前言
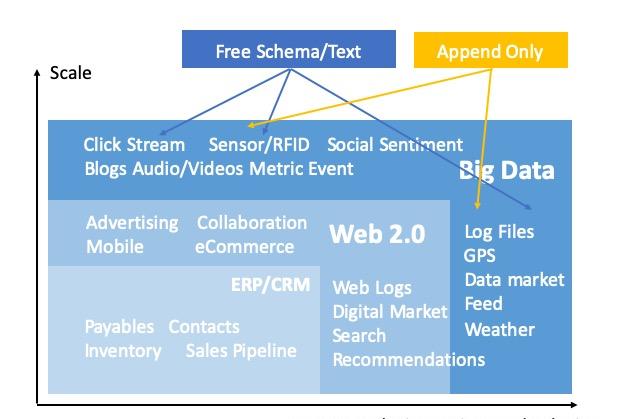
快速發展的日志資料
伴随Logging、Metrics、Tracing三者融合趨勢的部分顯現,日志類資料的範圍正在泛化,包括:工業傳感器資料、日志檔案、Prometheus采集的雲原生應用名額、Syslog、網絡點選日志、stdout、業務埋點等等。
可以看到:
•資料規模快速增長,日志類資料是big data的主力。
•采集的日志資料類别正在增加,其一是日志類型泛化,其二是過去被丢棄的資料正被重拾起來。
•資料營運的理念在各行各業滲透,更多的日志資料開始得到處理,更多的人開始參與日志分析。
即使在傳統日志領域,以Kubernetes為代表的雲原生的流行,也帶來了新的日志生命周期管理需求。如何從各種日志源采集資料、分析資料是一項複雜的挑戰。
不平坦的資料分析之路
除了資料科學家、資料工程師,現在營運、DevOps工程師、使用者支援等角色也在分析日志。假設有
N
種日志使用者,對于
M
種類型日志,可能會産生
N*M
種日志存儲、分析需求。
- 分析首先需要完整的資料采集,尤其是對大規模資料的內建、預處理和降維能力。
- 多元使用者意味着多樣化工具棧,資料應該儲存在開放的存儲系統,并且可以被更多的工具處理。
- 在傳統的離線分析之外,越來越多的延遲敏感型應用出現,資料得不到及時處理會喪失其大部分價值。

上圖(interana.com, State of Data Insights 2017統計)反映了一個事實:73%的人需要花費幾天甚至數星期時間從資料中得到分析結果。
另一個被廣泛傳播的數字:在資料分析過程中,資料內建和預處理所耗費的時間占總體80%以上。
ETL已死?
完成各個資料源采集,接着以盡量統一的方式(UI、模型、計算架構)對資料做加工、查詢。其中,ETL是關鍵的技術。
近一兩年來,看到一些關于”ETL已死“的文章。但關鍵問題還沒有解決:
-
OLAP + OLTP
- 衆多ETL pipeline維護的複雜性源自資料業務的複雜,例如:資料采集流程、預處理作業依賴。
是以,銀彈還沒有出現,對業務需求進行抽象,根據技術名額做合理的存儲、計算選型是一個行之有效的辦法。ETL沒有消失,也在演進:
- 實時化ETL,無論是資料的采集還是預處理階段。
- 随着一些存儲、計算系統能力的增強,ETL的過程在向存儲系統遷移。例如:過去在資料庫難以實作大規模預處理,需要專門的ETL工具;目前則可以在一個分布式數倉内做ELT,完成系統内資料流轉。
- 中心化采集到統一存儲後加工(類Kafka模式),一定程度上優化了複雜業務上ETL網狀資料拓撲。
- 資料湖為代表的schema-on-read模式,讓ETL的發生後置。
資料預處理的流派
資料預處理是本文主題,在多年的ETL技術發展中誕生了很多相關系統。這裡選取一部分做回顧:
采集端系統
日志領域,以Logstash(注:新版本支援hosted模式)、Fluentd、Flume、NXLog、Logtail(阿裡巴巴)為代表,可以在采集階段利用機器資源完成一定程度的預處理,不需要專用計算叢集做預處理。不足之處是:
- 可用性,一旦單機用戶端非預期失效,資料鍊路也會斷掉。
- 很多資料源是易失的,在用戶端、插件出問題時或業務邏輯改變時,資料重放是困難的。
- ETL運維的複雜度難以得到改善,配置散落在衆多機器上,加工邏輯變更或作業運維大多依賴機器上操作。
- 單機節點可能出現日志生産大于消費情況(取決于軟體實作的性能),導緻處理瓶頸。
資料庫系統
它們首先是存儲系統,基于行、列存儲模型優化,支援了一定的複雜計算能力。經典的如SQL Server、Oracle資料庫,如今有OceanBase、Google Spanner這樣的分布式資料庫。
絕大部分資料庫多用于存儲清洗後的資料,用于線上服務場景。
批量計算系統
以Hive、MapReduce計算為代表的Hadoop生态系統,主要是面向 OLAP、批操作設計。以可擴充的計算和海量存儲能力,解決了big data分析難題。
在延遲敏感型業務占比越來越大的背景下,離線系統的延遲高、互動性差,已經不能再唱獨角戲。
流計算引擎
Flink、Spark是開源社群非常流行的流計算系統,流模式讓ETL變得實時化,定位于通用場景。
雲上資料平台
以Alooma、AWS Glue、Azure DataFactory、阿裡雲DataWorks、Google Cloud DataProc為代表,各個雲服務廠商基于的存儲、計算服務,在一個系統上為使用者提供通用、綜合的資料內建、開發能力。
流式存儲與計算
在很長一段時間内,以Kafka為代表的資料隊列系統被用于臨時資料存儲。經過近些年的發展,流式存儲上拓展了資料分層,基于之上的計算也已成為一個事實。例如:AWS Kinesis Streams、Kafka(KSQL/Kafka Streams)、Apache Pulsar(Pulsar Functions)。
日志服務上的資料預處理場景
阿裡雲日志服務(原SLS)是針對日志類資料的一站式服務,在阿裡巴巴集團經曆大量大資料場景錘煉而成。為使用者提供快捷的日志資料采集、消費、投遞以及查詢分析等功能,提升運維、營運效率。
資料源
在日志服務,目前每天的資料處理規模在PB級,涵蓋主要日志生态的資料源。資料內建手段包括:
- 用戶端采集:處理機器上各種各樣的日志檔案、程式名額、網絡資料包等。
- 服務端采集:以分布式、全托管服務方式采集雲産品、服務上的資料。例如:雲産品通路日志(SLB、OSS、CDN、API網關),網絡流日志(VPC、CEN),開放服務上存儲的資料(OSS檔案、MaxCompute表等)。
- 自建軟體:應用程式可以自由選擇基礎的Restful API,多種語言SDK,基于SDK進階封裝的producer lib或是logger appender上報資料。
- 協定網關:日志服務服務端對于Kafka、Syslog等資料協定提供接入網關,最小化日志采集代價。
場景與挑戰
在日志服務上,大量的、多樣的資料在日志庫(Logstore)存儲,進行資料分析要解決三個挑戰:
- 規模問題
- 廣泛類型的資料采集能力,一套存儲完成所有類型資料的集中化。
- 海量、可伸縮的集中式存儲,支撐例如審計場景下日志長期存儲場景。
- 彈性擴充的資料處理,按照業務峰谷配置計算,降低為burst高峰預留資源帶來的高額成本。
- 多元化分析需求
- 資料鍊路實時性要求變高,存儲和計算要具備微批、流的能力。
- 一份資料可以在多處被使用,讓資料開放并自由流動。
- 較好的工具內建完整度和豐富的生态對接能力,适應不同使用者的分析技術棧。
- 資料預處理的易用性
- 資料加工代碼複雜度盡量低,常見日志處理邏輯做到複用。
- 全托管、服務化處理,屏蔽運維細節(failover,資源擴容)。
- GUI幫助收斂資料流程的調試、維護成本。
資料加工功能
在日志服務,資料加工功能用于完成對Logstore資料的預處理,為後續的分析階段準備資料。
資料加工基于日志服務的流式存儲,排程動态數目的worker做計算。計算上提供豐富的算子和場景化UDF,對于複雜需求則可以通過流程控制、條件判斷實作行内邏輯組合,跨行的pipeline組合簡化資料的嵌套處理需求。
日志服務資料加工的設計
資料模型與存儲
日志服務使用一套通用的資料模型應對各種各樣的資料類型。一條Log由保留字段(時間,來源等)和日志内容(多個Key-Value對)組成:
message Log
{
required uint32 Time = 1;// UNIX Time Format
message Content
{
required string Key = 1;
required string Value = 2;
}
repeated Content Contents = 2;
} 結構化的資料可以在這個資料模型上定義出表結構:
__time__ : 1572784373
__source__ : 192.168.2.13
key_a : value a
key_b : value b 同樣的,對于非結構化或半結構化資料,可以在把全部内容放入一個字段中,并選擇性地對字段值做一些處理(例如編碼)。
日志服務存儲引擎(LogHub)實作了對資料的統一存儲,支援以下特性:
- 流式存儲,十毫秒級可見。
- 分布式服務,多拷貝保證可靠性。
- append寫入,支援增量(實時)消費以及存量(回搠位置)消費。
- 支援Ad-hoc建構索引,結合高效編碼、列存對原文存儲實作快速查詢、分析。
存儲與計算分離
資料加工實作的是脫離存儲系統之外的計算過程。基于Pull模型擷取資料,可以根據worker自身的負載情況決定資料加載的速率。worker與存儲系統的網絡請求走阿裡雲内部網絡,每次讀取批量的資料塊,結合傳輸過程的壓縮特性,保證了同region下跨系統交換資料不會成為性能瓶頸。
日志服務的一個Logstore的資料分布在多個shard上,每一個shard被append寫入資料。排程器負責以下工作:
- 管理N個worker到M個shard之間的映射關系,保證shard在數量次元上的負載均衡。
- 支援worker的水準擴充以應對大規模流量,在衆多shard情況下,協調多個worker共同、完整地處理整個Logstore的資料。
- worker的健康管理,動态地注冊新worker或踢出失效worker。
- 持久化worker對shard消費進度,例如
worker#1
shard 0/1
worker#3
彈性是雲服務的标志,在大部分日志的流量特征而言,伸縮能力顯得尤為重要。
例如:直播應用的CDN access log,
21:00 ~ 23:00
是業務通路高峰期并産生大量日志,到了淩晨
1:00 ~ 7:00
日志流量跌至高峰時的10%。按業務峰值規劃資源必将産生大量閑置成本。
處理延遲、資料規模、成本三者看起來是魚和熊掌的關系,在日志服務上,嘗試從兩個層面來彈性應對:
- 存儲:基于shard的動态merge/split能力實作對寫入存儲流量的控制,高峰時使用更多的shard。
- 計算:資料加工實作了基于流量的并發度控制,shard數目作為一個參考名額,根據目前整體的資源名額(cpu使用率等)動态擴容或縮容worker數目。
作業模式
日志處理場景下繞不過的是時間,時間的定義确又不那麼簡單。
| 名稱 | 定義 | 日志服務上應用 |
|---|---|---|
| event-time | 事件時間,真實的業務時間 | 一般建議設定值到 |
| server-arrived-time | 該事件到達服務端時間 | 日志服務在接收資料時記錄值并填入 |
| processing-time | 資料加工處理該事件的時間 | 不确定,取決于作業模式以及加工速率 |
對于一個加工任務而言,加工的延遲定義為
processing-time
-
server-arrived-time(latest log)
。由于資料可能遲到或生産者發送了亂序資料,
event-time
與
server-arrived-time
、
processing-time
可能會有較大差異。
資料加工根據
server-arrived-time
定義資料源範圍,并提供兩種作業模式:
- 實時模式:持續運作并加載新到來資料,無界的流任務,
[FROM server-arrived-time, -)
- 區間模式:有界的任務,
[FROM server-arrived-time, TO server-arrived-time)
場景化UDF
相較于業内流行的SQL、DSL、Python等ETL語言,日志服務資料加工提供的是類Python DSL,封裝了日志領域下通用加工過程。
作為業務邏輯開發的重要一環,資料加工DSL提供以下能力:
- 函數級能力:支援資料過濾、抽取、分裂、富化、分發操作,可以快速解決如JSON、Nginx access log、Syslog日志解析等場景。
- 行内組合能力:通過條件判斷與流程控制,可以組合多個函數調用完成複雜操作,例如:
e_if_else(condition_1, e_compose(operation_1, operation_2, operation_3), operation_4)
- 跨行組合能力:常用于資料處理pipeline,作用類似SQL子查詢。資料加工跨行組合是類管道式文法,從代碼調試效率和可讀性上看,比SQL子查詢表現更好。
例如,在資料加工DSL中實作對一條日志的分裂、拷貝、條件判斷,其内部編排邏輯如下圖:
DevOps效率
開發、運維效率是考量資料流程維護成本的重要名額。
日志服務資料加工是全托管的服務,使用它不感覺機器資源,通過web控制台實作對作業的管理與監控。
- 開發與調試:web控制台操作。
- 部署與疊代:調試完成的代碼一鍵儲存作業運作。DSL代碼更新後,控制台上進行重新開機完成重新部署。
- 名額監控:包括概覽、加工吞吐、shard級消費延遲與速率名額。
- 診斷日志:彙聚了加工過程錯誤日志,可以根據reason字段進行細節定位。
- 作業告警:在加工任務運作名額的儀表盤上,可以對某個名額設定監控告警,也可以訂閱儀表盤發送到釘釘webhook。做到對資料加工作業的運作狀态的充分掌握。
基于資料加工的場景實踐
流動的資料
在日志的整個生命周期内,資料采集到日志服務存儲,資料加工在這之後起着承轉啟合作用。通過資料加工完成清洗、預處理、分發,讓資料在生态流轉起來,并更好地适配目标存儲的schema要求。
規整
資料規整包括字段抽取、過濾、清洗等工作,完成後資料被轉儲到下遊。規整的意義在于能為下遊帶來哪些幫助:
- Logstore的資料規整後寫入新Logstore,在後者基礎上精細化Key-Value索引可以幫助優化成本,提升查詢分析效率,讓儀表盤與告警表達更加豐富。
- Logstore資料規整後寫入OSS bucket,如此建構的資料湖可以大大優化存儲成本和後續分析效率。參考 Analyzing Data in S3 using Amazon Athena 數字,對于S3上的ELB通路日志,結構化良好的parquet檔案對比普通text檔案,可以縮小87%存儲空間并在部分場景下提升34倍分析效率。
- Logstore資料規整後寫入資料庫是剛需,整條日志原文存儲資料庫在後續面臨性能開銷、不規則資料帶來計算不确定性(可能引入複雜的相容邏輯)。
如下,content字段是完整的Syslog日志原文,這樣一條非結構化資料,通過兩行加工代碼分别完成Syslog字段抽取、priority字段映射。
對于JSON格式的結構化日志,如下兩行代碼通過JMES文法對數組做分拆,分拆後每個子對象分别做嵌套字段提取。
更多實踐:
資料脫敏 日志時間處理 複雜JSON字段提取 類JSON、非标準JSON、XML格式解析 分隔符日志字段提取 Key-Value格式字段提取 Ngnix日志解析 Syslog資料解析分發
日志分發、複制是一種典型的資料場景。
例如:Kubernetes上采集的衆多pod日志集中化到一個Logstore上,可以通過資料加工快速實作按namespace轉發到下遊Logstore,在下遊Logstore上分别設定存儲周期、索引分析字段。
資料除了在Logstore之間做流轉以外,還可以流向異構存儲系統,例如投遞到OSS、MaxCompute、ADB等。
富化
對于一個典型的
SLB+ECS+Nginx
架構,Nginx access log上包括請求來源(
__source__
字段,記錄vpc子網ip)、請求資源(
request_uri
字段,參數記錄了業務租戶的project資訊)。
RDS中維護了兩張維表:
- 使用者元資訊表,主鍵為業務租戶的project資訊。
- ECS伺服器元資訊表,主鍵為内網ip。
資料加工首先對
request_uri
做參數拆分,擷取project資訊。接下來分别通過ip與project值與兩個維表做join,得到結果是更完整的日志資訊(包括後端伺服器的tag、租戶project的打标内容)。
資料加工目前支援四種資料源做查找富化:本地配置、RDS表、OSS檔案、日志服務Logstore。
從RDS MySQL擷取資料做富化 從OSS檔案擷取資料做富化 從日志服務 Logstore擷取資料做富化 自定義條件實作資料富化的複雜映射寫在最後,ETL業務場景千變萬化,資料加工在資料分析場景支撐的路上将持續疊代優化。