業務背景
信用評估是被目前社會廣泛關注的領域,特别是在金融行業,如果可以通過每個使用者的曆史交易資料以及使用者畫像資料确定使用者的個人信用,将有助于銀行設定個人借貸額度,确定潛在風險。本文将介紹在金融風控領域如何進行使用者畫像,使用什麼樣的算法可以計算出每個使用者的信用名額。
業務痛點
評分卡是金融領域經典的計算使用者信用的算法,目前許多金融機構缺少雲端可處理大規模樣本資料的評分卡算法。
解決方案
PAI平台提供了一套基于評分卡體系的分箱、樣本穩定性評估、評分模型訓練和評估算法
1.人力要求:需要具備基礎的評分卡模組化經驗
2.開發周期:1-2天
3.資料要求:最好有超過千條的打标資料,資料包含使用者曆史交易資料和基本使用者畫像
資料說明
資料來自國外真實脫敏後的銀行消費資料,一共包含30000條樣本,其中正常還款的6636個樣例,非正常還款23364個樣例
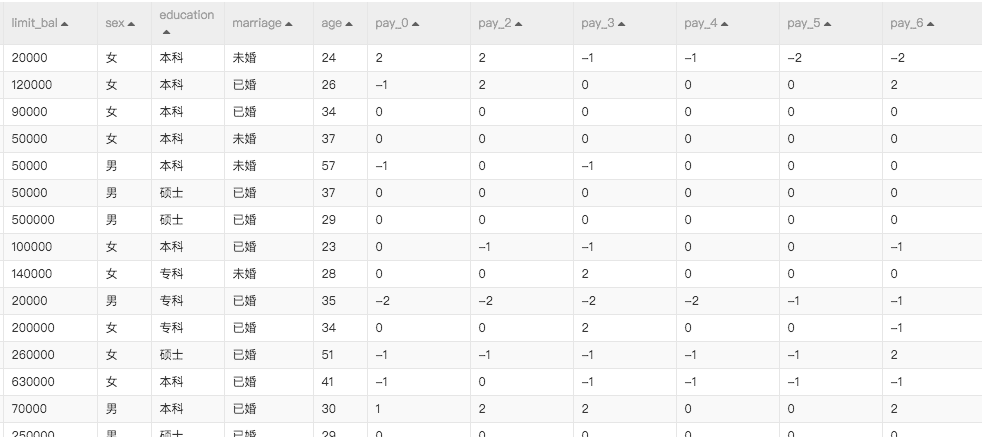
特征資料:
| 參數名稱 | 參數描述 |
|---|---|
| ID | 使用者ID |
| LIMIT_BAL | 目前使用者的額度 |
| SEX | 1是男,2是女 |
| EDUCATION | 1研究所學生,2大學,3高中生,其它 |
| MARRIAGE | 1結婚,2單身,3其它 |
| AGE | 年齡 |
| PAY_0 | 9月付款情況:-1 按時付錢,1遲付款一個月,2遲付款兩個月...... |
| PAY_2~PAY_6 | 同PAY_0,分拆每個月的付款情況 |
| BILL_AMT1~BILL_AMT6 | 每個月的具體賬單是多少 |
| PAY_AMT1~PAY_AMT6 | 上個月償還的金額是多少 |
目标資料:
| payment_next_month | 使用者是否還款,1是還款,0是未還款 |
流程說明
進入PAI-Studio産品:
https://pai.data.aliyun.com/console該方案資料和實驗環境已經内置于首頁模闆:

打開實驗:
1.拆分
将輸入資料集分為兩部分,一部分用來訓練模型,另一部分用來預測評估。
2.分箱
分箱元件類似于onehot編碼,可以将資料按照分布映射成更高次元的特征。以age字段為例,分箱元件可以按照資料在不同區間的分布進行分箱操作,分箱結果如圖所示。
最終分箱元件的輸出如下圖所示,每個字段都被分箱到多個區間上。
3.樣本穩定指數PSI
樣本穩定指數是衡量樣本變化所産生的偏移量的一種重要名額,通常用來衡量樣本的穩定程度。比如樣本在兩個月份之間的變化是否穩定。通常變量的PSI值在0.1以下表示變化不太顯著,在0.1到0.25之間表示變化比較顯著,大于0.25表示變量變化比較劇烈,需要特殊關注。
本案例中,綜合比較拆分前後以及分箱結果的樣本穩定程度,傳回每個特征的PSI數值,如下圖所示:
4.評分卡訓練
評分卡訓練的結果圖如下所示:
評分卡的精髓是将複雜的模型權重用符合業務标準的分數表示。
- intercepy:截距。
- Unscaled:原始的權重值。
- Scaled:分數更改名額,比如對于pay_0這個特征,如果特征落在(-1,0]之間分數就減29,如果特征落在(0,1]之間分數就加上27。
- importance:每個特征對于結果的影響大小,數值越大表示影響越大。
5.評分卡預測
每個預測結果的最終評分,本案例中表示的是每個使用者的信用評分。
總結
基于使用者的信用卡消費記錄,通過評分卡模型訓練及評分卡預測得到了每個使用者的最終信用評分,這個評分可以應用到各種貸款或者金融相關的征信領域中。