備援索引可徹底避免回查主表,提升性能;同時也是文法糖,避免手工維護複雜的DDL。下面分别介紹。
如果查詢中需要的列在索引表中沒有,則查完索引後,還需回查主表。在分布式場景下,回表查詢會使得查詢RT大幅度升高,最差情況下可能會回查主表的全部region,通路叢集中的所有機器。此時,索引帶來的性能收益已經可有可無。通過精良的查詢設計和索引設計,我們可以在設計階段避免回查,但随着業務發展變化,這個限制很難維持。是以,仍然需要備援索引(Covered Index)來解決。
HBase增強版創造性的引入了全備援索引的概念,即備援主表中的所有列,以此來徹底避免回查主表。配合HBase的schema-free特性,主表中新增的任何列都會自動備援到索引表中。無論業務模式如何變化,都不需要回查主表。
同時,全備援也是可大幅度提升效率的文法糖,我們可以對比如下兩個SQL語句:
CREATE INDEX idx ON dt (c1, c2) include(c3, c4, c5, c6, ....);
CREATE INDEX idx ON dt (c1, c2) include(ALL); 對于大部分業務來說,表裡有數十列是常态,個别表可能會有數百列。如果為了建備援索引,而把這數百列的列名再寫一遍,無疑是巨大的負擔(隻能寫工具自動化做,人來做太容易出錯)。全備援索引的新文法給人工維護DDL提供了可能。
為了獲得上述兩點收益,全備援索引的代價是會占用更多存儲空間。配合HBase增強版
深度優化的ZStandard壓縮算法,可有效降低備援帶來存儲開銷。冷熱分離特性亦可應用于索引表,進一步控制成本。
基于原生API的查詢優化
對大部分場景來說,業務一行代碼不改就能用上索引。
從本文開頭的示例代碼中可見:
- 寫:寫主表即可,會自動同步到索引,強一緻。使用者無需擔心索引更新的問題
- 讀:基于主表進行查詢,直接按業務邏輯進行查詢表達,系統自動選擇合适的索引表進行查詢
這樣,使用者隻需為那些性能不好的查詢設計并添加索引,即可從索引特性中受益,實際的資料讀寫代碼一般不需要修改。同時,既有的HBase生态相關的産品,都可以無縫使用上索引。一些如Spring的架構軟體也可幫助使用者獲得業務上的靈活性。
大表建索引
從一開始就設計好主表和全部索引幾乎是不可能的。是以,在後續業務發展過程中,索引表可能需要不斷的删除和新增。為此,對一個已經有大量資料表添加、删除索引,将是一個關鍵的運維操作。HBase增強版二級索引針對此場景做了特别的優化:
- schema線上修改:索引的變更不影響主表的正常讀寫(就像一次普通的alter表操作),不影響其他索引表
- 服務端rebuild:在服務端為主表的曆史資料建構索引
- 支援對超大主表添加索引:支援TB級别的主表添加新索引
- 流控:大主表的索引rebuild會消耗大量的系統資源,是以,精準的流控即可在兼顧索引建構速度的前提下,保障系統整體性能不會被影響
在有上述特性的加持下,索引變更的運維成本和風險大大降低,從容的适應業務發展。
原理簡介
HBase增強版二級索引是一種全局二級索引,每個索引表都是一張獨立的HBase表。每張表的主鍵(rowkey)設計決定了其能支援的查詢模式。當同一份資料有多種rowkey組織時,就能支援多種查詢模式。這裡,主表和它的索引表,可以看做是同一份資料的不同組織形式,各自能夠高效的支援一定的查詢模式。
考慮本文開始時給出的學生資訊表的示例:

主表Student:以學号(id)為主鍵(rowkey),每行有兩列,學生姓名(name)和所屬的學院(department)。該設計僅支援按id進行查詢。如果使用者要按department或者name來查詢,需要全表掃描 + filter。在學生數較少時,這種暴力掃描完全可行。但在資料量大時(數十萬乃至上億時),這種操作是無法執行的。
為了高效的支援按department查詢,可為其建立一個全備援索引(使用HBase shell):
create_index 'department', 'student', {INDEXED_COLUMNS => ['f:departement']}, {COVERED_COLUMNS => ['COVERED_ALL_COLUMNS']} 在建索引時,系統會自動為主表中的存量資料建構索引,寫入索引表中。主表行和索引行是一一對應的。之後主表上發生的資料更新,也會自動同步給索引表。
考慮如下查詢:
-- 查找所有計算機學院(cs)的學生的姓名(name)
select name from student where department = 'cs'; 這個查詢會直接命中索引表,按department列進行字首比對。從每一個索引行中提取name字段,傳回給用戶端。
如果我們沒有建立備援索引,則索引表中不會存在name列。此時,在從索引表中讀取到學号(id)後,必須回查主表(三次按id的單行讀)來讀取name列。在分布式場景下,10/12/13這三個id的資料可能分布在三台機器上。是以,回查主表最差情況下需要3次RPC,加上查索引表的一次RPC,共需4次RPC。而如果是備援索引,則隻需查索引表的一次RPC即可。
是以,在分布式場景,尤其是節點很多的大叢集,回查主表帶來的性能損耗是巨大的(RT可能會增長數倍)。這也是我們設計全備援索引的初衷:避免回查,提高性能。
總結
資料隻有被查詢才能創造價值,HBase原生高性能二級索引為多元度查詢提供了一種有效的解決方案。在表設計上,使用者可以參考MySQL等關系型資料庫的索引設計思路來進行HBase的索引設計。業務無需更改代碼,查詢優化可自動進行索引表的選擇。強一緻、全備援索引等特性也有效降低了業務的使用門檻。
未來,我們将對索引做進一步的優化和擴充,提供優質的使用者體驗。歡迎大家體驗HBase增強版。如您有對HBase相關的任何問題,歡迎通過釘釘與我們聯系(釘釘搜尋“雲HBase值班”)。
相關連結
HBase技術交流
歡迎加群進一步交流溝通: