是一版免運維,穩定可靠,可彈性伸縮的線上時序資料庫服務,目前圍繞InfluxDB的TIG(Telegraf/InfluxDB/Grafana)生态和高可用服務版本已經商業化,可以在
阿裡雲官網直接購買。在日常業務中,使用者會比較關心兩個問題:
- 執行個體故障後,之前寫的資料會丢嗎?
- 你的服務能提供不間斷服務嗎,執行個體故障後能不能迅速恢複?
對于問題1,阿裡雲InfluxDB®底層采用了自研盤古分布式存儲系統,保證了資料99.9999999%的高可靠性;并且InfluxDB采用WAL機制來保障恢複重新開機執行個體中cache的寫入資料;
對于問題2,目前阿裡雲InfluxDB®采用了基于raft一緻性協定的三副本機制,當其中某個節點故障之後保證能夠持續提供資料寫入、查詢服務。
高可用相對于單機版本,能提供更高服務SLA保障。本文接下來也主要針對阿裡雲InfluxDB®高可用設計和Raft協定内部原理展開具體描述。
高可用架構設計
資料服務高可用目前似乎是軟體設計必要考慮要素。在實際的工程實踐中,基于需求有各種不同的解決方案,如SQL Server的share everything;Oracle RAC的share storage;GPDB/Spanner的share nothing架構;最近,基于kubenetes容器編排技術的高可用方案也越來越受歡迎。
Share everything/storage架構方案一般會被具有資深研發背景的資料庫廠商采用;在大部分網際網路初創公司或者資料庫産品發展的早期技術棧中,share nothing的分布式架構使用比較廣泛,它利用多副本機制來保障服務的可靠性,某個節點出現故障時,能迅速切換到備用節點繼續提供服務;容器編排技術通過将服務資源進行統一封裝管理,當節點故障之後能夠快速拉起繼續提供服務。
阿裡雲InfluxDB®的高可用架構設計中,也充分調研了各種技術方案:
一、基于共享存儲:各個執行個體通過挂載共享存儲,共享存儲在節點故障時不需要資料遷移,可以即時拉起,目前在計算存儲分離架構中運用比較多。對于有狀态的共享存儲服務,常常需要解決使用者态檔案緩存和記憶體cache資料同步問題,也要避免寫檔案沖突,需要引入類似GFS的分布式檔案系統,實作比較複雜。
二、Share nothing技術方案:Share nothing的各副本之間分為有角色管理和無角色管理兩種。為了保證各個副本資料一緻以及事務之間的隔離性,兩種技術方案在實作細節上有較大的不同。
- 無角色管理:無角色管理較為經典的有Dynamo的NWR模型,也稱寫多數協定,即在N個副本中需要至少寫W個副本才能标記寫入成功;對于讀操作一樣,查詢次數R要保證R>N-W,從R份查詢結果中找出資料的最新版本傳回。NWR協定存在儲存髒資料問題,InfluxDB Enterprise通過Anti-Entropy Repair技術對各個副本定期掃描修複來實作資料的最終一緻性,但實作複雜度比較高,具有高延遲和高資源消耗。
- 有角色管理:在左耳朵耗子的< 分布式系統的事務處理 >中,副本之前的角色主要分為M/S, M/M, Leader-Fellower等。M/S, M/M之間通過異步複制保證資料一緻性,M/S需要容忍節點間延遲以及故障恢複時服務的短暫中斷;M/M需要解決對同一條記錄更新的寫寫沖突,需要引入邏輯時鐘或者分布式鎖的概念,技術難度高。
在分布式協定發展的後期,為了實作故障恢複時Master、Slave之間角色的自動輪轉,實作了Paxos與Raft協定。本人覺得兩階段送出的Paxos與Raft協定同屬于一個技術棧,Raft協定相對來說更易了解,在Go技術棧中運用更為廣泛,故選取了Raft一緻性協定來實作高可用副本之間資料的一緻性問題。Raft協定的具體選舉算法可以參考Paper<
In Search of an Understandable Consensus Algorithm>以及譯文<
Raft 一緻性算法論文譯文>。Raft協定通過先寫資料記錄檔,然後回放Apply操作來保證各個節點間資料的一緻性。為了保證各個副本角色切換後Raft日志的一緻性,Raft在日志寫入和比對的時候保證了以下特性:
- 如果在不同日志中的兩個條目有着相同的索引和任期号,則它們所存儲的指令是相同的。
- 如果在不同日志中的兩個條目有着相同的索引和任期号,則它們之間的所有條目都是完全一樣的。
第一條保證了任意一條日志的索引位置建立後不會改變;第二條保證了新的Leader被選舉後,日志追加寫入時,其它Fellower節點需要檢查保證與Leader節點日志一緻。時序的應用場景中,在有大量寫入的業務中,需要保證寫入節點不可用之後服務快速恢複,作為公有雲服務,保證寫入資料不丢失和查詢的最終一緻性,并且Raft實作比較輕量,最終我們采用了Raft這一開源的分布式協定。
阿裡雲InfluxDB®高可用方案
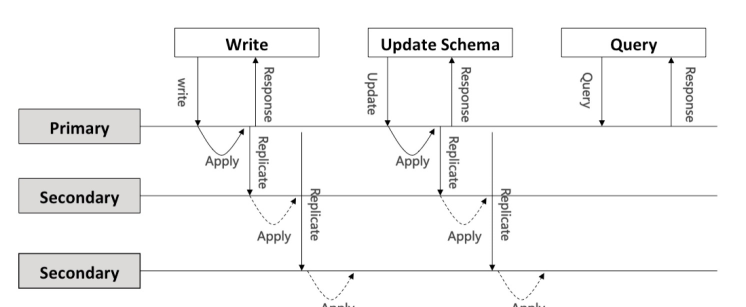
如上圖所示,阿裡雲InfluxDB的高可用架構側重于AP,對于資料/中繼資料的寫和更新,采用Raft一緻性協定;為縮短查詢流程,讀采用了弱一緻性。
- 中繼資料更新:為避免中繼資料髒寫以及資料庫元資訊與實際資料不對稱,中繼資料更新采用了串行執行的方案,apply之前必須保證其它所有操作Apply結束才進行中繼資料修改。
- 時間點寫入更新:為盡量減少節點間資料同步對寫入吞吐的影響,考慮到時間點資料較少存在寫沖突,對于時間點的寫入采用了并發apply模型。目前節點接收到資料之後會同步到leader節點,序列化raft entry log。raft内部通信子產品将這些entry log以message的方式批量同步到各個節點apply執行。目前阿裡雲InfluxDB®在請求接收點和master節點apply成功後便傳回給用戶端。
- 資料查詢:資料查詢類操作為縮短執行流程,采用了弱一緻性方案,沒有走raft流程,在請求節點執行成功後便傳回給用戶端。
Raft一緻性協定
關于raft的選舉算法,在各篇文章中有詳細的介紹,這裡便不再做具體描述,下面主要介紹raft資料寫入流程和資料存儲政策。
raft資料寫入流程

資料寫入流程如上圖所示:
- 若接收請求的節點(A)為follower節點,首先會将請求以message的形式發送到leader節點(B);
- leader節點(B)收到請求的raft entry log後,會将log序列化寫入存儲中;
- leader節點(B)raft内部的決策系統會輪循目前節點狀态和log同步進度,定期将raft log以批量的方式同步到fellower節點(A/C);
- fellower節點(A/C)收到leader節點(B)推送的資料後也會将entry log序列化存儲,并更新同步狀态,處理完後回複leader節點(B);
- 當leader節點收到所有fellower節點資料同步完成之後更新commit index并回複propose節點(A);
- 各節點的raft子產品并發掃描本地raft log entry 執行;
- 請求節點(A)apply 執行完成後傳回給用戶端。
raft storage
raft storage用于存儲raft log entry,raft log由以下成員組成:
- storage :存放已經持久化資料的storage接口,append資料将在此儲存。
- unstable ents:unstable結構體,用于儲存應用層還沒有持久化的資料。
- committed index:儲存目前送出的日志資料索引。
- applied index:儲存目前傳入狀态機的資料最高索引,索引之前的資料操作均已apply。
- firstIndex: 儲存了snapshot之後active raft log第一條日志的索引。
- lastIndex: 儲存了應用層持久化後的最後一條日志的索引。
- unstable.offset:為lastIndex索引的下一個索引值。
阿裡雲InfluxDB®高可用設計
replicate時,如果next标記的索引值介于snapshot和unstable.offset之間(firstIndex<=next<=lastIndex),則從leader的持久化日志中讀取entry進行同步;接着unstable ents也會發送到應用層storage中進行持久化;當storage持久化日志資料之後,便根據apply和commit資訊進行回放資料操作。
阿裡雲InfluxDB®為了實作raft log的持久化和故障可恢複,采用了自研的hybrid storage方案,詳細可以參考<
阿裡雲InfluxDB® Raft HybridStorage實作方案>。
總結
本文主要從工程實踐的角度出發,介紹了阿裡雲InfluxDB®高可用架構的實作以及raft内部機制。為了提高使用者服務的SLA,目前阿裡雲InfluxDB®高可用版本已經商業化,技術方案也在不斷的演進中。未來,我們将在降低使用成本、提高性能方面做進一步提升,希望對阿裡雲InfluxDB®或者高可用技術感興趣的同學能一起交流,共同打造一款服務能力更強、價格更低的阿裡雲InfluxDB®時序資料庫産品。