前言
在
Flink最佳實踐(一)流式計算系統概述中,我們詳細讨論了流式計算系統中 時域、視窗、時間推理與正确性工具 等概念。
本文将以這些概念為基礎,逐一介紹 Flink 的 發展背景、核心概念、時間推理與正确性工具、安裝部署、用戶端操作、程式設計API 等内容,讓開發人員對 Flink 有較為全面的認識并擁有一些基礎操作與程式設計能力。
一、發展背景
1.1 資料處理架構
在流處理器出現之前,資料處理架構主要由批處理器組成,其是對 無限資料的有限切分,具有 吞吐量大、資料較為準确 的特點。
然而我們知道,批處理器在時間切分點附近 仍然無法保證資料結果的真實性,且資料的時效性往往比較低,延遲大。
除了批處理之外,人們為了達到資料生成的高時效性,在資料處理架構中也常常使用微服務來解決,其特點是 延遲低、無狀态、服務與存儲分離。
但是微服務無狀态的限制很大程度上決定了其并不能很好的應用于現代實時資料處理的需求中,比如準确一次的語義、亂序資料流的處理能力等,它無法滿足人們對一個先進的流處理器的想象(在無狀态的業務需求中,微服務仍然是最佳選擇)。
而要滿足人們的這些想象,資料處理架構恰恰需要有 「狀态」 的概念和相應的機制支援才行。
由此 有狀态的流處理器 開始逐漸完善并大規模使用。
有狀态的流處理器依賴 高可用可重放的資料源,通過 State(狀态)提供準确一次的語義,通過 時間推理工具能夠還原真實世界的資料情況,廣泛應用于 事件驅動(實時警報)、資料管道(實時數倉)、資料分析(實時報表) 等業務場景中。
高可用可重放的資料源:
- 持久化的、隻添加的
- 寫入順序不可變
- 多個消費者多次消費
- 可信的資料源、可重放
1.2 開源分布式流處理器
開源流處理器在不斷地發展,從一開始隻關注低延遲名額到現在兼顧延遲、吞吐與結果準确性,在發展過程中解決了很多問題,程式設計API的易用性也在不斷地提高。
第一代
- 關注 毫秒級延遲 的事件處理
- 資料丢失與處理簡單,容易造成結果不夠精确
- 犧牲了部分的準确性來換取更低的延遲
- 隻有底層API接口
第二代
- 更好的容錯,確定在發生故障的時候僅僅處理一次
- 提供進階API程式設計接口
- 可能 犧牲延遲到秒級
- 結果取決于事件到達的順序
第三代
- 精準一次的語義,批流都可應用計算
- 兼顧延遲、吞吐與結果準确性
- 解決了依賴于時間和事件到達順序的問題
二、核心概念
了解完流處理器的發展背景後,我們來詳細讨論一下 Flink 中的核心概念,這些概念是學習與使用 Flink 十分重要的基礎知識,在後續開發 Flink 程式過程中将會幫助開發人員更好地了解 Flink 内部的行為和機制。
本節中相關核心概念摘抄自
,該文中對流處理器核心概念有詳細的讨論與說明,這裡不再過多累述。
2.1 Time(時間語義)
和其他流處理器一樣,Flink 中的 Time 也分為三種:事件時間、達到時間與處理時間。
事件時間
事件時間是 事件真實發生的時間。
由于資料亂序的原因,服務端收到資料時的時間和事件本身的時間可能是相差極大的。
正是因為這種差異,服務端做基于事件時間的計算是 最複雜的,需要對亂序的資料流做處理以 「還原」 真實世界的情況,需要依賴一定的資料緩存。
- 遲到與亂序處理
- 延遲較高
達到時間
達到時間是 系統接收到事件的時間,即服務端接收到事件的時間。
處理時間
處理時間是 系統開始處理到達事件的時間。
在某些場景下,處理時間等于達到時間。
因為處理時間 沒有亂序 的問題,是以服務端做基于處理時間的計算是比較簡單的,無遲到與亂序資料。
- 不需要考慮遲到和亂序
- 有較低的延遲
Flink 中隻需要通過
env
環境變量即可設定Time:
//建立環境上下文
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 設定在目前程式中使用 ProcessingTime
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); 2.2 Window(視窗)
在時間語義(時域)之上,對資料流的操作分為與時間無關的、與時間有關的兩種類型,其中與時間有關的操作都與視窗操作挂鈎。
基于各類時間的視窗處理 是流處理器中主要的與時間有關的操作,視窗本質就是将無限資料集 沿着時間的邊界切分成有限資料集。
沒有視窗,就沒法在時間次元上劃分資料集,也就沒法進行後續的資料操作。
在 Flink 中,當 屬于這個視窗的第一個元素到達時就會建立一個視窗。
當時間(事件或處理時間)超過視窗的結束時間戳加上使用者指定的最大允許延遲時間時,視窗就會被完全删除。
這就是 Flink 視窗的生命周期。
Flink 中的每個視窗都有一個 觸發器和執行函數:
- 觸發器定義視窗何時觸發
- 執行函數定義觸發時的計算邏輯
除此之外,視窗還可以定義一個 回收器,用來在 視窗觸發後、計算執行前(後) 排除或者回收指定的元素。
Keyed 與 Non-Keyed Windows
Flink 中有兩大類型的視窗:Keyed Windows 和 Non-keyed Windows,兩種類型的視窗操作API有細微的差别:
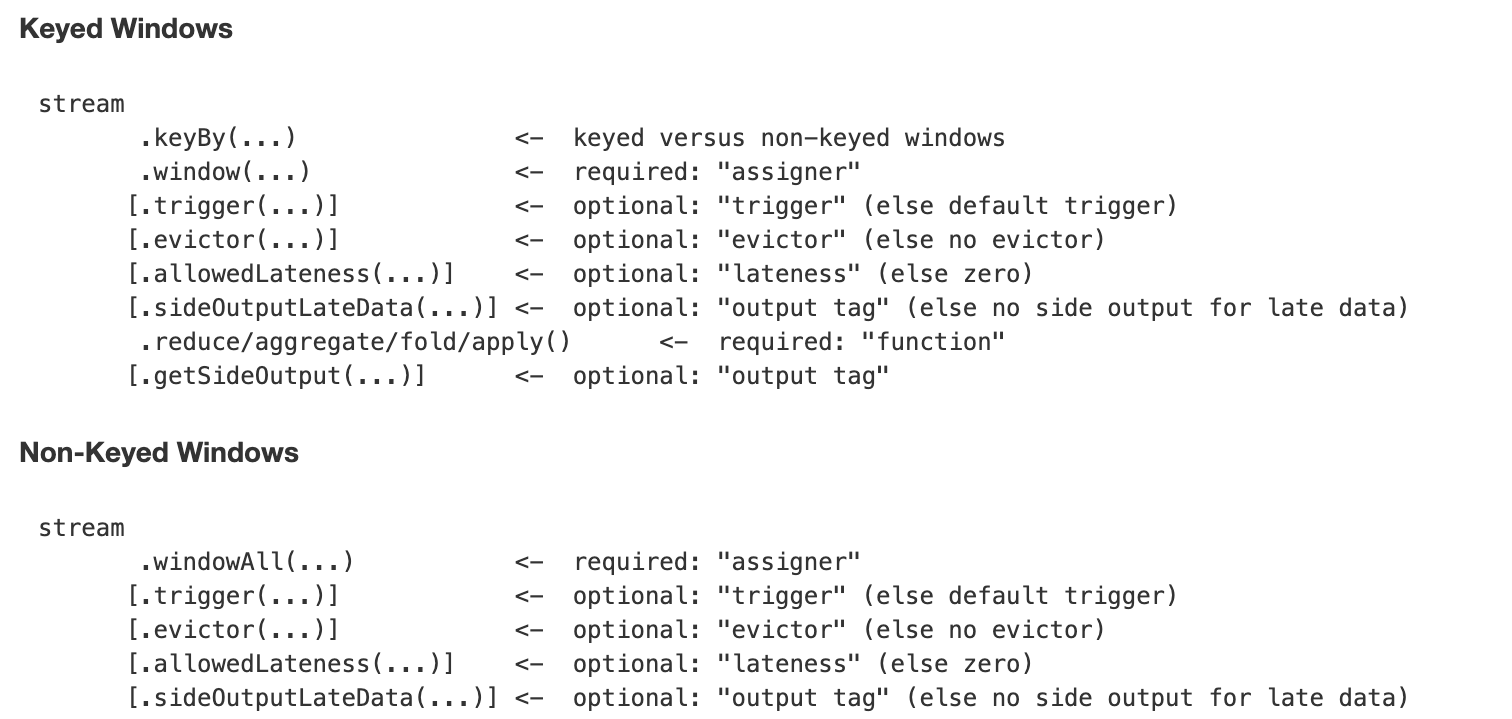
在 Keyed Windows 中,stream 需要通過
keyBy
和
window
方法生成,而在 Non-Keyed Windows 中,stream 隻需要通過
windowAll
方法即可生成。
在随後的API中兩者并沒有差異:
- trigger: 設定視窗觸發器,沒有設定則使用預設觸發器
- evictor: 設定視窗觸發後、計算執行前,前置的資料過濾器,沒有則無
- allowedLateness: 視窗允許的最大延遲,沒有則無
- sideOutputLateData: 擷取延遲的資料并可以使用
reduce/aggregate/fold/apply
- getSideOutput: 擷取延遲的資料
以上方法都是可選調用。
在定義視窗之前,開發人員必須先定義資料流是否根據key分組,使用
keyBy
函數即可将資料流劃分為 Keyed Stream,如果
keyBy
沒有被調用,則資料流為 Non-Keyed。
在 Keyed Stream 中,所有的資料都會根據指定的key配置設定到并行的流中,是以 Keyed Stream 可以進行高效的并行操作,相同key的資料将會被配置設定到相同的并行任務中。
在 Non-Keyed Stream 中,資料不會被分割成多個并行的邏輯流,即并行度為1。
2.3 State(狀态)與Checkpoint(檢查點)
Flink 中,狀态用于緩存 使用者資料、視窗資料、程式運作時狀态、資料源偏移量 等資訊,而檢查點則是 定期對狀态備份并提供恢複能力的機制。
正是因為有狀态與檢查點的支援,Flink才能做到:
- 備份與恢複、7 * 24小時運作的容錯
- 資料不重複不丢失,精準一次
- 資料實時産出不延遲
- 橫向擴充
- 資料之間有關聯,需要通過狀态滿足業務邏輯
- 系統狀态(視窗緩沖區)、使用者自定義狀态
2.4 一緻性保證
一緻性保證通常也被稱為一緻性語義,是流處理器的能力展現。
至多一次
- 事件可以被簡單的丢棄
- 等于「無保證」
- 可以得到近似的結果,盡可能低的延遲
至少一次
- 所有事件都會被處理,但是可能處理了多次
- 資料源可重放即可
- 可以得到近似的結果
僅僅一次
- 資料源需要支援重放
- 處理器需要保持狀态一緻
三、正确性與時間推理工具
Flink 中保持強正确性的工具是 State 和 Checkpoint,提供時間推理能力的工具是 Watermark 和 Trigger。
接下來我們來詳細讨論Flink中,這些工具是如何使用和實作的。
3.1 State
3.1.1 狀态類别
Flink 有兩種狀态提供給開發人員使用:Managed State 和 Raw State。
Managed State
Managed State 是由flink runtime管理來管理的,自動存儲、自動恢複,在記憶體管理上有優化機制。
且 Managed State 支援常見的多種資料結構,如value、list、map等,在大多數業務場景中都有适用之處。
總體來說是對開發人員來說是比較友好的,是以 Managed State 是 Flink 中最常用的狀态。
Managed State 又分為 Keyed State 和 Operator State 兩種。
Keyed State 隻能用在 KeyedStream 上的算子中,每個key對應一個state,可以通過flink runtimecontext通路。
支援的資料結構有:
- ValueState
- MapState
- AppendingState
等,其中 AppendingState 還有不同的子類實作,詳細的使用資訊可以參考
Flink官網。
而 Operator State 可用于所有算子(常用于Source),一個Operator執行個體對應一個State,支援的資料結構:List 等。
Raw State
Raw State 由使用者自己管理,需要序列化,隻能使用位元組數組的資料結構。
Raw State 的使用和次元都比 Managed State 要複雜,建議在自定義的Operator場景中酌情使用。
3.1.2 狀态存儲
Flink中狀态的實作有三種:MemoryState、FsState、RocksDBState。
三種狀态存儲方式與使用場景各不相同,詳細介紹如下:
MemoryStateBackend
- 構造函數:MemoryStateBackend(int maxStateSize, boolean asyncSnapshot)
- 存儲方式:State存儲于各個 TaskManager記憶體中,Checkpoint存儲于 JobManager記憶體
- 容量限制:單個State最大5M、maxStateSize<=akka.framesize(10M)、總大小不超過JobManager記憶體
- 使用場景:無狀态或者JobManager挂掉不影響的測試環境等,不建議在生産環境使用
FsStateBackend
- 構造函數:FsStateBackend(URI checkpointUri, boolean asyncSnapshot)
- 存儲方式:State存儲于 TaskManager記憶體,Checkpoint存儲于 外部檔案系統(本次磁盤 or HDFS)
- 容量限制:State總量不超過TaskManager記憶體、Checkpoint總大小不超過外部存儲空間
- 使用場景:正常使用狀态的作業,分鐘級的視窗聚合等,可在生産環境使用
RocksDBStateBackend
- 構造函數:RocksDBStateBackend(URI checkpointUri, boolean enableincrementCheckpoint)
- 存儲方式:State存儲于 TaskManager上的kv資料庫(記憶體+磁盤),Checkpoint存儲于 外部檔案系統(本次磁盤 or HDFS)
- 容量限制:State總量不超過TaskManager記憶體+磁盤、單key最大2g、Checkpoint總大小不超過外部存儲空間
- 使用場景:超大狀态的作業,天級的視窗聚合等,對讀寫性能要求不高的場景,可在生産環境使用
根據業務場景需要使用者選擇最合适的 StateBackend ,代碼中隻需在相應的 env 環境中設定即可:
// flink 上下文環境變量
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 設定狀态後端為 FsStateBackend,資料存儲到 hdfs /tmp/flink/checkpoint/test 中
env.setStateBackend(new FsStateBackend("hdfs://ns1/tmp/flink/checkpoint/test", false)) 3.1.3 狀态儲存與遷移
Flink 中将會按照使用者的設定,定時執行 Checkpoint 對狀态進行備份,這是 Flink 的自動儲存機制。
除了自動儲存之外,Flink 還提供了 Savepoint 的手動儲存方式:
# flink指令行工具中手動觸發savepoint
bin/flink savepoint -m 127.0.0.1:8081 任務id /tmp/savepoint Savepoint 是一種手動觸發執行的 全量Checkpoint,其會立即在目前資料中插入checkpoint barrier,立即生産快照備份。
隻要 Checkpoint 的快照備份資訊存在,則 Flink 程式就可以根據這份資料進行遷移改造等操作。

3.2 Checkpoint
Checkpoint 是分布式全域一緻的,資料會被寫入hdfs等共享存儲中。且其産生是 異步的,在 不中斷、不影響運算 的前提下産生。
首先,Flink 會在資料源設定一系列的 checkpoint barrier,預設間隔n毫秒在資料流中插入一個 barrier 點。
ck barrier n 與 ck barrier n-1 之間的資料都屬于目前的checkpoint。
ck barrier n經過第一個op(算子操作)時向ck後端儲存 source offset 的資訊。
此時,ck後端中的 Checkpoint 資訊可以簡化為下表:
随着資料在程式算子中流動,ck barrier n 會慢慢傳播到每個op中。
經過後續每個op時:
- ck barrier n到達之前,會用input buffer緩存之前的資料集
- ck barrier n到達之後表示目前所屬的所有資料已經處理完成并更新狀态
- 将目前op的狀态儲存至ck後端
此時ck後端中的 Checkpoint 資訊如下:
ck barrier n經過最後的sink op時向ck後端确認ck完整性,所有節點将「資料讀取的位置」與「目前狀态快照」寫入共享的dfs。
當任務失敗時,所有節點從dfs中讀取「上次的資料位置」來重置消息隊列,并從「上次的狀态」開始重新計算即可。
同 State 一樣,使用者隻需在相應的 env 環境中設定即可:
// 1000毫秒進行一次 Checkpoint 操作
env.enableCheckpointing(1000)
// 模式為準确一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 兩次 Checkpoint 之間最少間隔 500毫秒
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 過程逾時時間為 60000毫秒,即1分鐘視為逾時失敗
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 同一時間隻允許1個Checkpoint的操作在執行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) 3.3 Watermark
Flink 程式并 不能自動提取資料源中哪個字段/辨別為資料的事件時間,進而也就無法自己定義 Watermark 。
開發人員需要通過 Flink 提供的 API 來 提取和定義 Timestamp/Watermark,可以在 資料源或者資料流中 定義。
3.3.1 自定義資料源設定 Timestamp/Watermark
自定義的資料源類需要繼承并實作
SourceFunction[T]
接口,其中
run
方法是定義資料生産的地方:
//自定義的資料源為自定義類型MyType
class MySource extends SourceFunction[MyType]{
//重寫run方法,定義資料生産的邏輯
override def run(ctx: SourceContext[MyType]): Unit = {
while (/* condition */) {
val next: MyType = getNext()
//設定timestamp從MyType的哪個字段擷取(eventTimestamp)
ctx.collectWithTimestamp(next, next.eventTimestamp)
if (next.hasWatermarkTime) {
//設定watermark從MyType的那個方法擷取(getWatermarkTime)
ctx.emitWatermark(new Watermark(next.getWatermarkTime))
}
}
}
}
3.3.2 在資料流中設定 Timestamp/Watermark
在資料流中,可以設定 stream 的 Timestamp Assigner ,該 Assigner 将會接收一個 stream,并生産一個帶 Timestamp和Watermark 的新 stream。
Timestamp Assigner 通過 DataStream 的
assignTimestampsAndWatermarks
方法設定:
val withTimestampsAndWatermarks: DataStream[MyEvent] = stream
.assignTimestampsAndWatermarks(new MyTimestampsAndWatermarks()) assignTimestampsAndWatermarks
的參數可以接收兩種接口類型的子類:
AssignerWithPeriodicWatermarks
- 周期性生成watermark(可能根據流中的元素,也可能根據處理時間)
- 該實作的
getCurrentWatermark
ExecutionConfig.setAutoWatermarkInterval
- 當傳回的watermark不為空且比目前watermark大的話,該watermark會被使用
class BoundedOutOfOrdernessGenerator extends AssignerWithPeriodicWatermarks[MyEvent] {
//最大允許的亂序範圍
val maxOutOfOrderness = 3500L // 3.5 seconds
//目前最大時間戳
var currentMaxTimestamp: Long = _
//提取資料源中的timestamp
override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = {
val timestamp = element.getCreationTime()
//設定目前最大時間
currentMaxTimestamp = max(timestamp, currentMaxTimestamp)
timestamp
}
//擷取目前watermark,将會被 ExecutionConfig.setAutoWatermarkInterval 定義的時間定時調用
override def getCurrentWatermark(): Watermark = {
//設定watermark為目前最大時間戳-最大允許的亂序範圍
new Watermark(currentMaxTimestamp - maxOutOfOrderness)
}
} AssignerWithPunctuatedWatermarks
- 先調用
extractTimestamp
- 然後馬上調用
checkAndGetNextWatermark
-
checkAndGetNextWatermark
- 當
checkAndGetNextWatermark
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[MyEvent] {
//提取資料源中的timestamp
override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = {
element.getCreationTime
}
override def checkAndGetNextWatermark(lastElement: MyEvent, extractedTimestamp: Long): Watermark = {
//根據上一條資料和目前的timestamp判斷是否生成以及如何生成watermark
if (lastElement.hasWatermarkMarker()) new Watermark(extractedTimestamp) else null
}
} 需要注意的是,使用
AssignerWithPunctuatedWatermarks
雖然可以做到每條資料都生成watermark并使用,但是因為watermark會産生相應的計算處理,數量巨大的watermark将會影響到系統的性能,是以應該盡量避免出現大量的watermark。
3.3.3 預定義的 Assigner
AscendingTimestampExtractor
Flink中内置了集中預定義的 Assigner ,可以直接在特定場景中直接使用。
例如,在時間戳隻會一直增加的場景中,任意事件的時間都可以被當做watermark,因為不會有更早的時間戳出現,比如在多分區的kafka隊列中,不要求所有分區全局都是升序,隻要各個分區中的時間戳是升序的即可。
在這種場景中,Flink 的watermark合并機制将會正确的生成watermark,無論多個分區的資料流是在進行shuffle或者合并、連接配接等其他操作。
DataStream<MyEvent> stream = ...
DataStream<MyEvent> withTimestampsAndWatermarks =
//使用預定義的升序時間戳 Assigner
stream.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<MyEvent>() {
@Override
public long extractAscendingTimestamp(MyEvent element) {
//直接指定資料源中的時間戳字段即可
return element.getCreationTime();
}
}); BoundedOutOfOrdernessTimestampExtractor
在另外一種場景中,可以設定 允許固定最大時間範圍内的延遲,比如固定時間間隔中周期性發送資料的資料源,因為資料發送的間隔是固定的,是以可以設定一個固定的最大允許延遲時間。
DataStream<MyEvent> stream = ...
DataStream<MyEvent> withTimestampsAndWatermarks =
//使用預定義的時間戳 Assigner 并設定最大允許的延遲時間範圍
stream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<MyEvent>(Time.seconds(10)) {
@Override
public long extractTimestamp(MyEvent element) {
return element.getCreationTime();
}
}); Flink 中内置的 Assigner 是 使用者自定義實作 Assigner 的絕佳參考,建議參閱自定義 Assigner 的實作源代碼,可幫助開發人員對自定義 Assigner 的了解,相關代碼位于
org.apache.flink.streaming.api.functions.timestamps
包下。
3.4 Trigger
3.4.1 自定義觸發器
觸發器決定了視窗何時會被觸發計算,Flink 中開發人員需要在
window
類型的操作之後才能調用
trigger
方法傳入觸發器定義。
Flink 中的觸發器定義需要繼承并實作
Trigger
接口,該接口有以下方法:
- onElement(): 每個被添加到視窗中的元素都會被調用
- onEventTime(): 當事件時間定時器觸發時會被調用,比如watermark到達
- onProcessingTime(): 當處理時間定時器觸發時會被調用,比如時間周期觸發
- onMerge(): 當兩個視窗合并時兩個視窗的觸發器狀态将會被調動并合并
- clear(): 執行需要清除相關視窗的事件
以上方法會傳回決定如何觸發執行的
TriggerResult
:
- CONTINUE: 什麼都不做
- FIRE: 觸發計算
- PURGE: 清除視窗中的資料
- FIRE_AND_PURGE: 觸發計算後清除視窗中的資料
3.4.2 預定義觸發器
如果開發人員未指定觸發器,則 Flink 會自動根據場景使用預設的預定義好的觸發器。
在基于事件時間的視窗中使用
EventTimeTrigger
,該觸發器會在watermark通過視窗邊界後立即觸發(即watermark出現關閉改視窗時)。
在全局視窗(GlobalWindow)中使用
NeverTrigger
,該觸發器永遠不會觸發,是以在使用全局視窗時使用者需要自定義觸發器。
其他預定義觸發器還有如下:
- ProcessingTimeTrigger: 基于處理時間的觸發器
- CountTrigger: 根據視窗中元素數量的觸發器
- PurgingTrigger: 接收一個觸發器,并将其轉為帶Purge類型的觸發器
同樣,預定義的觸發器也是開發人員學習觸發器如何定義與使用的最佳案例,相關源代碼位于
org.apache.flink.streaming.api.windowing.triggers
四、安裝部署
目前為止,我們掌握了 Flink 中的一些基本的理論概念。接下來,在動手開發之前擁有一個 Flink 叢集是第一步。
本章将介紹 Flink 叢集幾種不同的部署模式供開發人員參考使用。
4.1 叢集架構
在介紹部署方式之前,我們有必要先了解一下 Flink 叢集的部署架構和節點組成。
Flink 叢集也是采用 Master-Slaves 式的結構,由一個(或者多個)Master管理多個Slaves。
叢集中的角色主要有三個:JobManager、TaskManager以及Client。
Client
開發人員編寫的代碼會被 Client 打包處理并送出到 JobManager 中。
Client 可以控制叢集中送出的作業,如檢視資訊、結束作業等操作。
Client 可以是任意擁有 Flink 環境的節點,隻要其能夠連上 JobManager 服務即可。
JobManager
Flink 中的 Master 節點稱為 JobManager,具有以下功能:
- 接收 Client 發出的作業操作請求
- 根據使用者代碼生成優化後的執行計劃(Execution Graph)
- 排程執行計劃到各個子節點執行
- 協調子節點做 Checkpoint 等任務
TaskManager
Flink 中的 Slave 節點稱為 TaskManager,具有以下功能:
- 子節點上 Memory & IO & Network 等資源管理
- 定期向 JobManager 彙報節點狀态、任務與資源等情況
- 接收 JobManager 配置設定的執行計劃并執行具體計算任務
4.2 本地單節點模式
這是最簡單的 Flink 安裝部署方式。
在官網
下載下傳指定版本的 Flink 發型包到本地并解壓。
進入 Flink 解壓縮目錄中執行:
./bin/start-cluster.sh 即可啟動一個最簡單的 Flink 程序,可以通過
http://127.0.0.1:8081/通路 JobManager 界面。
4.3 Standalone HA 模式
建議線上使用的 Flink 叢集至少是 Standalone HA 模式的,能夠保證 JobManager 是高可用的,避免 JobManager 當機導緻整個叢集失效。
Flink 叢集的 HA 需要 Zookeeper 的支援,Flink 的發型包中自帶了 Zookeeper,可以通過以下指令啟動:
./bin/start-zookeeper-quorum.sh 在 conf/zoo.cfg 檔案中預設配置好了本地啟動的 Zookeeper
# The port at which the clients will connect
clientPort=2181
# ZooKeeper quorum peers
server.1=localhost:2888:3888
# server.2=host:peer-port:leader-port Zookeeper 設定完畢後,需要編輯以下檔案并同步到所有要安裝的節點中:
- masters: 記錄master節點的檔案
- slaves: 記錄slave節點的檔案
- flink-conf.yaml: 使用外部zk需要修改以下兩個配置為對應zk資訊
- high-availability: zookeeper
- high-availability.zookeeper.quorum: localhost:2181
強烈建議使用外部 Zookeeper。
最後,檢查 JAVA_HOME 環境變量是否已經正确設定。
配置完畢後将 Flink 發型包中的檔案同步到各個節點中,啟動叢集即可:
./bin/start-cluster.sh 4.4 Yarn 模式
Yarn 模式是生産環境中 Flink 最常應用的模式之一,其可以直接 複用現有 Yarn 叢集的資源與排程能力,做到無縫內建,不用再單獨部署 Flink 叢集,直接向 Yarn 叢集送出 Flink 任務即可。
Flink 內建 Yarn 叢集的方式很簡單,隻需要在 Flink 節點上配置環境變量使 Flink 程式可以讀取 Yarn 的相關配置即可:
- YARN_CONF_DIR
- HADOOP_CONF_DIR
Flink 送出任務時将會根據執行模式自動比對并尋找 Yarn 叢集的資訊并送出任務。
Yarn Session
Yarn Session 模式會先在 Yarn 叢集上送出一個 Flink 任務資訊,這個 Flink 任務可以看做是一個簡單的 Flink 叢集,裡面運作了 JobManager、TaskManager 等節點,稱之為 Yarn Session。
Yarn Session 是以長駐的形式 長期運作在 Yarn 叢集中,它和普通的 Flink 叢集一樣,可以接受用戶端送出的 Flink 任務并運作,一個 Yarn Session 可以執行多個 Flink 任務。
簡單來說就是運作在 Yarn 叢集中的 Flink 叢集。
啟動一個 Yarn Session :
# 啟動4個container(運作TaskManager,記憶體4096m)、1個appmaster(運作JobManager,記憶體1024m)
./bin/yarn-session.sh -n 4 -jm 1024m -tm 4096m Yarn Session 啟動後,AppId 會被寫入
/tmp/.yarn-properties-${user}
中。
向 Yarn Session 送出 Flink 任務:
./bin/flink run examples/streaming/WordCount.jar --input hdfs:///test_dir/input_dir/story --output hdfs:///test_dir/output_dir/output flink 指令将會自動尋找 /tmp 路徑下 Yarn Session 的 AppId,使用者也可以通過
-yid
選項手動指定 AppId 資訊。
Yarn Session 在分組送出測試 Flink 任務的場景下十分友善,不同的小組使用不同的 Yarn Session 互不影響,且統一管理與限制資源的使用,對于每個使用者來說,其面對的都是一個完整的 Flink 叢集。
Single Job
除了 Yarn Session 之外,Flink 還可以直接向 Yarn 叢集送出單獨的任務,運作完成即刻銷毀并釋放資源(就像 Spark 一樣)。
向 Yarn 叢集送出單獨的任務:
./bin/flink run -m yarn-cluster -yn 2 examples/streaming/WordCount.jar --input hdfs:///test_dir/input_dir/story --output hdfs:///test_dir/output_dir/output 任務送出成功之後,可以在 Yarn 叢集中通過 App 清單檢視任務詳細資訊,也可以通過 AppId 管理任務。
Single Job 比較适合正式上線後的生産任務,獨占運作資源保證運作的穩定。
除了 Yarn 之外,Flink 還支援 Mesos、Docker、K8S、AWS 等不同環境的安裝部署,可以參考
官方文檔-deployment五、用戶端操作
擁有 Flink 叢集後,我們可以馬上進行上手實踐。
Flink 提供了豐富的用戶端操作來送出任務、與任務進行互動,下面将簡單介紹 Flink 中兩種最常用的用戶端應用。
5.1 CommandLine
Flink 指令行執行程式為
bin/flink
該程式中 Flink 任務操作的所有功能,如前文中用到任務送出指令:
./bin/flink run examples/streaming/WordCount.jar --input hdfs:///test_dir/input_dir/story --output hdfs:///test_dir/output_dir/output 任務送出之後可以繼續檢視叢集上的任務情況:
# 檢視任務清單
bin/flink list -m 127.0.0.1:8081
# 停止某個任務,安全關閉source與task
bin/flink stop -m 127.0.0.1:8081 任務id
# 立即取消某個任務并設定savepoint,暴力中斷
bin/flink stop -m 127.0.0.1:8081 -s /tmp/savepoint 任務id
# 手動觸發savepoint
bin/flink savepoint -m 127.0.0.1:8081 任務id /tmp/savepoint
# 從指定的savepoint中恢複
bin/flink run -d -s /tmp/savepoint/savepoint-xxx ./e
xamples/streaming/TopSpeedWindowing.jar 更多參數與功能可以通過
bin/flink -h
來檢視使用的幫助資訊。
5.2 Scala Shell
Scala Shell 提供了一個 REPL 環境給使用者,即時執行代碼,所見即所得,對于實驗類的驗證測試過程十分有用。
Scala Shell 啟動需要連接配接到一個遠端叢集或者本地環境,這裡以遠端叢集為例:
# 遠端叢集可以是獨立的 flink 叢集,也可以是 yarn session 模式的叢集
bin/start-scala-shell.sh remote jm的ip位址 jm的ip端口 除了連接配接到遠端叢集外,Scala Shell 還可以直接向 Yarn 叢集申請資源送出執行任務:
bin/start-scala-shell.sh yarn -n 2 -jm 1024 -s 2 -tm 1024 -nm flink-yarn 打開 Scala Shell 之後,這個所見即所得的世界就是你的了,Just Do It.
除了最常用的指令行與REPL環境,Flink 還提供了諸如 SQL Client、Restful Api、Web界面等用戶端應用,開發人員可以通過 SQL Client 進行sql測試,使用 Restful Api 進行送出與管理任務等操作。
六、程式設計API
6.1 API 概述
Flink 提供了幾種不同層次的 API 給開發人員使用,分别是:SQL API、Table API、Datastream 與 ProcessFunction。
如下圖所示:
越上層的API易用性與簡潔性越強,但是表達能力越弱。反之,越下層的API表達能力越強,但是易用性與簡潔性越弱。
SQL/Table API 是 Flink 中最進階的 API,通常用于資料分析的場景,表達能力能與 SQL 或者 Python的DataFrame 相媲美。
具有以下特點:
- 聲明式:使用者隻關心做什麼,不用關心怎麼做
- 高性能:支援查詢優化,可以擷取更好的執行性能
- 流批統一:相同的統計邏輯,既可以流模式運作,也可以批模式運作
- 标準穩定:語義遵循SQL标準,不易變動
- 易了解:語義明确,所見即所得
Table API 和 SQL API 的差別在于後者是前者的子集,也就是說 SQL API 能夠實作的功能 Table API 都能實作反之則不行,但是正如前面所說的,Table API 的易用性并不如 SQL API。
而 Datastream API 是能夠直接操作資料流的API,在 Datastream 中可以對 時間和視窗 進行操作。
ProcessFunction 是 Flink 中最底層的 API,能夠直接操作 事件、狀态與時間。
簡而言之,無論是 Flink 還是 Spark 程式設計,其都可以看成是在畫一個任務執行的DAG圖,圖中有并行有串行,有一對一的Task,也有多對多的 Shuffle Task。
和 Spark 不同的是,Flink 中的資料交換政策比較多樣:
- global: 全部發往第一個task
- broadcast: 所有task廣播
- forward: 上下遊并行度一樣時一對一發送
- shuffle: 随機均勻配置設定
- rebalance: 全部task輪流配置設定
- recale: 本地task輪流配置設定
- partitionCustom: 自定義單點傳播
6.2 Window API
在 Flink 中使用視窗的步驟為:
- 定義是否為 Keyed Stream
- 定義 Window Assigners
- 定義 Window Functions
- 定義可選調用的API
6.2.1 Window Assigners
在确認你的流是是 Keyed 還是 Non-Keyed 之後,開發人員需要通過 window(Keyed) 或者 windowAll(Non-Keyed) 來為視窗指定 Assigners,Assigners 定義了 如何将元素配置設定給視窗。
Flink 中内置了多種 Window Assigners 如建立 tumbling windows, sliding windows, session windows 和 global windows 等視窗的 Assigner。
基于不同的時間類型,這些 Assigner 有不同的實作,并 根據指定時間将元素配置設定給視窗。
開發人員可以參考以上的内置實作來定義自己的 Assigner,源碼包位于
org.apache.flink.streaming.api.windowing.assigners
以下 Assigners 使用 Demo 來自
Tumbling Windows:
val input: DataStream[T] = ...
// tumbling event-time windows
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// tumbling processing-time windows
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>) Sliding Windows:
val input: DataStream[T] = ...
// sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// sliding processing-time windows
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// sliding processing-time windows offset by -8 hours
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>) Session Windows:
val input: DataStream[T] = ...
// event-time session windows with static gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// event-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
.<windowed transformation>(<window function>)
// processing-time session windows with static gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// processing-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
.<windowed transformation>(<window function>) Global Windows:
val input: DataStream[T] = ...
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>) 6.2.2 Window Functions
定義好 Window Assigners 之後,開發人員需要在視窗和資料之上定義執行計算的 Window Functions。
ReduceFunction
可以遞增地聚合視窗的元素,是個高效的操作:
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce { (v1, v2) => (v1._1, v1._2 + v2._2) } AggregateFunction
AggregateFunction 是 ReduceFunction 的底層版本,也可以遞增地聚合視窗的元素,但是其可以讓開發人員更加靈活的定義計算,同時也意味着其實用比較複雜。
AggregateFunction 有三個泛型參數:輸入類型、累加器類型和輸出結果類型,Demo 如下:
/**
* The accumulator is used to keep a running sum and a count. The [getResult] method
* computes the average.
*/
//輸入類型為(String, Long),累加器類型為(String, Long),輸出類型為Double
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
//初始化累加器
override def createAccumulator() = (0L, 0L)
//累加器計算
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
//擷取結果,從累加器中計算,不需要緩存所有資料
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
//合并兩個累加器的結果
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate) FoldFunction:
fold()
方法指定 輸入的資料如何和之前的輸出結果相計算,該方法會在每個資料進入視窗之後馬上進行計算。
第一個進入視窗的元素(沒有上一個輸出結果的情況下),将會與一個使用者指定的初始值相計算。
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.fold("") { (acc, v) => acc + v._2 } 需要注意的是,
fold()
方法不能在 Session Window 等可合并的視窗中使用。
ProcessWindowFunction
擷取一個包含視窗的所有元素的Iterable,以及一個可以通路時間和狀态資訊的上下文對象,這使得它比其他視窗函數提供了更大的靈活性。這是以性能和資源消耗為代價的,因為元素不能增量地聚合,而是需要在内部進行緩沖,直到視窗準備好處理為止。
ProcessWindowFunction 接口的定義類似:
abstract class ProcessWindowFunction[IN, OUT, KEY, W <: Window] extends Function {
/**
* Evaluates the window and outputs none or several elements.
*
* @param key The key for which this window is evaluated.
* @param context The context in which the window is being evaluated.
* @param elements The elements in the window being evaluated.
* @param out A collector for emitting elements.
* @throws Exception The function may throw exceptions to fail the program and trigger recovery.
*/
def process(
key: KEY,
context: Context,
elements: Iterable[IN],
out: Collector[OUT])
/**
* The context holding window metadata
*/
abstract class Context {
/**
* Returns the window that is being evaluated.
*/
def window: W
/**
* Returns the current processing time.
*/
def currentProcessingTime: Long
/**
* Returns the current event-time watermark.
*/
def currentWatermark: Long
/**
* State accessor for per-key and per-window state.
*/
def windowState: KeyedStateStore
/**
* State accessor for per-key global state.
*/
def globalState: KeyedStateStore
}
} 使用Demo如下:
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.timeWindow(Time.minutes(5))
.process(new MyProcessWindowFunction())
/* ... */
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]): () = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
} 注意,使用ProcessWindowFunction進行簡單的累加計算效率是十分低下的,可以通過将ProcessWindowFunction與ReduceFunction、AggregateFunction或FoldFunction相結合來緩解這種情況,可以參考
6.2.3 Evictors
Evictors 可翻譯為驅逐者,但是稱之為回收器或者過濾器可能更加合适。
Flink 的視窗模型允許指定除 WindowAssigner 和觸發器之外的可選回收器。這可以使用
evictor(…)
方法實作定義。
其能夠在觸發器觸發之後以及在應用視窗函數之前 and/or 之後從視窗中删除元素。
為此,Evictor 接口有兩個方法:
/**
* 視窗函數計算之前調用
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
/**
* 視窗函數計算之後調用
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext); 同樣的,Flink 中也内置了幾個預定義的 Evictor:
- CountEvictor: 根據使用者指定的數量保留元素,如果超出指定數量則依次删除視窗中的元素。
- DeltaEvictor: 使用者需要指定一個
DeltaFunction
threshold
DeltaFunction
threshold
- TimeEvictor: 根據使用者定義的視窗大小interval,它會找到它的元素中的最大時間戳max_ts,并删除所有時間戳小于max_ts - interval的元素。
源代碼包位于
org.apache.flink.streaming.api.windowing.evictors
6.3 廣播變量
和 Spark 中的廣播變量一樣,Flink 也支援在各個節點中各存一份小資料集,所在的計算節點執行個體可在本地記憶體中直接讀取被⼴播的資料,可以避免 Shuffle 提高并行效率。
可在 DataStream 上使用
withBroadcastSet
方法将資料集以指定id廣播,并在
RichMapFunction
中通過
getRuntimeContext().getBroadcastVariable
方法獲得廣播資料集:
val env = ExecutionEnvironment.getExecutionEnvironment
// 建立需要⼴播的資料集
val dataSet1: DataSet[Int] = env.fromElements(1, 2, 3, 4)
//建立輸⼊資料集
val dataSet2: DataSet[String] = env.fromElements("flink", "dddd")
dataSet2.map(
//使用RichFunction 讀取廣播變量
new RichMapFunction[String, String]() {
var broadcastSet: Traversable[Int] = null
override def open(config: Configuration): Unit = {
// 擷取廣播變量資料集,并且轉換成Collection對象
broadcastSet = getRuntimeContext().getBroadcastVariable[Int]("broadcastSet-1")
}
def map(input: String): String = { input + broadcastSet.toList }
}
)
//廣播DataSet資料集,指定廣播變量量名稱為broadcastSet-1
.withBroadcastSet(dataSet1, "broadcastSet-1") 6.4 TaskChain
Flink作業中,可以指定相關的鍊條将相關性⾮常強的轉換操作綁定在一起,使得上下遊的Task在同⼀個Pipeline中執行,避免因為資料在⽹網絡或者線程之間傳輸導緻的開銷。
一般情況下Flink在Map類型的操作中預設開啟 TaskChain 以提高整體性能,開發人員也可以根據⾃己需要建立或者禁⽌ TaskChain 對任務進⾏細粒度的鍊條控制。
//建立 chain
dataStream.filter(...).map(...).startNewChain().map(...)
//禁止 chain
dataStream.map(...).disableChaining() 建立的鍊條隻對目前的操作符和之後的操作符有效,不不影響其他操作,如上demo隻針對兩 個map操作進⾏鍊條綁定,對前面的filter操作無效,如果需要可以在filter和map之間使用 startNewChain⽅法即可。