作者:肖強(TalkingData 資深工程師)
一、背景與痛點
在 2017 年上半年以前,TalkingData 的 App Analytics 和 Game Analytics 兩個産品,流式架構使用的是自研的 td-etl-framework。該架構降低了開發流式任務的複雜度,對于不同的任務隻需要實作一個 changer 鍊即可,并且支援水準擴充,性能尚可,曾經可以滿足業務需求。
但是到了 2016 年底和 2017 年上半年,發現這個架構存在以下重要局限:
- 性能隐患:App Analytics-etl-adaptor 和 Game Analytics-etl-adaptor 這兩個子產品相繼在節假日出現了嚴重的性能問題(Full-GC),導緻名額計算延遲。
- 架構的容錯機制不足:依賴于儲存在 Kafka 或 ZK 上的 offset,最多隻能達到 at-least-once,而需要依賴其他服務與存儲才能實作 exactly-once,并且會産生異常導緻重新開機丢數。
- 架構的表達能力不足: 不能完整的表達 DAG 圖,對于複雜的流式處理問題需要若幹依賴該架構的若幹個服務組合在一起才能解決問題。
TalkingData 這兩款産品主要為各類移動端 App 和遊戲提供資料分析服務,随着近幾年業務量不斷擴大,需要選擇一個性能更強、功能更完善的流式引擎來逐漸更新我們的流式服務。調研從 2016 年底開始,主要是從 Flink、Heron、Spark streaming 中作選擇。
最終,我們選擇了 Flink,主要基于以下幾點考慮:
- Flink 的容錯機制完善,支援 Exactly-once。
- Flink 已經內建了較豐富的 streaming operator,自定義 operator 也較為友善,并且可以直接調用 API 完成 stream 的 split 和 join,可以完整的表達 DAG 圖。
- Flink 自主實作記憶體管理而不完全依賴于 JVM,可以在一定程度上避免目前的 etl-framework 的部分服務的 Full-GC 問題。
- Flink 的 window 機制可以解決GA中類似于單日遊戲時長遊戲次數分布等時間段内某個名額的分布類問題。
- Flink 的理念在當時的流式架構中最為超前: 将批當作流的特例,最終實作批流統一。
二、演進路線
1. standalone-cluster (1.1.3->1.1.5->1.3.2)
我們最開始是以 standalone cluster 的模式部署。從 2017 年上半年開始,我們逐漸把 Game Analytics 中一些小流量的 etl-job 遷移到 Flink,到 4 月份時,已經将産品接收各版本 SDK 資料的 etl-job 完全遷移至 Flink,并整合成了一個 job。形成了如下的資料流和 stream graph:
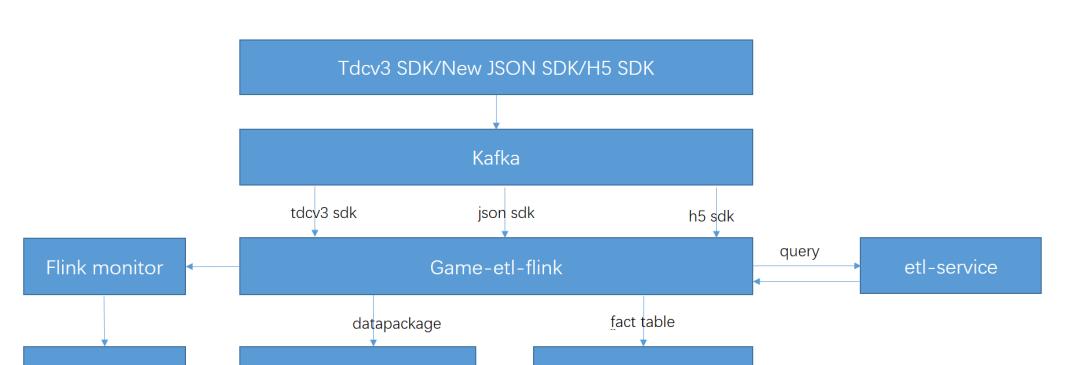
圖1. Game Analytics-etl-adaptor 遷移至 Flink 後的資料流圖

圖2. Game Analytics-etl 的 stream graph
在上面的資料流圖中,flink-job 通過 Dubbo 來調用 etl-service,進而将通路外部存儲的邏輯都抽象到了 etl-service 中,flink-job 則不需考慮複雜的訪存邏輯以及在 job 中自建 Cache,這樣既完成了服務的共用,又減輕了 job 自身的 GC 壓力。
此外我們自建構了一個 monitor 服務,因為當時的 1.1.3 版本的 Flink 可提供的監控 metric 少,而且由于其 Kafka-connector 使用的是 Kafka08 的低階 API,Kafka 的消費 offset 并沒有送出的 ZK 上,是以我們需要建構一個 monitor 來監控 Flink 的 job 的活性、瞬時速度、消費淤積等 metric,并接入公司 owl 完成監控告警。
這時候,Flink 的 standalone cluster 已經承接了來自 Game Analytics 的所有流量,日均處理消息約 10 億條,總吞吐量達到 12 TB 每日。到了暑假的時候,日均日志量上升到了 18 億條每天,吞吐量達到了約 20 TB 每日,TPS 峰值為 3 萬。
在這個過程中,我們又遇到了 Flink 的 job 消費不均衡、在 standalone cluster 上 job 的 deploy 不均衡等問題,而造成線上消費淤積,以及叢集無故自動重新開機而自動重新開機後 job 無法成功重新開機。(我們将在第三章中詳細介紹這些問題中的典型表現及當時的解決方案。)
經過一個暑假後,我們認為 Flink 經受了考驗,是以開始将 App Analytics 的 etl-job 也遷移到 Flink 上。形成了如下的資料流圖:
圖3. App Analytics-etl-adaptor 的标準 SDK 處理工作遷移到 Flink 後的資料流圖
圖4. App Analytics-etl-flink job 的 stream graph
2017 年 3 月開始有大量使用者開始遷移至統一的 JSON SDK,新版 SDK 的 Kafka topic 的峰值流量從年中的 8 K/s 上漲至了年底的 3 W/s。此時,整個 Flink standalone cluster 上一共部署了兩款産品的 4 個 job,日均吞吐量達到了 35 TB。
這時遇到了兩個非常嚴重的問題:
- 同一個 standalone cluster 中的 job 互相搶占資源,而 standalone cluster 的模式僅僅隻能通過 task slot 在 task manager 的堆内記憶體上做到資源隔離。同時由于前文提到過的 Flink 在 standalone cluster 中 deploy job 的方式本來就會造成資源配置設定不均衡,進而會導緻 App Analytics 線流量大時而引起Game Analytics 線淤積的問題。
- 我們的 source operator 的并行度等同于所消費 Kafka topic 的 partition 數量,而中間做 etl 的 operator 的并行度往往會遠大于 Kafka 的 partition 數量。是以最後的 job graph 不可能完全被鍊成一條 operator chain,operator 之間的資料傳輸必須通過 Flink 的 network buffer 的申請和釋放,而 1.1.x 版本的 network buffer 在資料量大的時候很容易在其申請和釋放時造成死鎖,而導緻 Flink 明明有許多消息要處理,但是大部分線程處于 waiting 的狀态導緻業務的大量延遲。
這些問題逼迫着我們不得不将兩款産品的 job 拆分到兩個 standalone cluster 中,并對 Flink 做一次較大的版本更新,從 1.1.3(中間過度到 1.1.5)更新成 1.3.2。最終更新至 1.3.2 在 18 年的 Q1 完成,1.3.2 版本引入了增量式的 checkpoint 送出并且在性能和穩定性上比 1.1.x 版本做了巨大的改進。更新之後,Flink 叢集基本穩定,盡管還有消費不均勻等問題,但是基本可以在業務量增加時通過擴容機器來解決。
2. Flink on yarn (1.7.1)
因為 standalone cluster 的資源隔離做的并不優秀,而且還有 deploy job 不均衡等問題,加上社群上使用 Flink on yarn 已經非常成熟,是以我們在 18 年的 Q4 就開始計劃将 Flink 的 standalone cluster 遷移至 Flink on yarn 上,并且 Flink 在最近的版本中對于 batch 的提升較多,我們還規劃逐漸使用 Flink 來逐漸替換現在的批處理引擎。
圖5. Flink on yarn cluster 規劃
如圖 5,未來的 Flink on yarn cluster 将可以完成流式計算和批處理計算,叢集的使用者可以通過一個建構 service 來完成 stream/batch job 的建構、優化和送出,job 送出後,根據使用者所在的業務團隊及服務客戶的業務量分發到不同的 yarn 隊列中,此外,叢集需要一個完善的監控系統,采集使用者的送出記錄、各個隊列的流量及負載、各個 job 的運作時名額等等,并接入公司的 OWL。
從 19 年的 Q1 開始,我們将 App Analytics 的部分 stream job 遷移到了 Flink on yarn 1.7 中,又在 19 年 Q2 前完成了 App Analytics 所有處理統一 JSON SDK 的流任務遷移。目前的 Flink on yarn 叢集的峰值處理的消息量達到 30 W/s,日均日志吞吐量達約到 50 億條,約 60 TB。在 Flink 遷移到 on yarn 之後,因為版本的更新性能有所提升,且 job 之間的資源隔離确實優于 standalone cluster。遷移後我們使用 Prometheus+Grafana 的監控方案,監控更友善和直覺。
我們将在後續将 Game Analytics 的 Flink job 和日志導出的 job 也遷移至該 on yarn 叢集,預計可以節約 1/4 的機器資源。
三、重點問題的描述與解決
在 Flink 實踐的過程中,我們一路上遇到了不少坑,我們挑出其中幾個重點坑做簡要講解。
1. 少用靜态變量及 job cancel 時合理釋放資源
在我們實作 Flink 的 operator 的 function 時,一般都可以繼承 AbstractRichFunction,其已提供生命周期方法 open()/close(),是以 operator 依賴的資源的初始化和釋放應該通過重寫這些方法執行。當我們初始化一些資源,如 spring context、dubbo config 時,應該盡可能使用單例對象持有這些資源且(在一個 TaskManager 中)隻初始化 1 次,同樣的,我們在 close 方法中應當(在一個 TaskManager 中)隻釋放一次。
static 的變量應該慎重使用,否則很容易引起 job cancel 而相應的資源沒有釋放進而導緻 job 重新開機遇到問題。規避 static 變量來初始化可以使用 org.apache.flink.configuration.Configuration(1.3)或者 org.apache.flink.api.java.utils.ParameterTool(1.7)來儲存我們的資源配置,然後通過 ExecutionEnvironment 來存放(Job送出時)和擷取這些配置(Job運作時)。
示例代碼:
Flink 1.3 設定及注冊配置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration parameters = new Configuration();
parameters.setString("zkConnects", zkConnects);
parameters.setBoolean("debug", debug);
env.getConfig().setGlobalJobParameters(parameters); 擷取配置(在 operator 的 open 方法中)。
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
ExecutionConfig.GlobalJobParameters globalParams = getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
Configuration globConf = (Configuration) globalParams;
debug = globConf.getBoolean("debug", false);
String zks = globConf.getString("zkConnects", "");
//.. do more ..
} Flink 1.7 設定及注冊配置:
ParameterTool parameters = ParameterTool.fromArgs(args);
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(parameters); 擷取配置:
public static final class Tokenizer extends RichFlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
ParameterTool parameters = (ParameterTool)
getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
parameters.getRequired("input");
// .. do more .. 2. NetworkBuffer 及 operator chain
如前文所述,當 Flink 的 job 的上下遊 Task(的 subTask)分布在不同的 TaskManager 節點上時(也就是上下遊 operator 沒有 chained 在一起,且相對應的 subTask 分布在了不同的 TaskManager 節點上),就需要在 operator 的資料傳遞時申請和釋放 network buffer 并通過網絡 I/O 傳遞資料。
其過程簡述如下:上遊的 operator 産生的結果會通過 RecordWriter 序列化,然後申請 BufferPool 中的 Buffer 并将序列化後的結果寫入 Buffer,此後 Buffer 會被加入 ResultPartition 的 ResultSubPartition 中。ResultSubPartition 中的 Buffer 會通過 Netty 傳輸至下一級的 operator 的 InputGate 的 InputChannel 中,同樣的,Buffer 進入 InputChannel 前同樣需要到下一級 operator 所在的 TaskManager 的 BufferPool 申請,RecordReader 讀取 Buffer 并将其中的資料反序列化。BufferPool 是有限的,在 BufferPool 為空時 RecordWriter / RecordReader 所在的線程會在申請 Buffer 的過程中等待一段時間,具體原理可以參考:[1], [2]。
簡要截圖如下:
圖6. Flink 的網絡棧, 其中 RP 為 ResultPartition、RS 為 ResultSubPartition、IG 為 InputGate、IC 為 inputChannel
在使用 Flink 1.1.x 和 1.3.x 版本時,如果我們的 network buffer 的數量配置的不充足且資料的吞吐量變大的時候,就會遇到如下現象:
圖7. 上遊 operator 阻塞在擷取 network buffer 的 requestBuffer() 方法中
圖8. 下遊的 operator 阻塞在等待新資料輸入
圖9. 下遊的 operator 阻塞在等待新資料輸入
我們的工作線程(RecordWriter 和 RecordReader 所在的線程)的大部分時間都花在了向 BufferPool 申請 Buffer 上,這時候 CPU 的使用率會劇烈的抖動,使得 Job 的消費速度下降,在 1.1.x 版本中甚至會阻塞很長的一段時間,觸發整個 job 的背壓,進而造成較嚴重的業務延遲。
這時候,我們就需要通過上下遊 operator 的并行度來計算 ResultPartition 和 InputGate 中所需要的 buffer 的個數,以配置充足的 taskmanager.network.numberOfBuffers。
圖10. 不同的 network buffer 對 CPU 使用率的影響
當配置了充足的 network buffer 數時,CPU 抖動可以減少,Job 消費速度有所提高。
在 Flink 1.5 之後,在其 network stack 中引入了基于信用度的流量傳輸控制(credit-based flow control)機制[2],該機制大限度的避免了在向 BufferPool 申請 Buffer 的阻塞現象,我們初步測試 1.7 的 network stack 的性能确實比 1.3 要高。
但這畢竟還不是最優的情況,因為如果借助 network buffer 來完成上下遊的 operator 的資料傳遞不可以避免的要經過序列化/反序列化的過程,而且信用度的資訊傳遞有一定的延遲性和開銷,而這個過程可以通過将上下遊的 operator 鍊成一條 operator chain 而避免。
是以我們在建構我們流任務的執行圖時,應該盡可能多的讓 operator 都 chain 在一起,在 Kafka 資源允許的情況下可以擴大 Kafka 的 partition 而使得 source operator 和後繼的 operator 鍊在一起,但也不能一味擴大 Kafka topic 的 partition,應根據業務量和機器資源做好取舍。更詳細的關于 operator 的 training 和 task slot 的調優可以參考: [4]。
3. Flink 中所選用序列化器的建議
在上一節中我們知道,Flink 的分布在不同節點上的 Task 的資料傳輸必須經過序列化/反序列化,是以序列化/反序列化也是影響 Flink 性能的一個重要因素。Flink 自有一套類型體系,即 Flink 有自己的類型描述類(TypeInformation)。Flink 希望能夠掌握盡可能多的進出 operator 的資料類型資訊,并使用 TypeInformation 來描述,這樣做主要有以下 2 個原因:
- 類型資訊知道的越多,Flink 可以選取更好的序列化方式,并使得 Flink 對記憶體的使用更加高效;
- TypeInformation 内部封裝了自己的序列化器,可通過 createSerializer() 擷取,這樣可以讓使用者不再操心序列化架構的使用(例如如何将他們自定義的類型注冊到序列化架構中,盡管使用者的定制化和注冊可以提高性能)。
總體上來說,Flink 推薦我們在 operator 間傳遞的資料是 POJOs 類型,對于 POJOs 類型,Flink 預設會使用 Flink 自身的 PojoSerializer 進行序列化,而對于 Flink 無法自己描述或推斷的資料類型,Flink 會将其識别為 GenericType,并使用 Kryo 進行序列化。Flink 在處理 POJOs 時更高效,此外 POJOs 類型會使得 stream 的 grouping/joining/aggregating 等操作變得簡單,因為可以使用如: dataSet.keyBy("username") 這樣的方式直接操作資料流中的資料字段。
除此之外,我們還可以做進一步的優化:
- 顯示調用 returns 方法,進而觸發 Flink 的 Type Hint:
dataStream.flatMap(new MyOperator()).returns(MyClass.class) returns 方法最終會調用 TypeExtractor.createTypeInfo(typeClass) ,用以建構我們自定義的類型的 TypeInformation。createTypeInfo 方法在建構 TypeInformation 時,如果我們的類型滿足 POJOs 的規則或 Flink 中其他的基本類型的規則,會盡可能的将我們的類型“翻譯”成 Flink 熟知的類型如 POJOs 類型或其他基本類型,便于 Flink 自行使用更高效的序列化方式。
//org.apache.flink.api.java.typeutils.PojoTypeInfo
@Override
@PublicEvolving
@SuppressWarnings("unchecked")
public TypeSerializer<T> createSerializer(ExecutionConfig config) {
if (config.isForceKryoEnabled()) {
return new KryoSerializer<>(getTypeClass(), config);
}
if (config.isForceAvroEnabled()) {
return AvroUtils.getAvroUtils().createAvroSerializer(getTypeClass());
}
return createPojoSerializer(config);
} 對于 Flink 無法“翻譯”的類型,則傳回 GenericTypeInfo,并使用 Kryo 序列化:
//org.apache.flink.api.java.typeutils.TypeExtractor
@SuppressWarnings({ "unchecked", "rawtypes" })
private <OUT,IN1,IN2> TypeInformation<OUT> privateGetForClass(Class<OUT> clazz, ArrayList<Type> typeHierarchy,
ParameterizedType parameterizedType, TypeInformation<IN1> in1Type, TypeInformation<IN2> in2Type) {
checkNotNull(clazz);
// 嘗試将 clazz轉換為 PrimitiveArrayTypeInfo, BasicArrayTypeInfo, ObjectArrayTypeInfo
// BasicTypeInfo, PojoTypeInfo 等,具體源碼已省略
//...
//如果上述嘗試不成功 , 則return a generic type
return new GenericTypeInfo<OUT>(clazz);
} -
注冊 subtypes: 通過 StreamExecutionEnvironment 或 ExecutionEnvironment 的執行個體的 registerType(clazz) 方法注冊我們的資料類及其子類、其字段的類型。如果 Flink 對類型知道的越多,性能會更好
;
- 如果還想做進一步的優化,Flink 還允許使用者注冊自己定制的序列化器,手動建立自己類型的 TypeInformation,具體可以參考 Flink 官網:[3];
在我們的實踐中,最初為了擴充性,在 operator 之間傳遞的資料為 JsonNode,但是我們發現性能達不到預期,是以将 JsonNode 改成了符合 POJOs 規範的類型,在 1.1.x 的 Flink 版本上直接獲得了超過 30% 的性能提升。在我們調用了 Flink 的 Type Hint 和 env.getConfig().enableForceAvro() 後,性能得到進一步提升。這些方法一直沿用到了 1.3.x 版本。
在更新至 1.7.x 時,如果使用 env.getConfig().enableForceAvro() 這個配置,我們的代碼會引起校驗空字段的異常。是以我們取消了這個配置,并嘗試使用 Kyro 進行序列化,并且注冊我們的類型的所有子類到 Flink 的 ExecutionEnvironment 中,目前看性能尚可,并優于舊版本使用 Avro 的性能。但是最佳實踐還需要經過比較和壓測 KryoSerializerAvroUtils.getAvroUtils().createAvroSerializerPojoSerializer 才能總結出來,大家還是應該根據自己的業務場景和資料類型來合理挑選适合自己的 serializer。
4. Standalone 模式下 job 的 deploy 與資源隔離共享
結合我們之前的使用經驗,Flink 的 standalone cluster 在釋出具體的 job 時,會有一定的随機性。舉個例子,如果目前叢集總共有 2 台 8 核的機器用以部署 TaskManager,每台機器上一個 TaskManager 執行個體,每個 TaskManager 的 TaskSlot 為 8,而我們的 job 的并行度為 12,那麼就有可能會出現下圖的現象:
第一個 TaskManager 的 slot 全被占滿,而第二個 TaskManager 隻使用了一半的資源!資源嚴重不平衡,随着 job 處理的流量加大,一定會造成 TM1 上的 task 消費速度慢,而 TM2 上的 task 消費速度遠高于 TM1 的 task 的情況。假設業務量的增長迫使我們不得不擴大 job 的并行度為 24,并且擴容2台性能更高的機器(12核),在新的機器上,我們分别部署 slot 數為 12 的 TaskManager。經過擴容後,叢集的 TaskSlot 的占用可能會形成下圖:
新擴容的配置高的機器并沒有去承擔更多的 Task,老機器的負擔仍然比較嚴重,資源本質上還是不均勻!
除了 standalone cluster 模式下 job 的釋出政策造成不均衡的情況外,還有資源隔離差的問題。因為我們在一個 cluster 中往往會部署不止一個 job,而這些 job 在每台機器上都共用 JVM,自然會造成資源的競争。起初,我們為了解決這些問題,采用了如下的解決方法:
- 将 TaskManager 的粒度變小,即一台機器部署多個執行個體,每個執行個體持有的 slot 數較少;
- 将大的業務 job 隔離到不同的叢集上。
這些解決方法增加了執行個體數和叢集數,進而增加了維護成本。是以我們決定要遷移到 on yarn 上,目前看 Flink on yarn 的資源配置設定和資源隔離确實比 standalone 模式要優秀一些。
四、總結與展望
Flink 在 2016 年時僅為星星之火,而隻用短短兩年的時間就成長為了目前最為炙手可熱的流處理平台,而且大有統一批與流之勢。經過兩年的實踐,Flink 已經證明了它能夠承接 TalkingData 的 App Analytics 和 Game Analytics 兩個産品的流處理需求。接下來我們會将更複雜的業務和批處理遷移到 Flink 上,完成叢集部署和技術棧的統一,最終實作圖 5 中 Flink on yarn cluster 的規劃,以更少的成本來支撐更大的業務量。
參考資料:
[1]
https://cwiki.apache.org/confluence/display/FLINK/Data+exchange+between+tasks[2]
https://flink.apache.org/2019/06/05/flink-network-stack.html[3]
https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/types_serialization.html#type-hints-in-the-java-api[4]Flink Slot 詳解與 Job Execution Graph 優化
了解更多 Flink 企業級應用案例可關注 Flink Forward Asia 企業實踐專場,屆時來自位元組跳動、滴滴出行、快手、Bilibili、網易、愛奇藝、中國農業銀行、奇虎360、貝殼找房、奇安信等衆多一線大廠技術專家現場分享 Flink 在各行業的應用效果與探索思路。
大會倒計時 25 天!11 月 28-30 日,北京國家會議中心,掃描下方二維碼立刻報名,來參與一場思維更新的技術盛宴~
點選了解更多大會議程:
https://developer.aliyun.com/special/ffa2019-conference?spm=a2c6h.13239638.0.0.21f27955RWcLlb11月28日下午,企業實踐專題分享
11月29日上午,企業實踐專題分享