第2章
資料清理工具
無論是人工還是傳感器采集的資料,都或多或少地存在一些錯誤或者瑕疵。比如說,不同采樣人員記錄資料方式的不同會導緻資料值重複或不準确,錄入資料時的失誤會導緻資料輸入錯誤,傳感器斷電會造成大段的資料預設,不同國家和地區對時間日期制式的不同标準等,各種各樣的原因造成資料無法直接用來分析、可視化的情況非常普遍。一般來講,在從資料收集到最後報告的整個 過程中,資料清理會占用整個流程80%的時間。如此耗時的原因是資料清理并非一次性工作,資料清理、計算、可視化是一個動态的循環,根據分析需求的不同,需要應用不同的清理思路和方式。例如,對于預設值的處理,在探索性資料分析階段,一般都會嘗試各種不同的處理方式,完全移除、部分移除或替換成其他數值,并參考分析的目的來決定如何清理預設值。
本章會向讀者分享資料清理的一些基本原則,作為架構來指導資料清理工作,以幫助讀者逐漸形成一套屬于自己的資料清理思路。本章還将重點介紹如何使用tibble、tidyr、lubridate和stringr這4個包來進行資料清理。希望讀者在浏覽過本章之後,會對以下3點有所了解。
1)“髒”資料和“幹淨”資料的标準是什麼。
2)資料清理的指導原則。
3)可以使用的工具包。
2.1 基本概念
“髒”資料沒有任何标準,隻要是不能滿足分析要求的資料集都将打上“髒”的标簽。是以弄清楚與之相對的“幹淨”資料可以使我們更容易了解資料清理的概念。目前國際上公認的“幹淨”資料可以總結為如下3點。
1)屬性相同的變量自成一列。
2)單一觀測自成一行。
3)每個資料值必須獨立存在。
表2-1中顯示的資料不符合第1條原則,因為男、女都屬于性别,是以可以歸為一個變量,歸為一個變量後如表2-2中所示。但表2-2中顯示的資料不符合第3條原則,因為體重和年齡兩個變量放在了同一列中,雖然用反斜杠分隔後,人類按常識很容易了解,但計算機并不會懂,其隻會将兩列本來是數字類型的資料當成是字元串來處理。表2-3中展示了一個3條原則都不滿足的樣本資料集,在完成清理之前,計算機無法對表2-3中的資料進行任何有效的資料分析。


表2-4中列出了清理後的資料集。對單一資料清理的第一個指導原則就是,按照上文介紹的3點将資料集清理成相應的形式。第2個原則需要按照實際需求進行,表2-5中的資料集是将“寬”資料(一般指多個同類或不同類型變量并存)轉換成了“長”資料(同類型變量單獨成列)。“寬”資料更符合人們日常對Excel格式資料的了解,而“長”資料對計算機來講則更易進行資料存儲和計算,在R環境中,計算“長”資料的速度優于“寬”資料。将表2-4中的資料轉換成表2-5的形式隻需一個函數gather,相關内容詳見2.3節。
資料清理的第三個指導原則同樣需要視情況而定,不同來源的資料應單獨成表,獨立存在。比如,中繼資料(解釋變量名稱或資料背景的資料,英文為metadata)與原始資料應同時存在一個檔案或一個工作表中(參考第1章不規則資料讀取)。簡單來說,中繼資料通常會包含坐标、名額的具體含義等解釋性資訊,這類資訊不應與原始資料本身同時存在一個資料集中,而應單獨成為一個資料集,隻在需要解釋原始資料本身時才調用中繼資料。
2.2 tibble包—資料集準備
解決問題需要首先了解問題所在,對症下藥。tibble包的存在就是為了給資料清理及後續的分析提供一個最佳的起點。tibble既是R包的名字也是資料在R中的一種存儲格式。可以将tibble包了解為R中最常見的data.frame(資料框)格式的更新版。像下列代碼所示,如果使用read.csv讀取資料,那麼資料會被存儲在data.frame(資料框)格式中。但是當調用read_csv時,資料就會存在三種适用格式:tbl_df、tbl和data.frame。因為tibble和readr包都源自于Hadley的tidy系列,是以使用readr包時自動植入了tibble(以下簡稱tbl)的資料格式。那麼,問題來了,為什麼非要使用這個格式呢?
2.2.1 為什麼使用tibble
tbl格式作為老舊的data.frame更新版,主要包含如下三點優勢。
1)穩定性更好,可完整儲存變量名稱及屬性。
2)更多的資訊展示、警示提醒,有利于及時發現錯誤。
3)新的輸出方式使得浏覽資料時,螢幕的使用率極佳。
因為R語言已經誕生了将近20年,很多早期的函數都是圍繞data.frame格式寫就的,當調用這類函數時,“新興”的tbl格式可能會出現不相容的情況,這也是tbl格式目前被發現的唯一缺陷。
tbl格式的第一條優勢需要讀者在使用過程中對比兩種格式的差異才會有直覺感受,簡單來講就是,傳統的data.frame在處理變量名稱時,有時會悄悄改動名稱以滿足自身要求,這往往會給使用者帶來一些意料之外的錯誤。請看以下的例子。
兩行代碼分别使用函數data.frame和tibble建立了一個傳統的資料框格式(見表2-6),以及一個tbl格式的資料框(見表2-7)。代碼中定義的資料變量名稱為“x+y”,但在data.frame格式中被修改成了“x...y”。大部分情況下,這種預設的修改是資料框格式的一種自我保護機制,目的是為了後續計算時引用變量名不會産生歧義。但是這種保護機制同時會與程式設計資料分析的另一項基本原則發生沖突,即常量輸入等于常量輸出(這裡的常量可以了解為變量名),除非使用者主動修改,否則其名稱應保持一緻。至于如何選擇,就需要讀者自行決斷了。
第1章中提到檢視data.frame中的變量類型時,通常需要調用str函數。但是在tbl格式中,無須調用任何函數,直接輸入資料集名稱即可檢視相關資訊。預設情況下,tbl格式會根據console視窗的大小,自動調整顯示的内容。内容會包含資料格式、列總數、行總數、變量名稱和類型,以及無法完全展示部分的變量資訊。有一定data.frame使用經驗的讀者肯定知道,對于不調用str函數直接在console中運作data.frame格式的資料集,R會将小于1000列×1000行的所有内容都顯示出來,而且其中還不包括變量屬性等資訊。tbl格式檢視資料集相關資訊的示例代碼如下:
2.2.2 建立tbl格式
在練習使用tibble時,可以通過函數tibble或tribble來建立新的資料框。tibble函數建立新資料框的方法與baseR中data.frame函數的方法一緻。等号左邊為變量名稱,右邊為相應的資料值,不同變量之間以逗号相隔。下面的代碼建立了一個包含變量a和b的資料框,變量a包含6個值,分别為數字1到6,變量b為a列中的值乘以2,是以同為6個數值。代表integer(整數),代表double(浮點型)資料類型。建立資料框的代碼如下:
tribble函數比較适合用來建立小型資料集,可以采用正常excel表中資料分布的格式,直接手動輸入資料,變量名稱以“~”起始,逗号結束,資料值以逗号分隔。下面的代碼即用來生成表2-2的。該函數在特定情況下會顯得非常實用,比如,用來解釋變量(或名額)和因子水準的中繼資料一般都會雜亂無章,使用軟體清理既費時又費力,但當通過肉眼能夠很容易提取到關鍵資訊時,直接使用tribble函數手動生成變量和因子水準對照表會更高效。
2.2.3 as_tibble—轉換已有格式的資料集
在轉換資料的格式之前,可以使用is_tibble來測試目标對象是否已是tbl格式,該函數隻需要對象名稱這一個參數即可。
可以通過as_tibble函數将對象已有的格式(vector、matrix、list和data.frame等)轉換成tbl。表2-8中列出了常見對象格式的轉換注解。
下面通過具體的代碼來說明使用as_tibble函數将常見的R對象轉換成tibble格式的具體方法。
(1)as_tibble函數直接将vector格式轉換成資料框格式
1)随機設定一組向量,儲存為y。
2)檢視向量y。
3)調用as_tibble函數直接轉換,并将結果顯示到console中。
實作代碼具體如下:
向量轉換成tibble格式的結果如表2-9所示。
(2)矩陣格式轉換
首先建立一個名為b的示例矩陣,矩陣按照行排列數字1到9,行數和列數同為3,行名為“Row1”“Row2”“Row3”,列名為“col1”“col2”“col3”。表2-10中顯示了移除行名—設定rownames = NULL的結果,表2-11為保留行名設定rownames = NA的結果。
(3)傳統資料框格式轉換
傳統資料框格式轉換與轉換矩陣格式基本相同,讀者可以自行試驗。
(4)清單格式轉換
清單格式轉換一定要注意清單中要素的長度,即每個要素中所擁有的數值個數。
下面的代碼建立了一個名為“l”的清單,清單中包含了三個要素,分别是a、b和c。其中,要素a包含三個數值,要素b包含三個字母數值,要素c隻有一個數字,建立清單的代碼如下:
執行函數as_tibble可以毫無壓力地将該清單轉換成“tbl”格式,每個要素單獨成為一個變量,原清單中的要素c中的數值将被重複使用三次以對應其他變量的長度。如果要素c的長度為2,即包含兩個數值,那麼轉換會失敗。as_tibble函數代碼如下:
表2-12顯示的是清單轉換成功後的結果。
tibble包中另一個可以轉換資料格式的函數是enframe函數。該函數的優勢在于格式轉換時可對向量資料進行編号。以一個長度為3的數值向量為例,運作該函數之後,會得到一個擁有兩個變量,每個變量包含三個數值的資料框,第一個變量名為“name”,是對數值向量的對應編号。
2.2.4 add_row/column—實用小工具
在微軟的Excel中,使用者可以随意插入或者删除一行/列資料,add_row/column函數也為R使用者提供了類似的功能。使用baseR來完成新增列的需求相對來說很簡單。下面的代碼首先建立了一個“tbl”,然後使用“$”來為資料新增一列名為“k”的變量,變量的數值為3、2、1:
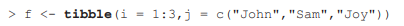 在資料框的末尾加入一行新資料也可以實作新增列的功能,不過該功能需要讀者對R的基本理論有一定的了解。如下代碼所示,延續資料框“f”,配合使用函數“[”和“nrow”可在資料框的末尾新增一行資料。“nrow”的功能是計算對象的行數。
小知識
中括号緊跟在資料框後面,可以作為索引來選擇資料框中的特定數值。逗号前面為行索引,後面為列索引:[行,列]。讀者可以試着配合“ncol”函數,以類似新增行的方式來為“f”新增一列。
tibble包中這兩個實用的小函數,可以随時随地任意新增行列資料到指定位置,而不是像baseR中的指令那樣隻能在資料尾部或已有變量後面新增行或列,在還不是很熟悉R的各種符号代碼之前,這兩個函數是可以幫助使用者快速有效地解決實際問題的。
下面的代碼為“f”又新增了一行資料,不過因為這裡僅指定了兩個變量的值,是以對于未指定的部分,系統将自動填入預設值,具體代碼如下:
在第三行之前插入一行新資料,代碼如下:
第一行之後插入新資料,代碼如下:
在第一列之後插入新變量,代碼如下:
2.3 tidyr—資料清道夫
2.3.1 為什麼使用tidyr
tidyr包作為整個tidy系列裡的支柱之一,可以稱為目前最容易上手的資料清理和資料操控工具。開發者Hadley汲取了前作reshape和reshape2包中的精華,并最大限度地考慮到新使用者的使用習慣,用精簡的人類語言創造了tidyr包。根據筆者的使用經驗,使用tidyr包進行資料清理的優勢在于以下4點。
1)簡潔直覺的函數名稱,可讀性極強—易上手。
2)預設設定可以滿足大部分使用需求,無須時刻參考幫助文檔—易使用。
3)不同函數中的參數設定結構清晰—易于記憶。
4)處理資料過程中完整保留了變量屬性及資料格式—不易出現未知錯誤。
本節将通過介紹tidyr包中最重要的幾個函數來為讀者展示tidyr包在資料清理和資料操控上的優勢,并将通過代碼示範來介紹其基本的使用方法。
2.3.2 gather/spread—“長”“寬”資料轉換
1. gather—“寬”變“長”
2.1節讨論了“寬”資料格式的弊端,是以推薦将資料轉換成“長”資料—全部變量名稱為一列,相關數值為一列。gather函數是以而生。圖2-1所示的示例用箭頭辨別出了資料由“寬”變“長”的具體路線。在理想情況下,整潔的資料框應為如圖2-1a所示的格式,因子水準一列(性别),變量(或名額)一列,剩餘所有數值型資料一列。
讀者可以使用2.2.2節中介紹的tribble函數來建構如圖2-1b所示的“髒”資料框,然後使用以下代碼實作從“髒”和“寬”的形式到“幹淨”和“長”的轉換。在代碼清單2-1中,筆者将“髒”資料儲存在名為df的資料框中(此處略去建立資料集的代碼),然後使用管道函數“%>%”,将df傳遞給gather函數(中文釋義見表2-13),因為管道函數的存在,是以無須重新引用df,而以“.”來代替,指定名額列為key,數值列為value,保留序号列(保留列需要使用負号加列名的形式進行設定),并移除預設值。之後會得到一個中間産物資料框,該資料框名額列中的“性别”和名額雖然以空格分隔開,但仍然在一列中,不滿足“幹淨”資料的原則。是以再次使用管道函數将中間産物的資料框,傳遞給函數separate(詳見2.3.3節),将key列拆分成兩列,分别為性别和key,此時的資料庫便如圖2-1a所示。
上述代碼中的“%>%”為'magrittr'包中的 forward-pipe operator,中文可以了解為管道函數。該函數能夠與'tidyverse'内的所有函數完美結合使用,且易于了解記憶。有興趣的讀者可以嘗試運作指令“?'%>%'”來檢視具體的英文幫助。
因為tidy系列中各個的函數的結構非常簡潔清晰,是以當讀者熟悉各種參數的位置情況之後,完全可以省略各種參數名稱,而隻依靠位置來進行傳參,具體代碼如下:
2. spread—“長”資料變“寬”
函數spread是gather函數的逆向函數,即将“長”資料轉換成“寬”資料。圖2-2簡要展示了函數的執行規則,将key列中的變量單獨拆分成新列,value列中與變量中對應的數值同樣會按規則進行放置。讀者可以參考表2-14中的中文釋義自行練習代碼。
2.3.3 separate/unite—拆分合并列
2.3.2節中展示了函數separate的具體用法,該函數完全可以了解為是Excel中的拆分列,該函數無法對一個單獨的數值位置進行操作。表2-15介紹了其所包含的參數及中文釋義。unite函數則是其相對的逆向函數。
2.3.4 replace_na / drop_na/—預設值處理工具
一旦明确了預設值的替代方式,replace_na和drop_na兩個函數就可以通過對指定列的查詢來将NA替換成需要的數值,例如,去掉所有存在預設值的觀察值。表2-16中列出了函數的功能簡介及使用時應注意的事項。讀者可以參照幫助文檔中的例子結合表2-16中的提示來自行練習這兩個函數的功能。
下面的代碼列出了如何使用兩個函數:
這裡必須提醒一下讀者關于預設值替換的情況,将所有預設值全部替換成0是很危險的行為,不推薦使用這種做法,因為0代表該資料是存在的,隻是數值為0,而預設值則可能代表資料不存在和存在兩種情況,隻是因為某些原因而導緻資料采集失敗。是以對預設值的處理一定要視具體情況而定。
2.3.5 fill/complete—填坑神器
在處理日期或者計算累積值的時候,如果中間有一個預設數值,則意味着值不完整或累積值無法計算。fill函數可以自動填補預設的日期或等值,類似于Excel中拖動滑鼠來完成單元格數值的複制或序列填充功能。complete函數是将三個函數揉在一起,這三個函數分别為:expand、dplyr::left_join和 replace_na。主要功能是将變量和因子的各種組合可能性全部羅列出來,并用指定的數值替代預設值部分。complete函數在日常練習中并不常用,是以這裡不做過多介紹,感興趣的讀者可以參考幫助文檔進行練習。
fill函數的參數及功能說明詳見表2-17。
2.3.6 separate_rows/nest/unest—行資料處理
-
separate_rows—拆分“單元格”
當遇到一個資料機關中出現多個數值的情況時,separate_rows函數就會顯得非常有用。圖2-3中展示了最基本的函數邏輯,将一個資料機關中的不同數值按照參數進行sep中給出的參進行數拆分,然後将拆分之後的結果順序地放在同一列的不同行中,并自動增加行數。
separate_rows函數的參數及功能說明詳見表2-18。
2. nest/unest—“壓縮”和“解壓縮”行資料
nest/unest是兩個互逆函數,它們最重要的功能是将一個資料框,按照使用者自定義的規則,将其壓縮成一個新的資料框,新的資料框中包含清單型資料。Jenny Bryan認為這是目前最有實際操作意義的資料框形式,因為它比較符合人們對資料集形式的一般主觀印象,而且資料框同時還保留了清單格式的靈活性。下面就來通過代碼具體介紹nest函數的實作機制。
将2.3.4節中清理後的資料儲存為df_tidy,然後再将該資料框傳遞給nest函數,并設定壓縮除性别列以外的變量。函數運作的結果是生成了一個隻有兩列的新資料框,變量為性别和data,其中,data列包含了原資料框中其他三個變量的資料(具體見表2-19)。變量data列中的清單格式将三個變量存儲為三個獨立的元素,如果讀者對兩個清單中任意一個進行as_tibble運算,都會得到一個完整的資料框。示例代碼如下:
上述代碼運作結果如表2-19所示。
将序号列排除在外,壓縮其餘變量列,代碼如下:
上述代碼運作結果如表2-20所示。
單獨使用nest函數沒有任何實際價值,但是當配合循環(第4章)和purrr包(第5章)中的map函數家族時,nest函數就會顯示出強大的功能性。對dplyr包有一定了解的讀者可以跳過第3章,直接檢視nest與其他具有循環功能的函數結合使用的例子。
表2-21和表2-22中列舉了nest/unest這一對函數的參數及功能說明。需要提醒讀者一點的是,如果需要使用unnest函數“解壓縮”兩列及以上時,那麼每一列中資料框的行數都必須相等,否則無法成功“解壓”。
2.4 lubridate日期時間處理
2.4.1 為什麼使用lubridate
通常傳感器記錄的資料,是為了避免閏年導緻的種種稀奇古怪的錯誤,純數字形式的日期格式很常見(例如19710101或儒略日)。這些純數字形式日期的可讀性通常都較差,是以需要經過解析變成更易了解的格式。還有另外一種比較普遍的情況是不同國家使用不同的日期制式和時區,比如英聯邦國家偏向使用“日月年”或“月日年”的形式記錄日期,以及12小時制來表達時間,而國内則傾向使用“年月日”的形式和24小時制。由于以上這些情況的存在,在處理與時間有關的數值時,解析日期和時間變量往往無可避免。
對于日期時間的處理看似簡單直接,但該問題卻是資料分析當中與預設值處理難度相當的另一大挑戰。在lubridate包問世之前,盡管已有其他功能強大的R包,諸如zoo、chron等,但都因為種種原因而無法達到與lubridate包一樣簡潔明了的效果。lubridate包的出現,極大地提高了使用者解析日期資料的效率,進而使得開發人員能将更多時間用于分析資料而不是微調代碼本身。lubridate包的最大優勢可以總結為如下三點。
1)使用人類語言書寫的程式設計文法,易于使用者了解和記憶。
2)總結并融合了其他R包中的時間處理函數,并且優化了預設設定,更利于使用者上手使用。
3)能夠輕松完成時間日期資料的計算任務。
2.4.2 ymd/ymd_hms—年月日還是日月年?
一般情況下,ymd及其子函數可以完整地解析以數字或字元串形式出現的日期形式,隻有當日期中對不同的成分以類似雙引号作為分隔符的情況,或者是對象為奇數的情況時(詳見代碼示範),ymd等函數可能會無法直接進行解析,而是需要進行額外處理。ymd函數即代表年月日,ymd_hms函數則代表年月日時分秒。兩類函數的參數名稱、結構和位置完全一緻,具體函數名稱見表2-23。預設時區為世界标準時間UTC。表2-23中列出了兩組函數所有的子函數。讀者在解析時間時應當注意時區,因為中原標準時間比UTC早8個小時,是以是UTC+8。所有對象經過解析後都會輸出為年月日(時分秒)的标準日期格式,并且類别為“Date”。
lubridate函數可以僅使用預設設定輕松解析偶數位的字元型向量,必須要注意的是,偶數位必須大于6位,否則會産生NA。在下列的代碼中,“2018 1 2”因為其中存在空格,是以被預設解析為6位。同樣的邏輯也适用于解析日期時間對象。參數tz用于設定時區,示例代碼如下:
小提示
如果函數沒有自動解析正确的時區,那麼讀者可以使用Sys.timezone()或Olson-Names()來尋找正确的時區,并傳參設定時區。
2.4.3 year/month/week/day/hour/minute/second—時間機關提取
氣象領域通常會計算若幹年的月、日平均降雨量或氣溫等名額,這時就會涉及月和日的提取要求。lubridate包中的函數,包含了提取從年到秒所有機關的功能。而為了友善記憶,這些函數的名稱也都與相應的元件一一對應。需要讀者注意的一點是,該組函數隻能提取時間日期格式的對象,這些對象可以是常見的“Date”“POSIXct”“POSIXlt”“Period”等,或者是其他日期時間處理R包中的格式“chron”“yearmon”“yearqtr”“zoo”“zooreg”等。
下面的代碼示範了最基本的使用方法,詳細的參數微調可以提供一些額外的資訊,讀者可以自行參閱幫助文檔:
2.4.4 guess_formats/parse_date_time—時間日期格式分析
當遇到使用英文月份簡寫的日期,比如24 Jan 2018/Jan 24,或者其他更糟糕的情況時,如果使用傳統的baseR中的函數,諸如strptime或是format之類,那麼使用者可能會浪費很多時間去猜測群組裝正确的日期時間格式,因為隻有順序和格式都正确的時候,baseR中提供的相應函數才可以正确解析日期時間,否則就會不停地傳回NA值。幸運的是,guess_formats和parse_date_time兩個函數的存在,完全颠覆了以往的解析模式,進而使得這一過程變得簡單有趣。
使用這兩個函數解析日期時間的大體思路具體如下。
1)執行guess_formats函數以用于猜測需要解析對象的可能日期時間順序及格式,使用者必須指定可能存在的格式順序。
2)複制guess_formats函數的傳回結果。
3)執行parse_date_time,并将複制的内容以字元串向量的格式傳參給函數。
4)若遇到解析不成功或不徹底的情況,則需要手動組建日期時間格式(元件清單請參看表2-24),并加入到guess_formats中的order參數中。
下面的代碼簡要解釋了guess_formats和parse_date_time兩個函數配合使用以解析日期時間的流程。首先生成一個名為example_messyDate的練習字元串向量,然後對該向量運作guess_formats,第二位參數orders中包含了可能存在的日期時間格式,并函數的傳回結果中會報告比對的順序格式,并将報告結果複制到parse_date_time的第二位參數中。至此解析成功。
2.5 stringr字元處理工具
與Hadley出品的其他tidy系列包一樣,stringr也具有同樣清晰的邏輯結構和參數設定。在stringr包中,函數的參數很少有超過三個的情況,各個常用的函數都隻需要指定兩到三個參數,這極大地簡化了參數設定的過程。加之參數在結構和名稱上的一緻性,使用者很容易就能做到融會貫通。stringr包總體來講是将stringi總結并優化而來的一個包。簡單的字元處理能力,可以極大地提高資料清理的效率。使用stringr包使用者能夠快速上手使用正規表達式,進而快速處理資料,同時對表達式的基本概念也能有一定的了解,為以後更複雜的任務做好鋪墊。
2.5.1 baseR vs stringr
baseR中已存在一些使用正規表達式處理字元串的函數,例如,以grep為母函數的一衆函數,包括最常用的gsub,等等。熟悉Linux系統的讀者可能會覺得grep看起來很眼熟,這是因為R語言與其他程式設計語言一樣,都借鑒了各種計算機語言的精華部分。表2-25列出了baseR中與字元串有關的函數及其與stringr包中相應函數的對比及小結。該表的意義在于,可以通過學習stringr包中的主要函數來幫助了解baseR包中的對應函數。因為stringr雖然簡單易上手,但是在實際處理應用資料時,其在速度上會比baseR又略遜一籌,讀者可以通過stringr包中的函數來練習字元處理的能力,在實際工作中使用baseR中的函數來執行具體任務。
下面的代碼簡略示範了str_replace和str_replace_all的差別以及參數設定。首先加載stringr包,然後建立一個練習用的字元串向量example_txt。對練習對象執行str_replace函數,參數pattern被設定為“a”—意為查詢“a”第一次出現的位置,參數replacement設定為符号“@”—意為使用“@”來替代字母“a”。結果可以看到隻有第一個“a”被替換,字元串中其他的“a”仍被保留。但是str_replace_all會将所有符合要求的部分全部替換掉。BaseR中的sub和gsub函數邏輯與str_replace和str_replace_all相同,隻是包含了格外的參數設定來滿足更複雜的任務需求。感興趣的讀者可以自行嘗試。示例代碼具體如下:
2.5.2 正規表達式基礎
Regular expression(正規表達式)在目前主流的統計語言上都有應用。使用符号型字元串大規模查找和替換資料,不僅可以提高工作效率,同時還能保證規則的一緻性。R中正則表正規表達式的符号意義,請參看表2-26。表2-26中列出了最常見的正規表達式基礎機關,讀者可以将這些符号想象成兒時樂高積木的小構件,由簡到繁地慢慢組合搭配這些構件,以實作不同的資料處理目标。簡單建構正規表達式請參見2.5.3節。
2.5.3 簡易正規表達式建立
資料集df是筆者從網絡上擷取的一組英文期刊作者名和年份(具體見表2-27),以此為例,簡單示範正規表達式的組合過程。示例代碼如下:
函數str_view/_all可以很直覺地反映出資料内部比對的項目。“.+”組合的意思是比對除換行符“n”以外的所有字元,字元至少出現一次,是以全部的字元都被比對出來。若隻希望比對“.”,則需要使用反斜杠來告知函數,這是因為獨立存在的“.”會被解析為任何除換行符以外的字元、字母和數字(見表2-26)。是以第二行代碼的意思就是比對第一個出現的英文句号:
比對所有字母和數字,代碼如下:
str_view/_all的傳回結果會顯示在Rstuido的viwer中,而不會顯示在console中。
當處理資料較多時,str_view/_all的速度可能會很慢,可以使用str_detect來檢測所使用的表達式在資料中是否有比對。該函數隻傳回邏輯判斷,代碼如下:
在df中,頁碼可以被歸類為無用資訊,是以需要清理掉。下面的代碼使用了str_replace來将頁碼的部分完全替換掉。比對模式為"pp\..+[:digit:]{2,3}\-[:digit:]{2,3}"。分解這個正規表達式:“pp”比對“pp”;“ \.”比對“.”;“.+”代表“pp.”後面的任何字元串;“[:digit:] {2,3}”代表2到3位數字;“\-”比對“-”;最後的[:digit:]{2,3}表示數字出現2到3位。
處理後的結果顯示在表2-28中。
更複雜的正規表達式可以參看Garrett Grolemund和Hadley Wickham合著的《R for Data Science》的第14章,或者全面介紹正規表達式的《Mastering Regular Expressions》,Jeffrey E. F. Friedl著。
2.5.4 文本挖掘淺析
文本(包括但不僅限于書刊)挖掘,或者更通俗地講—自然語言處理(Nature Language Processing),是人工智能領域必不可少的一項技術。每一秒鐘,世界範圍内都有不計其數的新文本在以各種形式記錄或儲存起來。但這些以人類語言書寫或錄制下來的“資料”,并不像二進制的表格式資料那樣容易被電腦接受并處理。如何分析人類曆史中這些以文本形式儲存的資料,就是文本挖掘需要解決的問題。看過《星際迷航》的讀者應該會很熟悉艦長們經常說的一句台詞“電腦,給我與某某事,某某東西相關的資料”。現實中,蘋果的siri已經算是這方面很成功的商業應用模型。也有很多程式設計資料分析前輩,結合機器學習和自然語言處理來進行音樂創作、文獻寫作,等等。有關文本挖掘的詳細内容已超出本書的讨論範圍,是以在此僅簡略地介紹文本挖掘的一般流程及可用R包,借此為感興趣的讀者提供一些繼續學習的線索。在第3章中讨論完dplyr包中的一些實用函數之後,3.3節會向讀者介紹一般的英文科技文獻挖掘流程。
圖2-4列出了文本挖掘的一般流程,大緻可以總結為三個主要部分,具體如下。
1)文本資料的擷取。
2)文本資料的準備。
3)資料分析。
資料擷取的方法多種多樣,可以使用網絡爬蟲抓取網絡文本,使用pdftools包讀取PDF格式的電子文檔,jsonlite包讀取JSON格式的文本資料,或者是安裝janeaustenr包來擷取簡奧斯汀的6本著名小說來進行文本挖掘的練習。
文本資料的準備包括清理标點符号、頁碼等多餘資訊,以及分詞标記和簡單的初步統計。通常需要使用正規表達式,其主要目的是将文章中的句子打散以擷取單個的詞語或詞組,并去掉某些無語義貢獻的詞彙,例如,介詞或是助詞,再進行一定程度的詞頻統計等操作。建議有一定英語基礎的讀者按照《Text Mining with R》這本書開始練習,書的作者就是最易上手的文本挖掘R包tidytext的開發者。希望分析中文的讀者可以從quanteda包開始,因為這個包配有中文詞庫和簡單的中文示意。
文本資料的分析根據目的的不同在難度上會有天壤之别。對于初學者來說,預先設定一些已知的規則來對文本資料進行查詢式的分析(比如,在簡奧斯汀的書中,哪一個角色的名字出現次數最多)這樣的詞頻統計分析可視化,可有助于提高對資料的了解程度和使用各個函數的信心。監督和無監督機器學習需要依靠tm、quanteda、topicmodels等不同的R包的互動使用才可能實作複雜的分析目标。詳細内容請感興趣的讀者參閱各個包的首頁,這裡不再過多讨論。