摘要:本次分享主要介紹Kafka産品的原理和使用方式,以及同步資料到MaxCompute的參數介紹、獨享內建資源組與自定義資源組的使用背景和配置方式、Kafka同步資料到MaxCompute的開發到生産的整體部署操作等内容。
演講嘉賓簡介:耿江濤,阿裡雲智能技術支援工程師
以下内容根據演講視訊以及PPT整理而成。
本次分享主要圍繞以下兩個方面:
一、背景介紹
二、具體操作流程
1.Kafka消息隊列使用以及原理
2.資源組介紹以及配置
3.同步過程及其注意事項
4.開發測試以及生産部署
1. 實驗目的
在日常工作中,很多企業将APP或網站産生的行為日志和業務資料通過Kafka收集之後做兩方面的處理。一方面是離線處理,一方面是實時處理。并且一般會投遞到MaxCompute中作為模型的建構,進行相關的業務處理,如使用者的特征、銷售排名、訂單地區分布等。這些資料形成之後會在資料報表中作為展示。
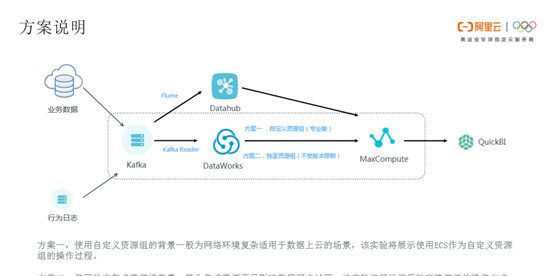
2. 方案說明
Kafka資料同步到DataWorks有兩條鍊路。一條鍊路是業務資料和行為日志通過Kafka,再通過Flume 上傳到Datahub,以及Max Compute,最終在QuickBI進行展示。另一條鍊路是業務資料和行為日志通過Kafka以及DataWorks,MaxCompute,最終在QuickBI當中展示。
本次展示Kafka通過DataWorks上傳到MaxCompute的流程。從DataWorks上傳到MaxCompute是通過兩種方案進行上傳資料同步的。方案一是自定義資源組,方案二是獨享資源組。自定義資源組一般适用于複雜網絡的資料上雲場景。獨享資源組操作方式主要針對內建資源不足的情況。
1.Kafka消息隊列使用及其原理
Kafka産品概述:消息隊列 for Apache Kafka 是阿裡雲提供的分布式、高吞吐、可擴充的消息隊列服務。消息隊列for Apache Kafka一般用于日志收集、監控資料聚合、流式資料處理、線上離線分析等大資料領域。消息隊列 for Apache Kafka 針對開源的 Apache Kafka 提供全托管服務,徹底解決開源産品長期以來的痛點。雲上Kafka具有低成本、更彈性、更可靠的優勢,使用者隻需專注于業務開發,無需部署運維。

Kafka架構介紹:如下圖所示,一個典型的Kafka叢集主要分為四部分。Producer生産資料并通過 push 模式向消息隊列 for Apache Kafka 的 Kafka Broker 發送消息。發送的消息可以是網站的頁面通路、伺服器日志,也可以是 CPU 和記憶體相關的系統資源資訊。Kafka Broker用于存儲消息的伺服器。Kafka Broker 支援水準擴充。 Kafka Broker 節點的數量越多,Kafka 叢集的吞吐率越高。Kafka Broker針對topic會partition一個概念,partition有leader、follower的角色配置設定。Consumer通過 pull 模式從消息隊列 for Apache Kafka Broker 訂閱并消費leader的資訊資料。其中partition内部有offset作為消息的消費點位。通過ZooKeeper管理叢集的配置、選舉 leader 分區,并且在Consumer Group 發生變化時,管理partition_leader的負載均衡。
Kafka消息隊列購買以及部署:如下圖,使用者首先可以到Kafka消息隊列産品頁面點選購買,根據個人情況選擇對應包年、包月等消費方式、地區、執行個體類型、磁盤、流量以及消息存放時間。其中較為重要的一點是要選擇對應地區,如果使用者的MaxCompute在華北,那麼盡量選擇華北地區。選擇開通完成後需要進行部署。點選部署,選擇合适的VPC及其交換機進行部署。
部署完成後進入Kafka Topic管理頁面,點選建立Topic輸入自己的Topic。Topic命名下面有三條注意資訊,命名盡量跟自己的業務一緻,比如是财經業務或者是商務業務,盡量進行區分。第四步進入Consumer Group管理,點選建立Consumer Group建立自己所需要的Consumer Group。Consumer Group的命名也需要規範,如果是财經或商務業務,盡量和自己的Topic相對應。
Kafka白名單配置:Kafka安裝部署完成之後确認需要通路Kafka的伺服器或産品的白名單。下圖中的預設接入點即為通路接口。
2.資源組介紹及其配置
自定義資源組的使用背景:自定義資源組一般針對IDC之間的網絡問題。本地網絡和雲上網絡存在差異,如DataWorks可以通過免費傳輸能力(預設任務資源組)進行海量資料上雲,但預設資源組無法實作傳輸速度存在較高要求或複雜環境中的資料源同步上雲的需求。此時使用者可以使用自定義資源組可實作複雜環境同步上雲的需求,解決DataWorks默 認資源組與您的資料源不通的問題,或實作更高速度的傳輸能力。然而,自定義資源組主要解決的還是複雜網絡環境上雲同步問題,打通任意網絡環境之間的資料傳輸同步。
自定義資源組的配置:自定義資源組的配置需要六步操作,首先點選進入DataWorks控制台,點開工作空間的清單,選擇使用者需要的項目空間,點選進入資料內建,即确認自己的資料內建是要在哪個空間項目下進行添加。之後,點選進入資料源界面,點選新增自定義資源組。要注意頁面右上角的新增自定義資源組是隻有項目管理者有權限添加。
第三步是确認Kafka與需要添加的自定義資源組屬于同一個VPC下。本次實驗是ECS向Kafka發送消息,二者的VPC應該一緻。第四步登入ECS,即個人的自定義資源組。執行指令dmidecode|grep UUID得到ECS的UUID。
第五步是将添加伺服器UUID以及自定義資源組的IP或機器CPU和記憶體填寫進來。最後是在ECS上執行相關指令,Agent安裝共5步,做一一确認,在第4小步完成後點選重新整理檢視服務是否為可用狀态。添加完成後進行檢查連通測試,檢查是否添加成功。
獨享資源組的使用背景:一些客戶反映在Kafka同步到MaxCompute時會報資源不足的問題,可以通過新增獨享資源組的方式進行資料同步。獨享資源模式下,機器的實體資源(網絡、磁盤、CPU和記憶體等)完全獨享。不僅可以隔離使用者間的資源使用,也可以隔離不同工作空間任務的資源使用。此外,獨享資源也支援靈活的擴容、縮容功能,可以滿足資源獨
享、靈活配置等需求。獨享資源組可以通路在同一地域下的VPC資料源,同時也可以通路跨地域的公網RDS位址。
獨享資源組的配置:獨享資源組的配置主要需要兩步操作,首先進入DataWorks控制台的資源清單,點選新增獨享資源組,包括獨享內建資源組和獨享排程資源組。此處選擇新增獨享內建資源組,點選購買時仍要注意選擇對應的購買方式、區域、資源、記憶體、時間期限、數量等。
購買完成後需要把獨享內建資源組綁定到與Kafka對應的VPC,點選專有網絡綁定,選擇與Kafka對應的交換機(最明顯的是可用區的差別)、安全組。
3.同步過程及其注意事項
Kafka同步到MaxCompute的需要進行相關參數配置同時需要注意以下幾個事項。
DataWorks資料內建操作:進入DataWorks操作界面,點選建立業務流程,在建立的業務流程添加資料同步節點,再進行命名。
如下圖所示,進入資料同步節點,包括Reader端和Writer端,點選Reader端資料源為Kafka,Writer端資料源為ODPS。點選轉化為腳本模式。下圖右上角是幫助文檔,Reader或Writer端的一些同步參數可以在此處就近點選,友善閱讀、操作和了解。
Kafka Reader的主要參數:Kafka Reader的主要參數首先server,上文所述Kafka的預設接入點就是其中一個server,ip:port。注意此處server是必填參數。topic,表示在Kafka部署完成之後,Kafka處理資料源的topic,此處也是必填參數。下一個參數是針對列column,column支援常量列、資料列、屬性列。常量列和資料列不太重要。同步的完整消息一般存放在屬性列 value 中,如果需要其它資訊,如partition、offset、timestamp,也可以在屬性列中篩選。column是必填參數。
keyType、valueType各有6種類型,根據使用者同步的資料,選擇相應的資訊,同步一個類型。需要注意同步方式是按消息時間同步,還是按消費點位置同步的。按資料消費點位置同步有四個場景,beginDateTime,endDateTime,beginOffset,endOffset。 beginDateTime 和beginOffset 二選其一,作為資料消費起點。endDateTime 和endOffset 二選其一。需要注意beginDateTime、endDateTime 中需要Kafka0.10.2版本以上才支援按資料消費點位置同步功能。另外需要注意beginOffset有三個比較特殊的形式:seekToBeginning,表示從開始點位消費資料;seekToLast,表示從上次消費的偏移位置消費資料,按照beginOffset從上次偏移位置隻能一次消費,如果使用beginDateTime則可以多次消費,這取決于消息存放時間;seekToEnd,表示從最後點位消費資料,會讀取到空資料。
skipExceeedRecord沒有太大作用,是不必填項。partition對topic所有分區共同讀消費的,是以無需自定義一個分區,是非必填項。kafkaConfig,如果有其它相關配置參數可以擴充配置在kafkaConfig,kafkaConfig也是非必填項。
MaxCompute Writer的主要參數:dataSource是資料源名稱,添加ODPS資料源。tables,表示所建立的資料表的表名稱,Kafka的資料要同步到哪張表中,相應的字段也可以建立。
partition,如果表為分區表,則必須配置到最後一級分區,确定同步位置。若為非分區表,則不必填。column,盡量與Kafka column中的相關字段做一一對應的操作。同步的字段對應,資訊同步才能确認成功。truncate,寫入時同步的資料是選擇以追加模式寫還是以覆寫模式寫,盡量避免多個DDL同時操作一個分區,或者在多個并發作業啟動前提前建立分區。
Kafka同步資料到MaxCompute:将下圖拆分為三部分。Kafka的Reader端,MaxCompute的Writer端以及限制參數。Reader包含server、endOffset、kafkaConfig、group.id、valueType、ByteArray、column字段、topic、beginOffset、seekToLast等。MaxCompute的Writer端包含覆寫、追加、壓縮、檢視源碼、同步到的表、字段要和Kafka的Reader端做一一對應,最重要的是value資料同步。限制參數,主要有errorlimit,資料超過幾個錯誤後會進行報錯;speed,可以限制流速、并發度等。
參考Kafka生産者SDK編寫代碼:最終生産出的資料要發送到Kafka中,通過相關代碼可以檢視使用者的生産資料。下圖一段代碼表示配置資訊的讀取,協定、序列化方式以及請求的等待時間,需要發送哪一個topic,發送什麼樣的消息。發送完成後回傳一個資訊。詳細代碼可以參考配置檔案、消息來源、生産者消費者的代碼模闆:
https://help.aliyun.com/document_detail/99957.html?spm=a2c4g.11186623.6.566.45fc54eayX69b0。
代碼打包運作在ECS上(與Kafka同一個可用區):如下圖所示,執行crontab-e指令,每到17:00執行一次。下圖為發送日志完成後的消息記錄。
在MaxCompute上建立表:進入DataWorks業務流程頁面,建立目标表,使用一個DDL語句建立同步的表,或根據使用者個人業務相應建立不同的表的字段。
4.開發測試以及生産部署
選擇自定義資源組(或獨享內建資源組)進行同步操作:下圖所示,選擇右上角“配置任務資源組”,根據使用者個人需求選擇資源組,點選執行。執行完成後,會出現辨別顯示成功,同步資料記錄以及結果是否成功。同步過程基本結束。
查詢同步的資料結果:在DataWorks臨界面檢視同步結果,在臨時節點點選查詢指令,select * from testkafka3(表),檢視資料同步結果。資料已經同步過來,證明測試成功。
設定排程參數:業務流程開發資料同步之後,會對相關模型進行一些業務處理,最後設計一些SQL節點、同步節點,進行部署。如下圖所示,在右側點選排程配置,輸入排程時間。具體操作可參考DataWorks官方文檔完善業務處理流程。
送出業務流程節點,并打包釋出:點選業務流程,選擇所需要送出的節點并送出。一些業務流程送出之後不需要放到生産環境當中。然後進入任務釋出界面,将節點添加到待釋出進行任務部署。
确認業務流程釋出成功:最後在運維中心頁面,确認釋出是否在生産環境中存在。至此Kafka同步資料到MaxCompute過程結束。到了對應的排程時間,在各個節點或者右上角會有節點的日志展示,可以檢視日志運作情況是否正常,或是否需要進行後續操作,部署資料或是相關指令。
歡迎加入“MaxCompute開發者社群2群”,點選連結申請加入或掃描二維碼
https://h5.dingtalk.com/invite-page/index.html?bizSource=____source____&corpId=dingb682fb31ec15e09f35c2f4657eb6378f&inviterUid=E3F28CD2308408A8&encodeDeptId=0054DC2B53AFE745