背景介紹
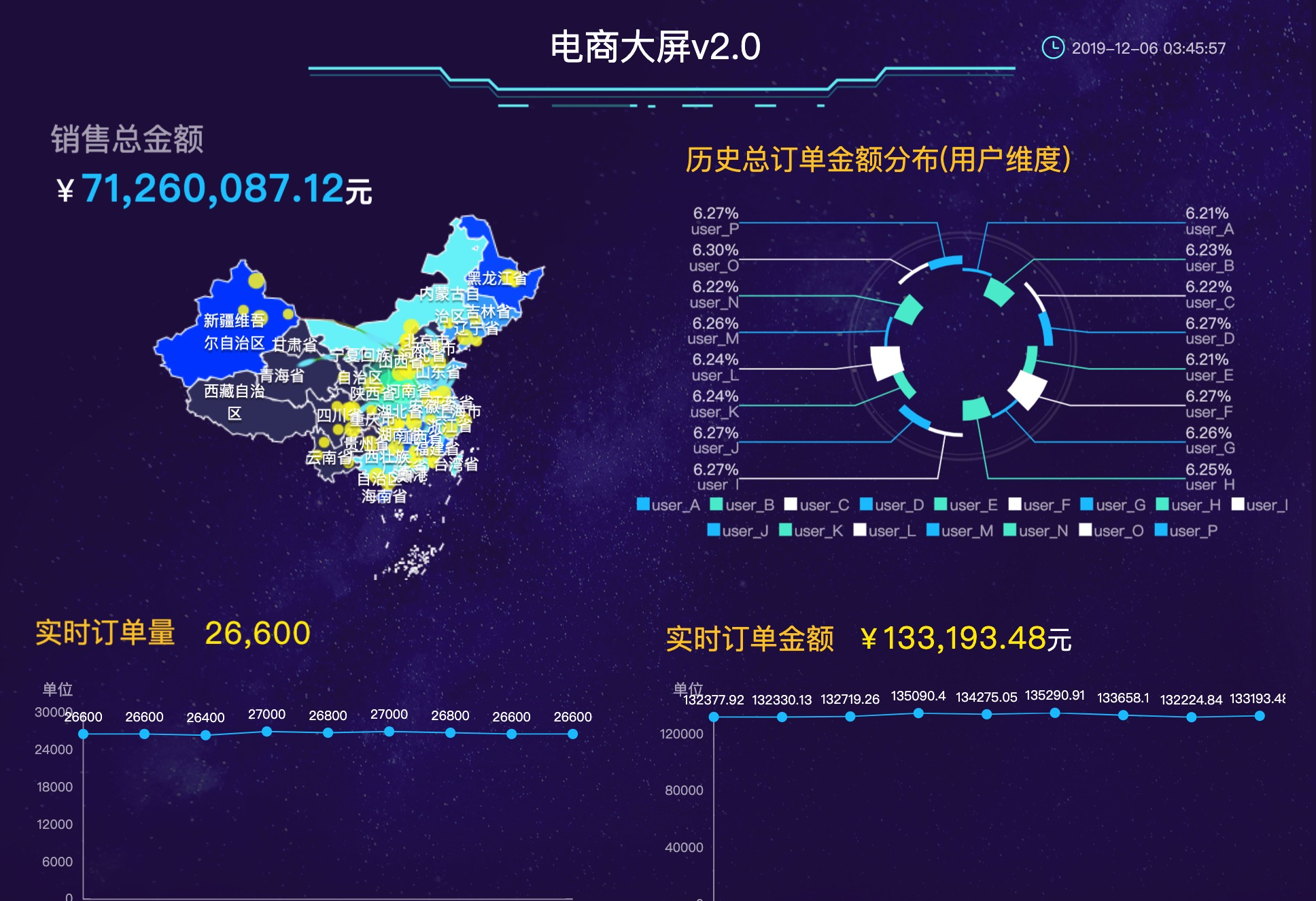
電子商務模式是指在網絡環境和大資料環境下基于一定技術基礎的商務運作方式和盈利模式,對于資料的分析和可視化是電商營運中最重要的部分之一,而電商大屏提供了資料分析和可視化的完美結合。電商大屏包含有全量訂單和實時訂單的聚合,全量訂單的聚合提供的是全景的綜合資料視圖,而實時訂單的聚合展示的是實時的營運名額資料。本文将通過結合Tablestore和Spark的流批一體存儲和計算,來自建電商大屏完成電商資料的分析和可視化,其效果圖如下。
架構設計
在本次的電商大屏實戰中,用戶端會實時向Tablestore插入原始訂單資料,實時流計算會通過Spark Structured Streaming實時統計一個視窗周期時間内的訂單數和訂單金額統計,并将聚合結果寫回Tablestore,最終在DataV大屏上進行展示,而離線批計算通過Spark SQL進行原始訂單資料的總金額和使用者次元總金額的離線聚合,聚合結果也會寫回Tablestore, 并最終在DataV大屏上進行展示,整個場景的架構圖如下圖所示。

準備工作
- 建立阿裡雲E-MapReduce的Hadoop叢集,文檔參見 建立叢集 。
- 下載下傳E-MapReduce的最新 SDK包 ,包名的格式為
emr-datasources_shaded_*.jar
資料源說明
資料源是一張簡單的原始訂單表OrderSource,表有兩個主鍵UserId(使用者ID)和OrderId(訂單ID)和兩個屬性列price(價格)和timestamp(訂單時間),資料示例如下圖所示。
批流SQL流程詳解
建立資料源表
1.登陸EMR Header機器,執行以下指令,啟動sql用戶端,該用戶端用于批流SQL計算,其中emr-datasources_shaded_*.jar為準備工作中下載下傳的EMR最新版的SDK包。
streaming-sql --driver-class-path emr-datasources_shaded_*.jar --jars emr-datasources_shaded_*.jar --master yarn-client --num-executors 8 --executor-memory 2g --executor-cores 2 2.建立原始訂單資料表(Source表)的外表order_source,該外表将用于後續的流批SQL執行。
DROP TABLE IF EXISTS order_source;
CREATE TABLE order_source
USING tablestore
OPTIONS(
endpoint="http://vehicle-test.cn-hangzhou.vpc.tablestore.aliyuncs.com",
access.key.id="",
access.key.secret="",
instance.name="vehicle-test",
table.name="OrderSource",
tunnel.id="2b7bbf3d-d6c4-4cea-89fe-71998bccaf19",
catalog='{"columns": {"UserId": {"col": "UserId", "type": "string"}, "OrderId": {"col": "OrderId", "type": "string"},"price": {"cols": "price", "type": "double"}, "timestamp": {"cols": "timestamp", "type": "long"}}}'
); 參數說明:
| 參數名 | 解釋 |
|---|---|
| endpoint | 表格存儲執行個體的通路位址 |
| access.key.id | 阿裡雲賬号AK ID |
| access.key.secret | 阿裡雲賬号AK Secret |
| instance.name | 表格存儲執行個體名 |
| table.name | 表格存儲表名 |
| tunnel.id | 表格存儲的增量通道ID, 該參數用于實時的增量SQL, 批量SQL時非必須。 |
| catalog | 表的字段Schema定義,上述示例中對應的四個列為UserId(主鍵), OrderId(主鍵), price, timestamp,資料類型分别為string, string, double, long。 |
實時流計算
實時流計算将實時統計一個視窗周期時間内的訂單數和訂單金額統計,并将聚合結果寫回Tablestore。首先建立流計算的Sink外表order_stream_sink(對應Tablestore表OrderStreamSink),然後運作流計算SQL進行實時聚合,最後将聚合結果實時寫回Tablestore目的表中。
Sink表的各參數含義和Source表一緻,其中catalog字段的内容有所不同,對應的Sink表中有四個字段,begin(開始時間,主鍵列,格式為2019-11-27 14:54:00),end(結束時間,主鍵列),count(訂單數),totalPrice(訂單總金額)。
// 建立Sink表order_stream_sink對應Tablestore的表OrderStreamSink(主鍵為begin和end兩列)
DROP TABLE IF EXISTS order_stream_sink;
CREATE TABLE order_stream_sink
USING tablestore
OPTIONS(
endpoint="http://vehicle-test.cn-hangzhou.vpc.tablestore.aliyuncs.com",
access.key.id="",
access.key.secret="",
instance.name="vehicle-test",
table.name="OrderStreamSink",
catalog='{"columns": {"begin": {"col": "begin", "type": "string"},"end": {"col": "end", "type": "string"}, "count": {"col": "count", "type": "long"}, "totalPrice": {"col": "totalPrice", "type": "double"}}}'
);
// 在order_source表上建立視圖order_source_stream_view
CREATE SCAN order_source_stream_view ON order_source USING STREAM OPTIONS ("maxoffsetsperchannel"="10000");
// 在視圖order_source_stream_view上運作STREAM SQL作業,以下樣例會按30s粒度進行訂單數和訂單金額的聚合,
// 聚合結果将寫回Tablestore表OrderStreamSink。
CREATE STREAM job1
options(
checkpointLocation='/tmp/spark/cp/job1',
outputMode='update'
)
INSERT INTO order_stream_sink
SELECT CAST(window.start AS String) AS begin, CAST(window.end AS String) AS end, count(*) AS count, CAST(sum(price) AS Double) AS totalPrice FROM order_source_stream_view GROUP BY window(to_timestamp(timestamp / 1000), "30 seconds"); 在運作Stream SQL後,可以實時得到聚合結果,聚合結果樣例如下圖所示,聚合結果存放在OrderStreamSink表中,通過Tablestore和DataV的
直連功能,可以很容易的将結果繪制在DataV的大屏上。
離線批計算
離線批計算将進行原始訂單資料的總金額和使用者次元總金額的離線聚合,首先會建立兩張Sink表分别存放曆史總金額和使用者次元總金額的聚合資料,然後直接在源表order_source上運作批計算SQL,最後得到聚合結果。
// 批計算任務
// 使用者次元結果表:OrderBatchSink(主鍵UserId, 屬性列count,totalPrice)
// 總資料次元結果表:OrderTotalSink(主鍵Count, 屬性列totalPrice)
DROP TABLE IF EXISTS order_batch_sink;
CREATE TABLE order_batch_sink
USING tablestore
OPTIONS(
endpoint="http://vehicle-test.cn-hangzhou.vpc.tablestore.aliyuncs.com",
access.key.id="",
access.key.secret="",
instance.name="vehicle-test",
table.name="OrderBatchSink",
tunnel.id="",
catalog='{"columns": {"UserId": {"col": "UserId", "type": "string"}, "count": {"col": "count", "type": "long"}, "totalPrice": {"col": "totalPrice", "type": "double"}}}'
);
DROP TABLE IF EXISTS order_totol_sink;
CREATE TABLE order_total_sink
USING tablestore
OPTIONS(
endpoint="http://vehicle-test.cn-hangzhou.vpc.tablestore.aliyuncs.com",
access.key.id="",
access.key.secret="",
instance.name="vehicle-test",
table.name="OrderTotalSink",
tunnel.id="",
catalog='{"columns": {"count": {"col": "count", "type": "long"}, "totalPrice": {"col": "totalPrice", "type": "double"}}}'
);
運作以下批計算SQL進行使用者次元聚合結果的更新。
// SQL指令
INSERT INTO order_batch_sink SELECT UserId, count(*) AS count, sum(price) AS totalPrice FROM order_source GROUP BY UserId;
// 實際運作
spark-sql> INSERT INTO order_batch_sink SELECT UserId, count(*) AS count, sum(price) AS totalPrice FROM order_source GROUP BY UserId;
Time taken: 5.107 seconds 運作以下批計算SQL進行總資料次元結果的更新。
// SQL指令
INSERT INTO order_total_sink SELECT count(*) AS count, sum(price) AS totalPrice FROM order_source;
// 實際運作
spark-sql> INSERT INTO order_total_sink SELECT count(*) AS count, sum(price) AS totalPrice FROM order_source;
Time taken: 4.272 seconds 寫在最後
本文通過使用一套存儲(Tablestore)和一套計算(Spark)完成了批流計算的有效結合,更多有關批流一體的細節和幹貨可以參見
Tablestore結合Spark的雲上流批一體大資料架構對Tablestore有任何問題,随時歡迎同我們進行交流,釘釘群号:11789671(1群)、23307953(2群)。