反壓(backpressure)是實時計算應用開發中,特别是流式計算中,十分常見的問題。反壓意味着資料管道中某個節點成為瓶頸,處理速率跟不上上遊發送資料的速率,而需要對上遊進行限速。由于實時計算應用通常使用消息隊列來進行生産端和消費端的解耦,消費端資料源是 pull-based 的,是以反壓通常是從某個節點傳導至資料源并降低資料源(比如 Kafka consumer)的攝入速率。
關于 Flink 的反壓機制,網上已經有不少部落格介紹,中文部落格推薦這兩篇1。簡單來說,Flink 拓撲中每個節點(Task)間的資料都以阻塞隊列的方式傳輸,下遊來不及消費導緻隊列被占滿後,上遊的生産也會被阻塞,最終導緻資料源的攝入被阻塞。而本文将着重結合官方的部落格[4]分享筆者在實踐中分析和處理 Flink 反壓的經驗。
反壓的影響
反壓并不會直接影響作業的可用性,它表明作業處于亞健康的狀态,有潛在的性能瓶頸并可能導緻更大的資料處理延遲。通常來說,對于一些對延遲要求不太高或者資料量比較小的應用來說,反壓的影響可能并不明顯,然而對于規模比較大的 Flink 作業來說反壓可能會導緻嚴重的問題。
這是因為 Flink 的 checkpoint 機制,反壓還會影響到兩項名額: checkpoint 時長和 state 大小。
- 前者是因為 checkpoint barrier 是不會越過普通資料的,資料處理被阻塞也會導緻 checkpoint barrier 流經整個資料管道的時長變長,因而 checkpoint 總體時間(End to End Duration)變長。
- 後者是因為為保證 EOS(Exactly-Once-Semantics,準确一次),對于有兩個以上輸入管道的 Operator,checkpoint barrier 需要對齊(Alignment),接受到較快的輸入管道的 barrier 後,它後面資料會被緩存起來但不處理,直到較慢的輸入管道的 barrier 也到達,這些被緩存的資料會被放到state 裡面,導緻 checkpoint 變大。
這兩個影響對于生産環境的作業來說是十分危險的,因為 checkpoint 是保證資料一緻性的關鍵,checkpoint 時間變長有可能導緻 checkpoint 逾時失敗,而 state 大小同樣可能拖慢 checkpoint 甚至導緻 OOM (使用 Heap-based StateBackend)或者實體記憶體使用超出容器資源(使用 RocksDBStateBackend)的穩定性問題。
是以,我們在生産中要盡量避免出現反壓的情況(順帶一提,為了緩解反壓給 checkpoint 造成的壓力,社群提出了 FLIP-76: Unaligned Checkpoints[4] 來解耦反壓和 checkpoint)。
定位反壓節點
要解決反壓首先要做的是定位到造成反壓的節點,這主要有兩種辦法:
- 通過 Flink Web UI 自帶的反壓監控面闆;
- 通過 Flink Task Metrics。
前者比較容易上手,适合簡單分析,後者則提供了更加豐富的資訊,适合用于監控系統。因為反壓會向上遊傳導,這兩種方式都要求我們從 Source 節點到 Sink 的逐一排查,直到找到造成反壓的根源原因[4]。下面分别介紹這兩種辦法。
反壓監控面闆
Flink Web UI 的反壓監控提供了 SubTask 級别的反壓監控,原理是通過周期性對 Task 線程的棧資訊采樣,得到線程被阻塞在請求 Buffer(意味着被下遊隊列阻塞)的頻率來判斷該節點是否處于反壓狀态。預設配置下,這個頻率在 0.1 以下則為 OK,0.1 至 0.5 為 LOW,而超過 0.5 則為 HIGH。
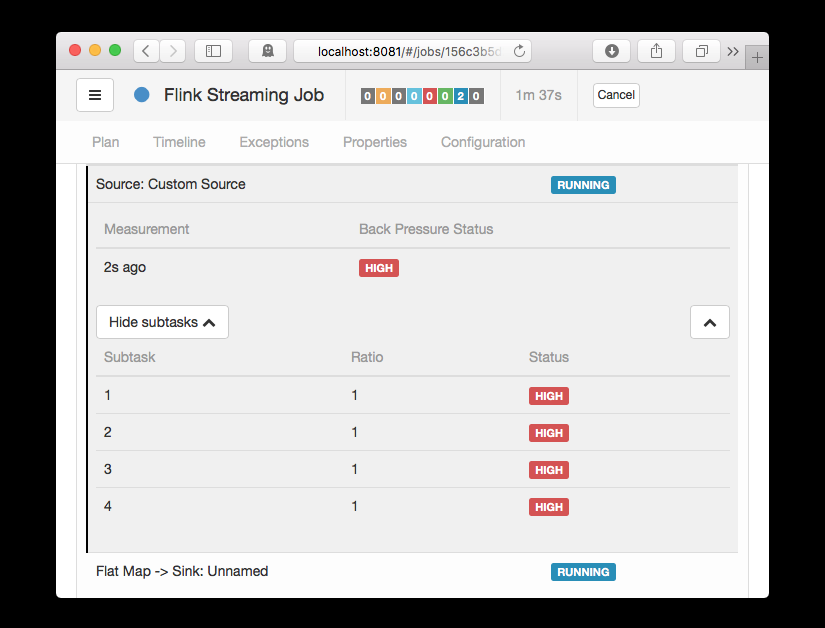
圖1. Flink 1.8 的 Web UI 反壓面闆(來自官方部落格)
如果處于反壓狀态,那麼有兩種可能性:
- 該節點的發送速率跟不上它的産生資料速率。這一般會發生在一條輸入多條輸出的 Operator(比如 flatmap)。
- 下遊的節點接受速率較慢,通過反壓機制限制了該節點的發送速率。
如果是第一種狀況,那麼該節點則為反壓的根源節點,它是從 Source Task 到 Sink Task 的第一個出現反壓的節點。如果是第二種情況,則需要繼續排查下遊節點。
值得注意的是,反壓的根源節點并不一定會在反壓面闆展現出高反壓,因為反壓面闆監控的是發送端,如果某個節點是性能瓶頸并不會導緻它本身出現高反壓,而是導緻它的上遊出現高反壓。總體來看,如果我們找到第一個出現反壓的節點,那麼反壓根源要麼是就這個節點,要麼是它緊接着的下遊節點。
那麼如果區分這兩種狀态呢?很遺憾隻通過反壓面闆是無法直接判斷的,我們還需要結合 Metrics 或者其他監控手段來定位。此外如果作業的節點數很多或者并行度很大,由于要采集所有 Task 的棧資訊,反壓面闆的壓力也會很大甚至不可用。
Task Metrics
Flink 提供的 Task Metrics 是更好的反壓監控手段,但也要求更加豐富的背景知識。
首先我們簡單回顧下 Flink 1.5 以後的網路棧,熟悉的讀者可以直接跳過。
TaskManager 傳輸資料時,不同的 TaskManager 上的兩個 Subtask 間通常根據 key 的數量有多個 Channel,這些 Channel 會複用同一個 TaskManager 級别的 TCP 連結,并且共享接收端 Subtask 級别的 Buffer Pool。
在接收端,每個 Channel 在初始階段會被配置設定固定數量的 Exclusive Buffer,這些 Buffer 會被用于存儲接受到的資料,交給 Operator 使用後再次被釋放。Channel 接收端空閑的 Buffer 數量稱為 Credit,Credit 會被定時同步給發送端被後者用于決定發送多少個 Buffer 的資料。
在流量較大時,Channel 的 Exclusive Buffer 可能會被寫滿,此時 Flink 會向 Buffer Pool 申請剩餘的 Floating Buffer。這些 Floating Buffer 屬于備用 Buffer,哪個 Channel 需要就去哪裡。而在 Channel 發送端,一個 Subtask 所有的 Channel 會共享同一個 Buffer Pool,這邊就沒有區分 Exclusive Buffer 和 Floating Buffer。

圖2. Flink Credit-Based 網絡
我們在監控反壓時會用到的 Metrics 主要和 Channel 接受端的 Buffer 使用率有關,最為有用的是以下幾個 Metrics:
| Metris | 描述 |
|---|---|
| outPoolUsage | 發送端 Buffer 的使用率 |
| inPoolUsage | 接收端 Buffer 的使用率 |
| floatingBuffersUsage(1.9 以上) | 接收端 Floating Buffer 的使用率 |
| exclusiveBuffersUsage (1.9 以上) | 接收端 Exclusive Buffer 的使用率 |
其中 inPoolUsage 等于 floatingBuffersUsage 與 exclusiveBuffersUsage 的總和。
分析反壓的大緻思路是:如果一個 Subtask 的發送端 Buffer 占用率很高,則表明它被下遊反壓限速了;如果一個 Subtask 的接受端 Buffer 占用很高,則表明它将反壓傳導至上遊。反壓情況可以根據以下表格進行對号入座(圖檔來自官網):
圖3. 反壓分析表
outPoolUsage 和 inPoolUsage 同為低或同為高分别表明目前 Subtask 正常或處于被下遊反壓,這應該沒有太多疑問。而比較有趣的是當 outPoolUsage 和 inPoolUsage 表現不同時,這可能是出于反壓傳導的中間狀态或者表明該 Subtask 就是反壓的根源。
如果一個 Subtask 的 outPoolUsage 是高,通常是被下遊 Task 所影響,是以可以排查它本身是反壓根源的可能性。如果一個 Subtask 的 outPoolUsage 是低,但其 inPoolUsage 是高,則表明它有可能是反壓的根源。因為通常反壓會傳導至其上遊,導緻上遊某些 Subtask 的 outPoolUsage 為高,我們可以根據這點來進一步判斷。值得注意的是,反壓有時是短暫的且影響不大,比如來自某個 Channel 的短暫網絡延遲或者 TaskManager 的正常 GC,這種情況下我們可以不用處理。
對于 Flink 1.9 及以上版本,除了上述的表格,我們還可以根據 floatingBuffersUsage/exclusiveBuffersUsage 以及其上遊 Task 的 outPoolUsage 來進行進一步的分析一個 Subtask 和其上遊 Subtask 的資料傳輸。
圖4. Flink 1.9 反壓分析表
通常來說,floatingBuffersUsage 為高則表明反壓正在傳導至上遊,而 exclusiveBuffersUsage 則表明了反壓是否存在傾斜(floatingBuffersUsage 高、exclusiveBuffersUsage 低為有傾斜,因為少數 channel 占用了大部分的 Floating Buffer)。
至此,我們已經有比較豐富的手段定位反壓的根源是出現在哪個節點,但是具體的原因還沒有辦法找到。另外基于網絡的反壓 metrics 并不能定位到具體的 Operator,隻能定位到 Task。特别是 embarrassingly parallel(易并行)的作業(所有的 Operator 會被放入一個 Task,是以隻有一個節點),反壓 metrics 則派不上用場。
分析具體原因及處理
定位到反壓節點後,分析造成原因的辦法和我們分析一個普通程式的性能瓶頸的辦法是十分類似的,可能還要更簡單一點,因為我們要觀察的主要是 Task Thread。
在實踐中,很多情況下的反壓是由于資料傾斜造成的,這點我們可以通過 Web UI 各個 SubTask 的 Records Sent 和 Record Received 來确認,另外 Checkpoint detail 裡不同 SubTask 的 State size 也是一個分析資料傾斜的有用名額。
此外,最常見的問題可能是使用者代碼的執行效率問題(頻繁被阻塞或者性能問題)。最有用的辦法就是對 TaskManager 進行 CPU profile,從中我們可以分析到 Task Thread 是否跑滿一個 CPU 核:如果是的話要分析 CPU 主要花費在哪些函數裡面,比如我們生産環境中就偶爾遇到卡在 Regex 的使用者函數(ReDoS);如果不是的話要看 Task Thread 阻塞在哪裡,可能是使用者函數本身有些同步的調用,可能是 checkpoint 或者 GC 等系統活動導緻的暫時系統暫停。
當然,性能分析的結果也可能是正常的,隻是作業申請的資源不足而導緻了反壓,這就通常要求拓展并行度。值得一提的,在未來的版本 Flink 将會直接在 WebUI 提供 JVM 的 CPU 火焰圖[5],這将大大簡化性能瓶頸的分析。
另外 TaskManager 的記憶體以及 GC 問題也可能會導緻反壓,包括 TaskManager JVM 各區記憶體不合理導緻的頻繁 Full GC 甚至失聯。推薦可以通過給 TaskManager 啟用 G1 垃圾回收器來優化 GC,并加上 -XX:+PrintGCDetails 來列印 GC 日志的方式來觀察 GC 的問題。
總結
反壓是 Flink 應用運維中常見的問題,它不僅意味着性能瓶頸還可能導緻作業的不穩定性。定位反壓可以從 Web UI 的反壓監控面闆和 Task Metric 兩者入手,前者友善簡單分析,後者适合深入挖掘。定位到反壓節點後我們可以通過資料分布、CPU Profile 和 GC 名額日志等手段來進一步分析反壓背後的具體原因并進行針對性的優化。
參考
1.Flink 原理與實作:如何處理反壓問題 2.一文徹底搞懂 Flink 網絡流控與反壓機制 3.Flink 輕量級異步快照 ABS 實作原理 4.Flink Network Stack Vol. 2: Monitoring, Metrics, and that Backpressure Thing 5.Support for CPU FlameGraphs in new web UI作者介紹:
林小鉑,網易遊戲進階開發工程師,負責遊戲資料中心實時平台的開發及運維工作,目前專注于 Apache Flink 的開發及應用。探究問題本來就是一種樂趣。
原文連結:
http://www.whitewood.me/2019/11/03/Flink-%E5%8F%8D%E5%8E%8B%E5%88%86%E6%9E%90%E5%8F%8A%E5%A4%84%E7%90%86/Flink Forward Asia 倒計時 10 天!11 月 28-30 日,Flink Forward Asia 2019 核心技術專場,屆時 Apache Flink 核心貢獻者們将與多位來自一線的業界資深專家帶你全方位解鎖 Flink 核心技術。購票及了解更多大會詳情,可點選:
https://developer.aliyun.com/special/ffa2019-conference?spm=a2c6h.13239638.0.0.21f27955CZ1xEE