作者:DeeperMan
概述
資料抽取是指從源資料抽取所需要的資料, 是建構資料中台的第一步。 資料源一般是關系型資料庫,近幾年,随着移動網際網路的蓬勃發展,出現了其他類型的資料源,典型的如網站浏覽日期、APP浏覽日志、IoT裝置日志
從技術實作方式來講,從關系型資料庫擷取資料,可以細分為全量抽取、增量抽取2種方式,兩種方法分别适用于不用的業務場景
增量抽取
- 時間戳方式
用時間戳方式抽取增量資料很常見,業務系統在源表上新增一個時間戳字段,建立、修改表記錄時,同時修改時間戳字段的值。 抽取任務運作時,進行全表掃描,通過比較抽取任務的業務時間、時間戳字段來決定抽取哪些資料。
此種資料同步方式,在準确率方面有兩個弊端:
1、隻能擷取最新的狀态,無法捕獲過程變更資訊,比如電商購物場景,如果客戶下單後很快支付,隔天抽取增量資料時,隻能擷取最新的支付狀态,下單時的狀态有可能已經丢失。針對此種問題,需要根據業務需求來綜合判定是否需要回溯狀态。
2、會丢失已經被delete的記錄。如果在業務系統中,将記錄實體删除。也就無法進行增量抽取。一般情況下,要求業務系統不删除記錄,隻對記錄進行打标。
業務系統維護時間戳
如果使用了Oracle、DB2等傳統關系型資料庫,需要業務系統維護時間戳字段,業務系統在更新業務資料時,在代碼中更新時間戳字段。此種方法很常見,不過由于需要編碼實作,工作量會變大,有可能會出現漏變更的情形
觸發器維護時間戳
典型的關系型資料庫,都支援觸發器。當資料庫記錄有變更時,調用特定的函數,更新時間戳字段。典型的樣例如下:
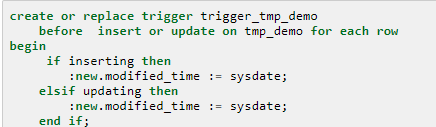
資料庫維護時間戳
MySQL可以自動實作變更字段的維護,一定程度上減輕了開發工作量。 具體的實作樣例如下:
建立記錄

最終的結果如下:
更新記錄
最終的結果如下,資料庫自動變更了時間戳字段:
- 分析MySQL binlog日志
近幾年,随着網際網路的蓬勃發展,網際網路公司一般使用MySQL作為主資料庫,由于是開源資料庫,很多公司都做了定制化開發。 其中一個很大的功能點是通過訂閱MySQL binlog日志,實作了讀寫分離、主備實時同步,典型的示意圖如下:
解析binlog日志,給資料同步帶來了新的方法,将解析之後結果發送到Hive/MaxCompute等大資料平台,實作秒級延時的資料同步。
解析binlog日志增量同步方式技術很先進,有3個非常大的優點:
1.資料延時小。在阿裡巴巴雙11場景,在巨大的資料量之下,可以做到秒級延時;
2.不丢失資料,可以捕獲資料delete的情形;
3.對業務表無額外要求,可以缺少時間戳字段;
當然,這種同步方式也有些缺點:
1.技術門檻很高。一般公司的技術儲備不夠,不足以自行完成整個系統搭建。目前國内也僅限于頭部的網際網路公司、大型的國企、央企。不過随着雲計算的快速發展,在阿裡雲上開放了工具、服務,可以直接實作實時同步,經典的組合是MySQL、DTS、Datahub、MaxCompute;
2.資源成本比較高,要求有一個系統實時接收業務庫的binlog日志,一直處于運作狀态,占用資源較多
3.業務表中需要有主鍵,以便進行資料排序
- 分析Oracle Redo Log日志
Oracle是功能非常強大的資料庫,通過Oracle GoldenGate實時解析Redo Log日志,并将解析後的結果釋出到指定的系統
全量抽取
全量抽取是将資料源中的表或視圖的資料原封不動的從資料庫中抽取出來,并寫入到Hive、MaxCompute等大資料平台中,有點類似于業務庫之間的資料遷移。
全量同步比較簡單,常用于小資料量的離線同步場景。不過這種同步方法,也有兩個弊端,與增量離線同步一模一樣:
1.隻能擷取最新的狀态
2.會丢失已經被delete的記錄
業務庫表同步政策
-
同步架構圖
從業務視角,可以将離線資料表同步細分為4個場景,總體架構圖表如下:
原則上,在資料上雲這個環節,建議隻進行資料鏡像同步。不進行業務相關的資料轉換工作。從ETL政策轉變為ELT,出發點有3個:
1.機器成本。在庫外進行轉換,需要額外的機器,帶來新的成本;
2.溝通成本。 業務系統的開發人員,也是資料中台的使用者,這些技術人員對原始的業務庫表很熟悉,如果進行了額外的轉換,他們需要額外的學習其他工具、産品;
3.執行效率。庫外的轉換機器性能,一般會低于MaxCompute、Hadoop叢集,增加了執行時間;
同步過程中,建議全表所有字段上雲,減少後期變更成本
-
小資料量表
來源資料每日全量更新,采用資料庫直連方式全量抽取,寫入每日/每月全量分區表。
-
日志型表
原始日志增量抽取到每日增量表,按天增量存儲。因為日志資料表現為隻會有新增不會有修改的情況,是以不需要儲存全量表。
-
大資料量表
資料庫直連方式通過業務時間戳抽取增量資料到今日增量分區表,再将今日增量分區表merge前一日全量分區表,寫入今日全量分區表。
-
小時/分鐘增量表/不定期全量
來源資料更新頻率較高,達到分鐘/小時級别,從源資料庫通過時間戳抽取增量資料到小時/分鐘增量分區表,将N個小時/分鐘增量分區表merge入每日增量分區表,再将今日增量分區表merge前一日全量分區表,寫入今日全量分區表。
更多内容詳見阿裡巴巴資料中台官網
https://dp.alibaba.com阿裡巴巴資料中台團隊,緻力于輸出阿裡雲資料智能的最佳實踐,助力每個企業建設自己的資料中台,進而共同實作新時代下的智能商業!
阿裡巴巴資料中台解決方案,核心産品:
Dataphin,以阿裡巴巴大資料核心方法論OneData為核心驅動,提供一站式資料建構與管理能力;
Quick BI,集阿裡巴巴資料分析經驗沉澱,提供一站式資料分析與展現能力;
Quick Audience,集阿裡巴巴消費者洞察及營銷經驗,提供一站式人群圈選、洞察及營銷投放能力,連接配接阿裡巴巴商業,實作使用者增長。
歡迎志同道合者一起成長!更多内容詳見