作者 | 螞蟻金服技術專家 滄漠
關注『阿裡巴巴雲原生』公衆号,回複關鍵詞“1024”,可擷取本文 PPT。
前言
Kubernetes 以其超前的設計理念和優秀的技術架構,在容器編排領域拔得頭籌。越來越多的公司開始在生産環境部署實踐 Kubernetes,在阿裡巴巴和螞蟻金服 Kubernetes 已被大規模用于生産環境。Kubernetes 的出現使得廣大開發同學也能運維複雜的分布式系統,它大幅降低了容器化應用部署的門檻,但運維和管理一個生産級的高可用 Kubernetes 叢集仍十分困難。本文将分享螞蟻金服是如何有效可靠地管理大規模 Kubernetes 叢集的,并會詳細介紹叢集管理系統核心元件的設計。
系統概覽
Kubernetes 叢集管理系統需要具備便捷的叢集生命周期管理能力,完成叢集的建立、更新和工作節點的管理。在大規模場景下,叢集變更的可控性直接關系到叢集的穩定性,是以管理系統可監控、可灰階、可復原的能力是系統設計的重點之一。除此之外,超大規模叢集中,節點數量已經達到 10K 量級,節點硬體故障、元件異常等問題會常态出現。面向大規模叢集的管理系統在設計之初就需要充分考慮這些異常場景,并能夠從這些異常場景中自恢複。
設計模式
基于這些背景,我們設計了一個面向終态的叢集管理系統。系統定時檢測叢集目前狀态,判斷是否與目标狀态一緻,出現不一緻時,Operators 會發起一系列操作,驅動叢集達到目标狀态。這一設計參考控制理論中常見的負回報閉環控制系統,系統實作閉環,可以有效抵禦系統外部的幹擾,在我們的場景下,幹擾對應于節點軟硬體故障。
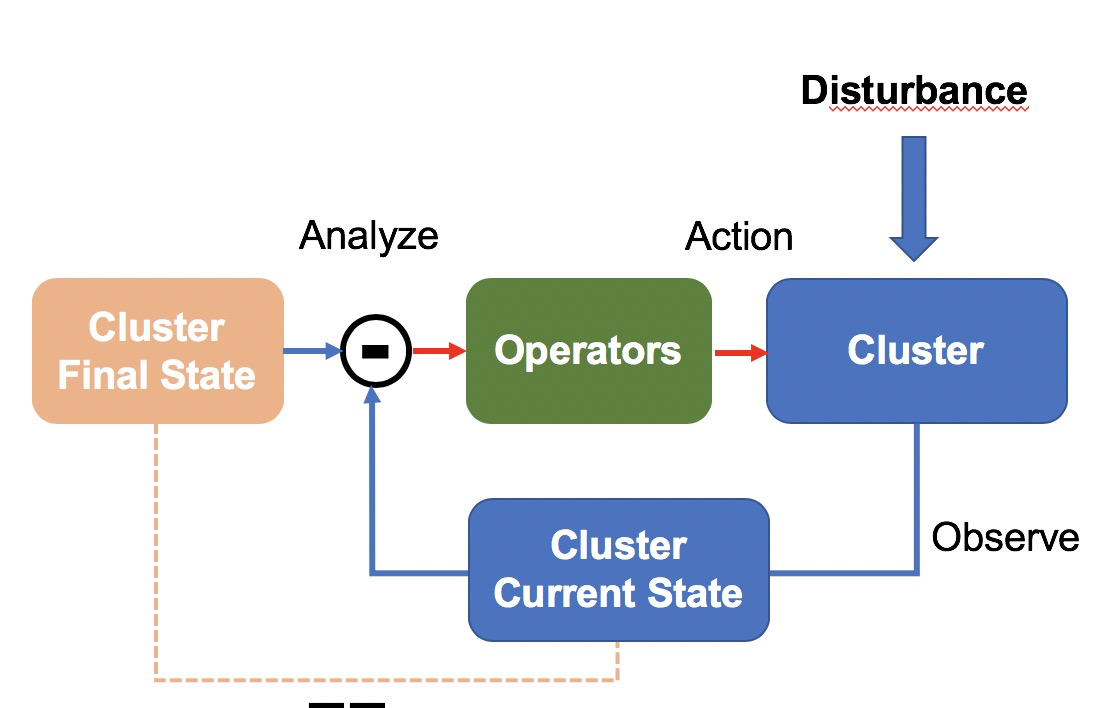
架構設計

如上圖,元叢集是一個高可用的 Kubernetes 叢集,用于管理 N 個業務叢集的 Master 節點。業務叢集是一個服務生産業務的 Kubernetes 叢集。SigmaBoss 是叢集管理入口,為使用者提供便捷的互動界面和可控的變更流程。
元叢集中部署的 Cluster-Operator 提供了業務叢集叢集建立、删除和更新能力,Cluster-Operator 面向終态設計,當業務叢集 Master 節點或元件異常時,會自動隔離并進行修複,以保證業務叢集 Master 節點達到穩定的終态。這種采用 Kubernetes 管理 Kubernetes 的方案,我們稱作 Kube on Kube 方案,簡稱 KOK 方案。
業務叢集中部署有 Machine-Operator 和節點故障自愈元件用于管理業務叢集的工作節點,提供節點新增、删除、更新和故障處理能力。在 Machine-Operator 提供的單節點終态保持的能力上,SigmaBoss 上建構了叢集次元灰階變更和復原能力。
核心元件
叢集終态保持器
基于 K8S CRD,在元叢集中定義了 Cluster CRD 來描述業務叢集終态,每個業務叢集對應一個 Cluster 資源,建立、删除、更新 Cluster 資源對應于實作業務叢集建立、删除和更新。Cluster-Operator watch Cluster 資源,驅動業務叢集 Master 元件達到 Cluster 資源描述的終态。
業務叢集 Master 元件版本集中維護在 ClusterPackageVersion CRD 中,ClusterPackageVersion 資源記錄了 Master 元件(如:api-server、controller-manager、scheduler、operators 等)的鏡像、預設啟動參數等資訊。Cluster 資源唯一關聯一個 ClusterPackageVersion,修改 Cluster CRD 中記錄的 ClusterPackageVersion 版本即可完成業務叢集 Master 元件釋出和復原。
節點終态保持器
Kubernetes 叢集工作節點的管理任務主要有:
- 節點系統配置、核心更新檔管理
- docker / kubelet 等元件安裝、更新、解除安裝
- 節點終态和可排程狀态管理(如關鍵 DaemonSet 部署完成後才允許開啟排程)
- 節點故障自愈
為實作上述管理任務,在業務叢集中定義了 Machine CRD 來描述工作節點終态,每一個工作節點對應一個 Machine 資源,通過修改 Machine 資源來管理工作節點。
Machine CRD 定義如下圖所示,spec 中描述了節點需要安裝的元件名和版本,status 中記錄有目前這個工作節點各元件安裝運作狀态。除此之外,Machine CRD 還提供了插件式終态管理能力,用于與其它節點管理 Operators 協作,這部分會在後文詳細介紹。
工作節點上的元件版本管理由 MachinePackageVersion CRD 完成。MachinePackageVersion 維護了每個元件的 rpm 版本、配置和安裝方法等資訊。一個 Machine 資源會關聯 N 個不同的 MachinePackageVersion,用來實作安裝多個元件。
在 Machine、MachinePackageVersion CRD 基礎上,設計實作了節點終态控制器 Machine-Operator。Machine-Operator watch Machine 資源,解析 MachinePackageVersion,在節點上執行運維操作來驅動節點達到終态,并持續守護終态。
節點終态管理
随着業務訴求的變化,節點管理已不再局限于安裝 docker / kubelet 等元件,我們需要實作如等待日志采集 DaemonSet 部署完成才可以開啟排程的需求,而且這類需求變得越來越多。如果将終态統一交由 Machine-Operator 管理,勢必會增加 Machine-Operator 與其它元件的耦合性,而且系統的擴充性會受到影響。是以,我們設計了一套節點終态管理的機制,來協調 Machine-Operator 和其它節點運維 Operators。設計如下圖所示:
- 全量 ReadinessGates:記錄節點可排程需要檢查的 Condition 清單
- Condition ConfigMap:各節點運維 Operators 終态狀态上報 ConfigMap
協作關系:
- 外部節點運維 Operators 檢測并上報與自己相關的子終态資料至對應的 Condition ConfigMap;
- Machine-Operator 根據标簽擷取節點相關的所有子終态 Condition ConfigMap,并同步至 Machine status 的 conditions中
- Machine-Operator 根據全量 ReadinessGates 中記錄的 Condition 清單,檢查節點是否達到終态,未達到終态的節點不開啟排程
我們都知道實體機硬體存在一定的故障機率,随着叢集節點規模的增加,叢集中會常态出現故障節點,如果不及時修複上線,這部分實體機的資源将會被閑置。
為解決這一問題,我們設計了一套故障發現、隔離、修複的閉環自愈系統。
如下圖所示,故障發現方面,采取 Agent 上報和監控系統主動探測相結合的方式,保證了故障發現的實時性和可靠性(Agent 上報實時性比較好,監控系統主動探測可以覆寫 Agent 異常未上報場景)。故障資訊統一存儲于事件中心,關注叢集故障的元件或系統都可以訂閱事件中心事件拿到這些故障資訊。
節點故障自愈系統會根據故障類型建立不同的維修流程,例如:硬體維系流程、系統重裝流程等。維修流程中優先會隔離故障節點(暫停節點排程),然後将節點上 Pod 打上待遷移标簽來通知 PAAS 或 MigrateController 進行 Pod 遷移,完成這些前置操作後,會嘗試恢複節點(硬體維修、重裝作業系統等),修複成功的節點會重新開啟排程,長期未自動修複的節點由人工介入排查處理。
風險防範
在 Machine-Operator 提供的原子能力基礎上,系統中設計實作了叢集次元的灰階變更和復原能力。此外,為了進一步降低變更風險,Operators 在發起真實變更時都會進行風險評估,架構示意圖如下。
高風險變更操作(如:删除節點、重裝系統)接入統一限流中心,限流中心維護了不同類型操作的限流政策,若觸發限流,則熔斷變更。
為了評估變更過程是否正常,我們會在變更前後,對各元件進行健康檢查,元件的健康檢查雖然能夠發現大部分異常,但不能覆寫所有異常場景。是以,風險評估過程中,系統會從事件中心、監控系統中擷取叢集業務名額(如:Pod建立成功率),如果出現異常名額,則自動熔斷變更。
結束語
本文主要和大家分享了現階段螞蟻金服 Kubernetes 叢集管理系統的核心設計,核心元件大量使用 Operator 面向終态設計模式。這套面向終态的叢集管理系統在今年備戰雙11過程中,經受了性能和穩定性考驗。
一個完備的叢集管理系統除了保證叢集穩定性和運維效率外,還應該提升叢集整體資源使用率。接下來,我們會從提升節點線上率、降低節點閑置率等方面出發,來提升螞蟻金服生産叢集的資源使用率(P.S.螞蟻金服-系統部-資源排程組正在招聘,加入我們,一起來解決世界級難題吧!)。
Q & A
Q1:目前公司絕大多數應用已部署在 Docker 中 ,如何向 K8s 轉型?是否有案例可以借鑒?
A1:我在螞蟻工作了将近 5 年,螞蟻的業務由最早跑在 xen 虛拟機中,到現在跑在 Docker 裡由 K8s 排程,基本上每年都在疊代。K8s 是一個非常開放的 “PaaS” 架構,如果已經部署在 Docker 中,符合“雲原生”應用特性,遷移 K8s 理論上會比較平滑。螞蟻由于曆史包袱比較重,在實踐過程中,為了相容業務需求,對 K8s 做了一些增強,保證業務能平滑遷移過來。
Q2:應用部署在 K8s 及 Docker 中會影響性能嗎?例如大資料處理相關的任務是否建議部署到 K8s 中?
A2:我了解 Docker 是容器,不是虛拟機,對性能的影響是有限的。螞蟻大資料、AI 等業務都已經在遷移 K8s 與線上應用混部。大資料類對時間不敏感業務,可以很好地利用叢集空閑資源,混部後可大幅降低資料中心成本。
Q3:K8s 叢集和傳統的運維環境怎麼更好的結合?現在公司肯定不會全部上 K8s。
A3:基礎設施不統一會導緻資源沒有辦法統一進行排程,另外維護兩套相對獨立的運維系統,代價是非常大的。螞蟻在遷移過程中實作了一個“Adapter”,将傳統建立容器或釋出的指令轉換成 K8s 資源修改來做“橋接”。
Q4:Node 監控是怎麼做的,Node 挂掉會遷移 Pod 嗎?業務不允許自動遷移呢?
A4:Node 監控分為硬體、系統級、元件級,硬體監控資料來自 IDC,系統級監控使用内部自研監控平台,元件(kubelet/pouch 等)監控我們擴充 NPD,提供 exporter 暴露接口給監控系統采集。Node 出現異常,會自動遷移 Pod。有些帶狀态的業務,業務方自己定制 operator 來實作 Pod 自動遷移。不具備自動遷移能力的 Pod, 超期後會自動銷毀。
Q5:整個 K8s 叢集未來是否會對開發透明,使用代碼面向叢集程式設計或編寫部署檔案,不再需要按容器去寫應用及部署,是否有這種規劃?
A5:K8s 提供了非常多建構 PaaS 平台的擴充能力,但現在直接面向 K8s 去部署應用的确非常困難。我覺得采用某種 DSL 去部署應用是未來的趨勢,K8s 會成為這些基礎設施的核心。
Q6:我們目前采用 kube-to-kube 的方式管理叢集,kube-on-kube 相比 kube-to-kube 的優勢在哪?在大規模場景下,K8s 叢集的節點伸縮過程中,性能瓶頸在哪?是如何解決的?
A6:目前已經有非常多的 CI/CD 流程跑在 K8s 之上。采用 kube-on-kube 方案,我們可以像管理普通業務 App 那樣管理業務叢集的管控。節點上除運作 kubelet pouch 外,還會額外運作很多 daemonset pod,大規模新增節點時,節點元件會對 apiserver 發起大量 list/watch 操作,我們的優化主要集中在 apiserver 性能提升,和配合 apiserver 降低節點全量 list/watch。
Q7:滄漠你好,因為我們公司還沒有上 K8s,所有我想請教以下幾個問題:K8s 對我們有什麼好處?能夠解決目前的什麼問題?優先在哪些業務場景、流程環節使用?現有基礎設施能否平滑切換到 Kubernetes?
A7:我覺得 K8s 最大的不同在于面向終态的設計理念,不再是一個一個運維動作。這對于複雜的運維場景來說,非常有益。從螞蟻的更新實踐看,平滑是可以做到的。
Q8:cluster operator 是 Pod 運作,用 Pod 啟動業務叢集 master,然後 machine operator 是實體機運作?
A8:operator 都運作在 Pod 裡面的,cluster operator 将業務叢集的 machine operator 拉起來。
Q9:你好!請問一下,為應對像雙十一這樣的高并發場景,多少量級的元叢集的規模對應管理多少量級的業務叢集合适?就我的了解,cluster operator 應該是對資源的 list watch,面對大規模的并發場景,你們做了哪些方面的優化?
A9:一個叢集可以管理萬級節點,是以元叢集理論上可以管理 3K+ 業務叢集。
Q10:節點如果遇到系統核心、Docker、K8s 異常,如何從軟體層面最大化保證系統正常?
A10:具備健康檢查能力,主動退出,由 K8s 發現,并重新在其它節點拉起。
“ 阿裡巴巴雲原生微信公衆号(ID:Alicloudnative)關注微服務、Serverless、容器、Service Mesh等技術領域、聚焦雲原生流行技術趨勢、雲原生大規模的落地實踐,做最懂雲原生開發者的技術公衆号。”