- create語句
CREATE (a:Person {name: '張三', sex: '男'})
如利用create批量寫入,這裡我使用的是scala+spark,代碼如下:
object Neo4jConnect {
def main(args: Array[String]):Unit = {
//資料庫連接配接
val spark=SparkSession.builder().appName("play")
.master("local[*]")
.config("spark.neo4j.bolt.url", "bolt://localhost:7687")
.config("spark.neo4j.bolt.user", "neo4j")
.config("spark.neo4j.bolt.password", "neo4j")
.getOrCreate()
val neo=Neo4j(spark.sparkContext)
val sql="CREATE (a:Person {name: '張三', sex: '男'}) RETURN a"
//測試語句
val rawGraphnode=neo.cypher(sql).loadRowRdd
rawGraphnode.take(10).foreach(println(_))
}
}
}
java也測試過,速度很慢
public class createConn {
/**
* 建立節點并增加屬性
*/
public static void createNode(){
Session session = driver.session();
session.run( "CREATE (a:Person {name: {name}, title: {title}})",
parameters( "name", "Arthur001", "title", "King001" ) );
StatementResult result = session.run( "MATCH (a:Person) WHERE a.name = {name} " +
"RETURN a.name AS name, a.title AS title",
parameters( "name", "Arthur001" ) );
while ( result.hasNext())
{
Record record = result.next();
System.out.println( record.get( "title" ).asString() + " " + record.get( "name" ).asString() );
}
session.close();
driver.close();
}
}
- load csv 指令導入
USING PERIODIC COMMIT 300 LOAD CSV WITH HEADERS FROM “file:///test.csv” AS line
MERGE (a:actors{name:line.name,type:line.type,id:line.id})
可變參數解釋:
1、USING PERIODIC COMMIT 300
使用自動送出,每滿300條送出一次,防止記憶體溢出
2、WITH HEADERS
從檔案中讀取第一行作為參數名,隻有在使用了該參數後,才可以使用line.name這樣的表示方式,否則需使用line[0]的表示方式
3、AS line
為每行資料重命名
4、MERGE
用merge比用create好一點,可以防止資料重複
另一種寫法
USING PERIODIC COMMIT 10
LOAD CSV FROM "file:///世界.csv" AS line
create (a:世界{personId:line[0],name:line[1],type:line[2]})
actors.csv放入neo4j安裝目錄下的import檔案夾
- 建立關系
//現有節點建立關系
MATCH (e:person),(cc:class) WHERE cc.id= e.id CREATE (e)-[r:屬于]->(cc)
因為從關系型資料庫導入的,這裡我通過現有的關聯id進行建立關系。
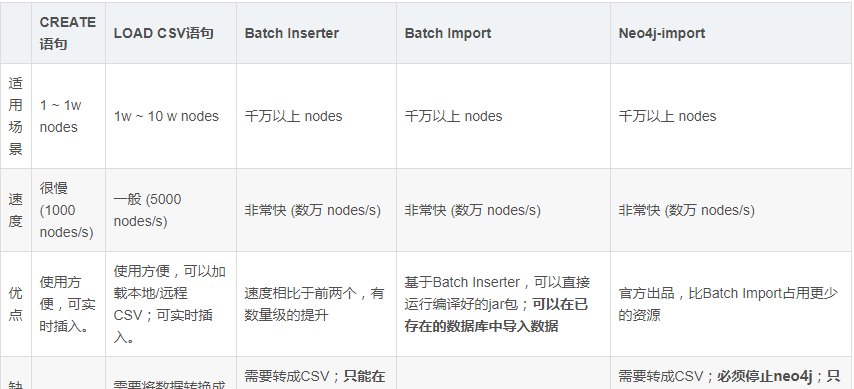
其他幾種暫時沒有用過,因為現階段需要實時插入。
持續更新。。。
![Java小案例——随機數猜測随機數猜測[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)