注:本文為YIG團隊原創
1. Yet Another Index Gateway
YIG是S3協定相容的分布式對象存儲系統。它脫胎于開源軟體ceph,在多年的商業化運維中,針對運維中出現的問題和功能上的新需求,重新實作了一遍radosgw用于解決以下問題:
1) 單bucket下面檔案數目的限制
2) 大幅度提高小檔案的存儲能力
3) bucket下面檔案過多時,list操作延遲變高
4) 背景ceph叢集在做recovery或者backfill時極大影響系統性能
5) 提高大檔案上傳并發效率
2. Ceph對象存儲遇到的挑戰
本文假設讀者已經對ceph,ceph/radosgw或者分布式系統,和S3 API有所了解。在這裡不會詳細介紹 他們的特點和架構。
如果有不清楚的同學建議到ceph的官網了解一下。S3 API可以參考Amazon S3。
另外對象存儲都是大容量的情況,同時本文也預設所有存儲媒體都是普通的機械硬碟。其主要特點就是:順序IO快,随機IO特别慢。 - 2.1 Ceph Radosgw對象存儲系統
radosgw的架構如圖 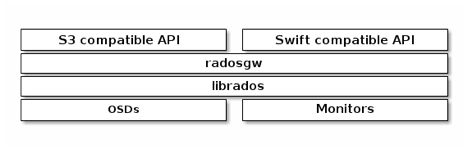 radosgw充分利用了librados底層的4類API完成資料存儲的目的,實際上radosgw用的是C++ API,但是這裡我們使用C API便于說明問題 1)rados_read/rados_write 這組API主要用來存儲對象的實際内容,他會根據使用者對象的名稱生産oid,然後映射到多個osd上,然後寫入實際資料,比較簡單,對應于rados指令行的 "rados put / get" 2) rados_write_op_omap_set / rados_read_op_omap_get_vals 這組API主要用來存儲bucket的中繼資料。每個ceph osd在初始化的時候會生産一個嵌入式的資料庫。(filestore對應leveldb,bluestore對應rocksdb。 通過這組API可以給object設定key-value值,這組API在radosgw裡面主要存儲重要的bucket下有哪些檔案。比如S3裡面有一個bucket叫document,裡面有3個檔案,名字分别是: A、B、C ,那麼對應的在.rgw.index的pool裡面會有一個document.XXXX,這裡面的XXXX是bucket的instance ID,他的omap對應的就是 KEY VALUE A value B value C value 在ceph的J版本之前,bucket下的檔案清單都是由一個object對應的omap記錄的,在後續的版本中加入bucket sharding的功能,讓檔案清單可以由多個嵌入式KV存儲記錄。 3) rados_getxattrs/rados_setxattrs這個API主要存儲每個對象的中繼資料,包括每個分片的資訊、ACL、contentType,這些資訊都用這組API存儲和讀取。它們對應的就是filestore的xfs使用的xattrs,或者bluestore的rocksdb裡面的kv對。 4) rados_exec 參考文檔cls,傳統上增删改查的操作并不一定滿足所有需求。比如需要一個計數器,原子的記錄一個object通路次數;或者需要在osd上計算一個object的md5,而不需要下載下傳到用戶端再進行計算。所有的cls操作都是對一個object原子的。使用者可以自己編寫cls plugins,在osd啟動的時候加載。之前隻能用c++寫,現在從J版本以後開始支援用lua寫的plugin了。radosgw使用這個API做原子的操作,或者記錄日志。 - 2.2 為什麼radosgw存儲小檔案會有性能問題
從上面的rados存儲原理可以看到,要在一個S3相容的系統裡存儲資料,它需要存儲 1) 資料本身 2) 中繼資料(ACL、contentType、分片資訊) 3) 修改bucket的中繼資料(bucket下面多了一個Key) 是以可以看出,盡管使用者隻上傳了一個幾百位元組的檔案,甚至還沒有一個sector大,但是ceph的多個osd都要發生寫操作。如果這是一個大檔案,比如4M,這些overhead就完全可以忽略。檔案越小,數量越大,硬碟的随機讀寫越多。 這種情況在filestore的情況尤其糟糕,filestore所有的寫入都先寫入自己的journal,然後在fflush到檔案系統。這種情況在bluestore會好一些,因為S3的寫入都是新檔案,沒有覆寫或者更新的情況,所有不用寫journal,資料直接落盤。 - 2.3 ceph在rebalance時,對線上環境是否影響很大
簡單的回答:很大 更精确的回答:主要跟遷移的資料量有關,遷移的資料量越大,影響也越大。 線上上一個50台伺服器的EC叢集上,萬兆網絡,容量超過50%,當掉一台伺服器(需要遷移6T資料),并且在預設的遷移線程個數的情況下,新的寫入IO速度隻有原來的10%。這時運維工程師通常的選擇是暫停rebalance,保證線上業務,在業務不忙的情況下,比如淩晨繼續遷移。 但是在停止rebalance的情況下,有部分pg處于degrade的狀态,比預想的副本數要少。但通常我們為了保證最優的資料可靠性,希望rebalance盡快完成,越快越好。此時的想法又和資料的可用性發生沖突,是為了資料可用性停服rebalance?還是為了資料可靠性降低可用性損失性能?線上上運維時,掌握這2點的平衡非常困難。 - 2.4 radosgw如何提升性能
3. YIG設計線上在使用ceph時還有其它的優化空間,遠遠不是調試ceph的參數那麼簡單,如: 1) 提升.rgw,.rgw.index 這些關鍵中繼資料pool的性能 中繼資料的重要性毋庸置疑。 從容量上看,中繼資料需要的容量很小。如果在叢集容量不足的情況下,可以采用中繼資料3副本,.buckets 2副本或者EC的政策。 從性能上看,提升中繼資料的存取速度可以極大的提升,是以通常都會把中繼資料的pool放到純SSD或者SAS盤的存儲媒體上。 2) 輔助功能外移,如日志和統計容量 我們線上上關閉radosgw的usage功能,也關閉了bucket index log(我們也不需要multi site)功能,本質上的思路就是在核心的讀寫流程上面減少環節,進而提升速度。比如日志統計之類的,都可以異步的把radosgw的日志推送到spark叢集計算。 3) 更好的cache 有些中繼資料是需要頻繁通路的,比如使用者資訊,bucket的中繼資料,這些資訊都需要radosgw做cache,但是由于radosgw之間不能直接通信,無法做invalid cache的操作,導緻cache的效率不高。社群的做法是利用共享存儲(這裡就是ceph的一個object),通過這個object通信,就可以打開cache. 這種情況在大流量的情況下,性能非常糟糕,我們線上上已經關閉了這個cache。
設計一個新的存儲系統解決以上問題,無非這些思路
a.隔離背景rebalance影響
b.根據haystack的論文,預設的filestore或者bludestore,并不特别适合小檔案存儲,需要新的存儲引擎
c.radosgw對librados提高的omap和cls用得太重,我們如何簡化架構,讓代碼更容易懂,也更不容易出錯。
d.更加統一的cache層,提高讀性能
架構如圖所見: 
從整體看,分為2層
1) S3 API layer,負責S3 API的解析和處理。所有中繼資料存儲在hbase中,中繼資料包括bucket的資訊,object的中繼資料(如ACL、contentType),multipart的切片資訊,權限管理,BLOB Storage的權值和排程,同時所有的中繼資料都cache在統一的cache層。這樣可以看到所有中繼資料都存儲在hbase中,并且有統一的cache,相比于radosgw大大提高的對中繼資料操作的可控性,也提高了中繼資料查詢的速度。
2) BLOB Storage層,可以并行的存在多個Ceph Cluster。隻使用 rados_read/rados_write的API。如果其中一個ceph cluster正在做rebalance,可以把它上面所有寫請求排程到其他ceph叢集,減少寫的壓力,讓rebalance迅速完成。從使用者角度看,所有的寫入并沒有影響,隻是到這個正在rebalance的ceph cluster上的讀請求會慢一點兒。 這種設計使得大規模擴容也變得非常容易,比如:初期上線了5台伺服器做存儲,使用過程中發現容量增加很快,希望擴容到50台,但是在原ceph叢集上一下添加45台新伺服器,rebalance的壓力太大。在yig的環境中,隻要建立一個45台的ceph叢集,接入yig的環境就行,可以快速無縫的靈活擴充。
- 4.1 在Ceph層提升性能
拆分方法如圖:1)使用libradosstriper API提升大檔案讀取寫入性能 對于大檔案,相比于radosgw每次使用512K的buf,用rados_write的API寫入ceph叢集,yig使用動态的buf,根據使用者上傳的速度的大小調整buf在(512K~1M)之間。并且使用rados striping的API提高寫入的并發程度。讓更多的OSD參與到大檔案的寫入,提高并發性能。

2)使用kvstore提升小檔案存儲性能
針對小檔案,直接使用kvstore存儲,底層使用rocksdb,這個方案相比于bluestore或者filestore更輕。性能更好。但是要注意2點:
a. 預設的kvstore并沒有打開布隆過濾器,需要在ceph的配置檔案中配置打開,否則讀性能會很差
b. 在Ceph的replicatePG層,每次寫object之前,都會嘗試讀取原object,然後再寫入。這個對于rbd這種大檔案的應用影響不大,但是對于小檔案寫入就非常糟糕。是以我們在rados的請求中加入的一個新的FLAG: LIBRADOS_OP_FLAG_FADVISE_NEWOBJ,在replicatedPG中會檢查是否有這個FLAG,如果有,就不會嘗試讀取不存在的小檔案。通過這個patch,可以極大的提升小檔案的寫入性能和降低cpu的使用率。