量化交易中,資料系統主要需要支撐兩個場景。第一個是政策回測,面對的是過去10年的曆史資料,資料量在10TB級别。目标是當我們腦袋裡面有一個自認為絕好的政策思路時,能夠快速的進行驗證其是不是有效。從技術實作的角度來說,回測就是一遍一遍的輪詢大量的曆史資料進行計算。這裡面的曆史資料是不會更改的,要求讀取的速度特别快。
另一個是實時交易,面對的是每秒10k+的交易資料流入,能夠即時通過原始資料計算出量化因子,做出交易決策。還有風險控制,在出現事先沒有預期到的風險時,要能夠迅速把持倉退出來。這都要求延遲盡可能地小,控制滑點成本。
金融時間序列資料的特點
- 資料量比較大。以目前A股的level1 tick資料為例,每支股票每3s就會生成一條資料,3k+支股票每天交易4個小時,總計生成接近1500萬條原始記錄,加入基于原始記錄生成的各類因子,資料量要翻N倍。使用level2逐筆成交資料的話,資料量要更大。
- 資料是分塊的。依賴于交易所的交易日界定,每個交易日都是獨立的,是以可以将每支股票每天的資料作為一塊互不相關的資料塊。每個資料塊大約1M大小。
- 全部是數值型,沒有文本。對資料的壓縮很有效。
- 資料穩定增長,不會出現通路峰值。這對于系統的承壓能力要求相對較低。
- 一次寫入多次讀取,不會修改已經寫入的資料,資料寫入壓力小。
- 不需要支援事務。
- 對時效性和準确性要求很高。如果出現比較大的延遲或者資料錯誤,那政策的表現變得不可控,無法執行。
資料庫的選擇
- MySQL:以上文所提到的A股level1 tick資料量,MySQL是無法支撐的。對于曆史資料來說資料量太大了,MySQL的資料壓縮效率不高,存儲和效率都無法滿足需求;對于實時交易來說延遲會比較大。
如果資料頻率時分鐘K線,那用MySQL是可以解決的。使用MyISAM存儲引擎,因為MyISAM可以對資料壓縮,節約存儲空間,讀性能也要比InnoDB要好。
- MongoDB:一個不錯的選擇,目前有很多量化團隊在使用MongoDB作資料存儲。對于中低頻政策應該完全沒問題。 Mongoing中文社群 也有一系列相關的文章:
- InfluxDB:無論是面對曆史回測或者實時交易的場景,InfluxDB都是很好的選擇。具體在下文讨論。
- HDF5:非常高效的二進制檔案,用來存儲靜态資料,特别是面對科學計算問題。具體在下文讨論。
- Kdb+:商用軟體,性能很強大,但是q查詢語言學習曲線很陡峭,而且license很貴。
- DolphinDB:比較新的時序資料庫,也是商用軟體, 官方 宣稱其性能可以替代kdb+。
InfluxDB
為什麼選擇InfluxDB
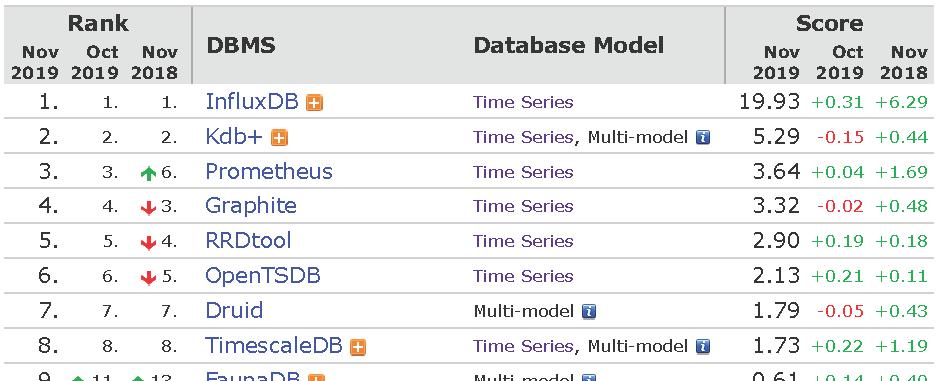
InfluxDB是目前最受歡迎的時序資料庫,而且社群活躍度增長非常快。一圖勝千言,我們看下面兩個圖就可以了解時序資料庫的現狀。
Ranking of Time Series DBMS (from
DB-Engines)
Trend of InfluxDB Popularity (from

與其它資料庫對比
MongoDB vs InfluxDB | InfluxData Time Series Workloads- InfluxDB outperformed MongoDB by 2.4x when it came to data ingestion
- InfluxDB outperformed MongoDB by delivering 20x better compression
- InfluxDB outperformed MongoDB by delivering 5.7x better query performance
InfluxDB和OpenTSDB是目前最受歡迎兩個時序資料庫。
易用性:
- 在單機上,InfluxDB就是一個獨立安裝包,安裝配置都很簡單。
-
在叢集系統中,OpenTSDB使用HBase存儲資料,比較成熟。InfluxDB的叢集解決方案是商業化的。
性能:
- InfluxDB outperformed OpenTSDB by 9x when it came to data ingestion
- InfluxDB outperformed OpenTSDB by delivering 8x better compression
- InfluxDB outperformed OpenTSDB by delivering a minimum of 7x better query throughput
InfluxDB硬體配置建議
| Load | Field writes per second | Moderate queries per second | Unique series |
|---|---|---|---|
| Low | < 5 thousand | < 5 | < 100 thousand |
| Moderate | < 250 thousand | < 25 | < 1 million |
| High | > 250 thousand | > 25 | > 1 million |
| Probably infeasible | > 750 thousand | > 100 | > 10 million |
- Low - CPU: 2-4 cores, RAM: 2-4 GB, IOPS: 500
- Moderate - CPU: 4-6 cores, RAM: 8-32 GB, IOPS: 500-1000
- High - CPU: 8+ cores, RAM: 32+ GB, IOPS: 1000+
- Probably infeasible load - cluster solution
根據上文的推算結果,這裡的load介于Moderate與High之間,使用單機InfluxDB就夠了。
目前很多量化團隊用的都是單機架構,主要在提高單機性能。那為什麼不用分布式系統,比如Hive/HBase?因為學習和維護成本高,對于中小團隊不現實。另一個原因就是這裡資料并不是高并發的場景,性能較好的單機就可以解決。
InfluxDB存儲交易資料
InfluxDB使用細節不在這裡展開。學習資料:
在我們的系統中,每支股票用一個獨立的 measurement 存儲,類似于MySQL裡面的table。如上文所說,每支股票每天的交易tick被當作一個獨立資料塊,在InfluxDB裡面存儲為一個series,通過添加tag記錄交易日來區分。還加入另一個tag來記錄資料源,因為我們可能會有多個資料源,這個tag可用來做資料源可靠性分析。
資料(line protocol)示例,其中
date
和
source
就是資料的tag集:
000001,source=XYZ,date=20190103 Price=123.45,Volume=6789,Amount=10111213 1546480800000 檢索示例,查詢出某支股票一整天的交易資料,InfluxQL跟SQL使用基本一樣:
SELECT * FROM "000001" WHERE date='20190103' 使用技巧
- InfluxDB是不支援事務的,是以在讀/寫操作同時進行的場景中,有可能一條記錄隻有一半被寫入,就被讀出來了,這就是髒資料。為了判斷讀出來的是不是髒資料,需要對取出來的資料進行檢查,如果某個不可能為空的字段是空值,那麼求需要重新取一次。
- 複制measurement:
SELECT * INTO measurement_new FROM measurement_old GROUP BY *
HDF5
對于實時交易的場景,用InfluxDB提供資料管理系統,使用友善,也可以解耦合資料子產品、計算子產品和交易子產品。
但是在面對曆史資料回測的場景中,我們會預先通過原始資料計算出因子資料,在整個回測過程中隻會對資料進行讀取,不會做任何更新。如果這裡依舊使用InfluxDB,就會在資料庫連接配接和網絡傳輸上産生額外的時間開銷,這是沒有必要的。這種情況下,本地檔案存儲就是一個很好的選擇。高效而且簡單易用的HDF5就是首選,可參考
Python和HDF5大資料應用。
HDF5中有一個dataset的概念,就是一個相關資料組成的一個資料集,在我們的問題裡面,前文所說的資料塊就很好的符合這個概念,每個股票每天的資料作為一個資料集存儲。
API接口
- 不建議用pandas中的
Dataframe.to_hdf5
Dataframe
numpy.ndarray
Dataframe
- 使用壓縮功能對資料進行壓縮,節約存儲空間。
# save: ticks is an instance of pandas.Dataframe with h5py.File('data.h5', mode='w') as f: f.create_dataset('/20190101/000001', data=ticks, compression='gzip', compression_opts=6, chunks=ticks.shape) # load: read dataset and pack it to a pandas.Dataframe columns = ['Price', 'Volume', 'Amount'] with h5py.File('data.h5') as f: dset = f.get('/20190101/000001') values = dset.value ticks = pandas.Dataframe(data=numpy.array(values), columns=columns)