String 對象的實作
String對象是 Java 中使用最頻繁的對象之一,是以 Java 公司也在不斷的對String對象的實作進行優化,以便提升String對象的性能,看下面這張圖,一起了解一下String對象的優化過程。
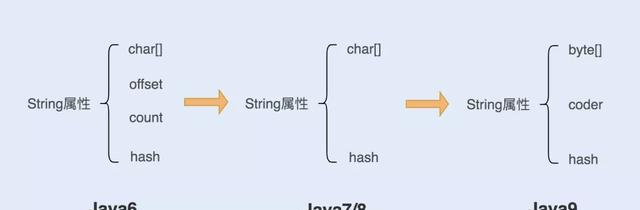
1. 在 Java6 以及之前的版本中
String對象是對 char 數組進行了封裝實作的對象,主要有四個成員變量:char 數組、偏移量 offset、字元數量 count、哈希值 hash。
String對象是通過 offset 和 count 兩個屬性來定位 char[] 數組,擷取字元串。這麼做可以高效、快速地共享數組對象,同時節省記憶體空間,但這種方式很有可能會導緻記憶體洩漏。
2. 從 Java7 版本開始到 Java8 版本
從 Java7 版本開始,Java 對String類做了一些改變。String類中不再有 offset 和 count 兩個變量了。這樣的好處是String對象占用的記憶體稍微少了些,同時 String.substring 方法也不再共享 char[],進而解決了使用該方法可能導緻的記憶體洩漏問題。
3. 從 Java9 版本開始
将 char[] 數組改為了 byte[] 數組,為什麼需要這樣做呢?我們知道 char 是兩個位元組,如果用來存一個位元組的字元有點浪費,為了節約空間,Java 公司就改成了一個位元組的byte來存儲字元串。這樣在存儲一個位元組的字元是就避免了浪費。
在 Java9 維護了一個新的屬性 coder,它是編碼格式的辨別,在計算字元串長度或者調用 indexOf() 函數時,需要根據這個字段,判斷如何計算字元串長度。coder 屬性預設有 0 和 1 兩個值, 0 代表Latin-1(單位元組編碼),1 代表 UTF-16 編碼。如果 String判斷字元串隻包含了 Latin-1,則 coder 屬性值為 0 ,反之則為 1。

String 對象的建立方式
1、通過字元串常量的方式
String str= "pingtouge"的形式,使用這種形式建立字元串時, JVM 會在字元串常量池中先檢查是否存在該對象,如果存在,傳回該對象的引用位址,如果不存在,則在字元串常量池中建立該字元串對象并且傳回引用。使用這種方式建立的好處是:避免了相同值的字元串重複建立,節約了記憶體。
2、String()構造函數的方式
String str = new String("pingtouge")的形式,使用這種方式建立字元串對象過程就比較複雜,分成兩個階段,首先在編譯時,字元串pingtouge會被加入到常量結構中,類加載時候就會在常量池中建立該字元串。然後就是在調用new()時,JVM 将會調用String的構造函數,同時引用常量池中的pingtouge字元串,在堆記憶體中建立一個String對象并且傳回堆中的引用位址。
了解了String對象兩種建立方式,我們來分析一下下面這段代碼,加深我們對這兩種方式的了解,下面這段代碼片中,str是否等于str1呢?
String str = "pingtouge";
String str1 = new String("pingtouge");
system.out.println(str==str1)
我們逐一來分析這幾行代碼,首先從String str = "pingtouge"開始,這裡使用了字元串常量的方式建立字元串對象,在建立pingtouge字元串對象時,JVM會去常量池中查找是否存在該字元串,這裡的答案肯定是沒有的,是以JVM将會在常量池中建立該字元串對象并且傳回對象的位址引用,是以str指向的是pingtouge字元串對象在常量池中的位址引用。
然後是String str1 = new String("pingtouge")這行代碼,這裡使用的是構造函數的方式建立字元串對象,根據我們上面對構造函數方式建立字元串對象的了解,str1得到的應該是堆中pingtouge字元串的引用位址。由于str指向的是pingtouge字元串對象在常量池中的位址引用而str1指向的是堆中pingtouge字元串的引用位址,是以str肯定不等于str1。
String 對象的不可變性
從我們知道String對象的那一刻起,我想大家都知道了String對象是不可變的。那它不可變是怎麼做到的呢?Java 這麼做能帶來哪些好處?我們一起來簡單的探讨一下,先來看看String 對象的一段源碼:
public final class String
implements java.io.Serializable, Comparable, CharSequence {
/* The value is used for character storage. /
private final char value[];
/* Cache the hash code for the string /
private int hash; // Default to 0
/* use serialVersionUID from JDK 1.0.2 for interoperability /
private static final long serialVersionUID = -6849794470754667710L;
}
從這段源碼中可以看出,String類用了 final 修飾符,我們知道當一個類被 final 修飾時,表明這個類不能被繼承,是以String類不能被繼承。這是String不可變的第一點
再往下看,用來存儲字元串的char value[]數組被private 和final修飾,我們知道對于一個被final的基本資料類型的變量,則其數值一旦在初始化之後便不能更改。這是String不可變的第二點。
Java 公司為什麼要将String設定成不可變的,主要從以下三方面考慮:
1、保證 String 對象的安全性。假設 String 對象是可變的,那麼 String 對象将可能被惡意修改。
2、保證 hash 屬性值不會頻繁變更,確定了唯一性,使得類似 HashMap 容器才能實作相應的 key-value 緩存功能。
3、可以實作字元串常量池
String 對象的優化
字元串是我們常用的Java類型之一,是以對字元串的操作也是避免不了的,在對字元串的操作過程中,如果使用不當,性能會天差地别。那麼在字元串的操作過程中,有哪些地方需要我們注意呢?
優雅的拼接字元串
字元串的拼接是對字元串操作使用最頻繁的操作之一,由于我們知道String對象的不可變性,是以我們在做拼接時盡可能少的使用+進行字元串拼接或者說潛意識裡認為不能使用+進行字元串拼接,認為使用+進行字元串拼接會産生許多無用的對象。事實真的是這樣嗎?我們來做一個實驗。我們使用+來拼接下面這段字元串。
String str8 = "ping" +"tou"+"ge";
一起來分析一下這段代碼會産生多少個對象?如果按照我們了解的意思來分析的話,首先會建立ping對象,然後建立pingtou對象,最後才會建立pingtouge對象,一共建立了三個對象。真的是這樣嗎?其實不是這樣的,Java 公司怕我們程式員手誤,是以對編譯器進行了優化,上面的這段字元串拼接會被我們的編譯器優化,優化成一個String str8 = "pingtouge";對象。除了對常量字元串拼接做了優化以外,對于使用+号動态拼接字元串,編譯器也做了相應的優化,以便提升String的性能,例如下面這段代碼:
for(int i=0; i<1000; i++) {
str = str + i;
}
編譯器會幫我們優化成這樣:
str = (new StringBuilder(String.valueOf(str))).append(i).toString();
可以看出 Java 公司對這一塊進行了不少的優化,防止由于程式員不小心導緻String性能急速下降,盡管 Java 公司在編譯器這一塊做了相應的優化,但是我們還是能看出 Java 公司優化的不足之處,在動态拼接字元串時,雖然使用了 StringBuilder 進行字元串拼接,但是每次循環都會生成一個新的 StringBuilder 執行個體,同樣也會降低系統的性能。
是以我們在做字元串拼接時,我們需要從代碼的層面進行優化,在動态的拼接字元串時,如果不涉及到線程安全的情況下,我們顯示的使用 StringBuilder 進行拼接,提升系統性能,如果涉及到線程安全的話,我們使用 StringBuffer 來進行字元串拼接
巧妙的使用 intern() 方法
- When the intern method is invoked, if the pool already contains a
- string equal to this {@code String} object as determined by
- the {@link #equals(Object)} method, then the string from the pool is
-
- Otherwise, this {@code String} object is added to the
- pool and a reference to this {@code String} object is returned.
- native String intern();
這是 intern() 函數的官方注釋說明,大概意思就是 intern 函數用來傳回常量池中的某字元串,如果常量池中已經存在該字元串,則直接傳回常量池中該對象的引用。否則,在常量池中加入該對象,然後 傳回引用。
有一位Twitter工程師在QCon全球軟體開發大會上分享了一個他們對 String對象優化的案例,他們利用String.intern()方法将以前需要20G記憶體存儲優化到隻需要幾百兆記憶體。這足以展現String.intern()的威力,我們一起來看一個例子,簡單的了解一下String.intern()的用法。
public static void main(String[] args) {
String str = new String("pingtouge");
System.out.println("未使用intern()方法:"+(str==str1));
System.out.println("未使用intern()方法,str:"+str);
System.out.println("未使用intern()方法,str1:"+str1);
String str2= new String("pingtouge").intern();
String str3 = new String("pingtouge").intern();
System.out.println("使用intern()方法:"+(str2==str3));
System.out.println("使用intern()方法,str2:"+str2);
System.out.println("使用intern()方法,str3:"+str3);
從結果中可以看出,未使用String.intern()方法時,構造相同值的字元串對象傳回不同的對象引用位址,使用String.intern()方法後,構造相同值的字元串對象時,傳回相同的對象引用位址。這能幫我們節約不少空間。
String.intern()方法雖然好,但是我們要結合場景使用,不能亂用,因為常量池的實作是類似于一個HashTable的實作方式,HashTable 存儲的資料越大,周遊的時間複雜度就會增加。如果資料過大,會增加整個字元串常量池的負擔。
靈活的字元串的分割
字元串的分割是字元串操作的常用操作之一,對于字元串的分割,大部分人使用的都是 Split() 方法,Split() 方法大多數情況下使用的是正規表達式,這種分割方式本身沒有什麼問題,但是由于正規表達式的性能是非常不穩定的,使用不恰當會引起回溯問題,很可能導緻 CPU 居高不下。在以下兩種情況下 Split() 方法不會使用正規表達式:
傳入的參數長度為1,且不包含“.$|()[{^?*+”regex元字元的情況下,不會使用正規表達式
傳入的參數長度為2,第一個字元是反斜杠,并且第二個字元不是ASCII數字或ASCII字母的情況下,不會使用正規表達式
是以我們在字元串分割時,應該慎重使用 Split() 方法,首先考慮使用 String.indexOf() 方法進行字元串分割,如果 String.indexOf() 無法滿足分割要求,再使用 Split() 方法,使用 Split() 方法分割字元串時,需要注意回溯問題。
文章不足之處,望大家多多指點,共同學習,共同進步