Stream是JDK 1.8中新增加的一個特性,就如同一個進階版疊代器(Iterator),可無限資料源,單向,不可往複,周遊過一次後即用盡了,正如流水一去不複返。而和疊代器隻能指令式地、串行化操作不同,Stream可以并行化操作;
而ParallelStream正是一個并行執行的流,它是通過預設的ForkJoinPool提高多線程任務處理速度;
1. 一個栗子
static List<String> construct() {
List<String> Strings = new ArrayList<String>();
for (int i = 0; i < 50; i++) {
String p = "name" + i;
Strings.add(p);
}
return Strings;
}
static void doFor(List<String> Strings) {
long start = System.currentTimeMillis();
for (String p : Strings) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
// System.out.println(p);
}
long end = System.currentTimeMillis();
System.out.println("doFor cost:" + (end - start));
}
static void doStream(List<String> Strings) {
long start = System.currentTimeMillis();
Strings.stream().forEach(x -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
// System.out.println(x);
});
long end = System.currentTimeMillis();
System.out.println("doStream cost:" + (end - start));
}
static void doParallelStream(List<String> Strings) {
long start = System.currentTimeMillis();
Strings.parallelStream().forEach(x -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
// System.out.println(x);
});
long end = System.currentTimeMillis();
System.out.println("doParallelStream cost:" + (end - start));
} 運作結果:
doFor cost:5119
doStream cost:5221
doParallelStream cost:724 從執行結果來看,stream順序輸出,而parallelStream無序輸出;parallelStream執行效率最快;
下面來刨析下背後的運作機制;
2. 認識 ForkJoin
ForkJoin是JDK 1.7中推出的一個新特性,它同ThreadPoolExecutor一樣實作了Executor和ExecutorService接口。核心線程的數量預設值采用目前可用的CPU數量,并使用了一個無限隊列來儲存需要執行的任務;
ForkJoinPool的核心算法主要是分治法(Divide-and-Conquer Algorithm),可以将一個任務分拆為多個子任務(所有子任務都完成之後才執行主任務),子任務執行完畢後,再把結果合并起來;能夠使用相對少的線程來處理大量的任務,并且這些任務之間是有父子依賴的,必須是子任務執行完成後,父任務才能執行;也可以讓其中的線程建立新的任務,并挂起目前的任務,任務以及子任務會保留在一個内部隊列中,此時線程就能夠從隊列中選擇任務順序執行。
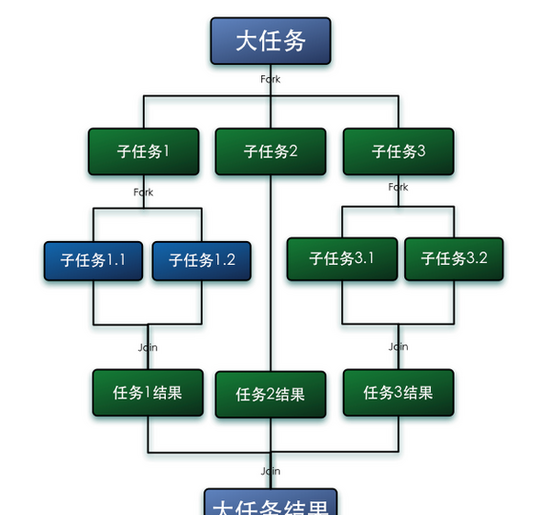
如在典型的快速排序算法應用中:需要對1000萬、個資料進行排序,那麼會将這個任務分割成兩個500萬的排序任務和一個對這兩組500萬資料的合并任務。以此類推,對于500萬的資料也會做出同樣的分割處理,到最後會設定一個門檻值來規定當資料規模到多少時,停止這樣的分割處理。比如,當元素的數量小于2時,會停止分割,轉而使用插入排序對它們進行排序。所有的任務加起來會有大概2000000+個;
而同樣的任務交由ThreadPoolExecutor則幾乎是不可能的任務,因為ThreadPoolExecutor中的線程無法向任務隊列中再添加一個任務并且在等待該任務完成之後再繼續執行,同時也無法選擇優先執行子任務,當需要完成200萬個具有父子關系的任務時,需要200萬個并行線程,顯然這是不可行的。而使用ForkJoinPool時,就能夠讓其中的線程建立新的任務,并挂起目前的任務,此時線程就能夠從隊列中選擇子任務執行;
3. 了解 Work Stealing / 工作竊取
工作竊取(work-stealing)算法是整個forkjion架構的核心理念,是指某個線程從其他隊列裡竊取任務來執行;充分的利用了現代CPU多核,提高新能;
那麼為什麼需要使用工作竊取算法呢?
假如我們需要做一個比較大的任務,我們可以把這個任務分割為若幹互不依賴的子任務,為了減少線程間的競争,于是把這些子任務分别放到不同的隊列裡,并為每個隊列建立一個單獨的線程來執行隊列裡的任務,線程和隊列一一對應,比如A線程負責處理A隊列裡的任務。但是有的線程會先把自己隊列裡的任務幹完,而其他線程對應的隊列裡還有任務等待處理。幹完活的線程與其等着,不如去幫其他線程幹活,于是它就去其他線程的隊列裡竊取一個任務來執行。而在這時它們會通路同一個隊列,是以為了減少竊取任務線程和被竊取任務線程之間的競争,通常會使用雙端隊列,被竊取任務線程永遠從雙端隊列的頭部拿任務執行,而竊取任務的線程永遠從雙端隊列的尾部拿任務執行;
4. ParallelStream 運作機制
JDK 1.8中ForkJoinPool添加了一個預設線程數量為CPU核心數的通用線程池靜态類型,用來處理那些沒有被顯式送出到任何線程池的任務。如在上例子中,對于清單中的元素的操作都會以并行的方式執行。forEach方法會為每個元素的計算操作建立一個任務,該任務會被通用線程池處理;代碼的可讀性和代碼量較ThreadPoolExecutor明顯更勝一籌;
ForkJoinPool的線程數量可以通過設定系統屬性:
-Djava.util.concurrent.ForkJoinPool.common.parallelism=N (N為線程數量)
另外需要注意是調用forEach方法時它會将執行forEach本身的線程也作為線程池中的一個工作線程。是以,即使将ForkJoinPool的通用線程池的線程數量設定為1,實際上也會有2個工作線程。是以在使用forEach的時候,線程數為1的ForkJoinPool通用線程池和線程數為2的ThreadPoolExecutor是等價的;是以當ForkJoinPool通用線程池實際需要4個工作線程時,可以将它設定成3,那麼在運作時可用的工作線程就是4了;
5. 線程安全考慮
再看一個例子:
static void doThreadUnSafe() {
List<Integer> listFor = new ArrayList<>(1000);
List<Integer> listParallel = new ArrayList<>(1000);
IntStream.range(0, 1000).forEach(listFor::add);
IntStream.range(0, 1000).parallel().forEach(listParallel::add);
System.out.println("listFor size :" + listFor.size());
System.out.println("listParallel size :" + listParallel.size());
} listFor size :1000
listParallel size :917 顯而易見,stream.parallel.forEach()中執行的操作并非線程安全。如果需要線程安全,可以把集合轉換為同步集合,即:Collections.synchronizedList(new ArrayList<>())。
6. 正确使用 ParallelStream
當我們對parallelStream有了足夠的了解之後,再來考慮是否需要使用ParallelStream:
- 使用ParallelStream可以簡潔高效的寫出并發代碼;
- ParallelStream并行執行是無序的,是以對于依賴于順序的任務而言,并行化也許不能給出正确的結果,在這種情況下需要慎重選擇;
- ParallelStream提供了更簡單的并發執行的實作,但并不意味着更高的性能;比如當資料量不大時,順序執行往往比并行執行更快。畢竟線程池準備,頻繁切換線程是耗時的。但是當任務涉及到I/O操作并且任務之間不互相依賴時,将這類程式并行化之後,執行速度将會明顯的提升;
- 任務之間最好是狀态無關的,因為ParallelStream預設是非線程安全的,可能帶來結果的不确定性。
![Java String.format方法的簡單使用[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)