作者:關文選,花名雲魄,阿裡雲E-MapReduce 進階開發工程師,專注于流式計算,Spark Contributor
1.背景介紹
PV/UV統計是流式分析一個常見的場景。通過PV可以對通路的網站做流量或熱點分析,例如廣告主可以通過PV值預估投放廣告網頁所帶來的流量以及廣告收入。另外一些場景需要對通路的使用者作分析,比如分析使用者的網頁點選行為,此時就需要對UV做統計。
使用Spark Streaming SQL,并結合Redis可以很友善進行PV/UV的統計。本文将介紹通過Streaming SQL消費Loghub中存儲的使用者通路資訊,對過去1分鐘内的資料進行PV/UV統計,将結果存入Redis中。
2.準備工作
- 建立E-MapReduce 3.23.0以上版本的Hadoop叢集。
- 下載下傳并編譯E-MapReduce-SDK包
git clone [email protected]:aliyun/aliyun-emapreduce-sdk.git
cd aliyun-emapreduce-sdk
git checkout -b master-2.x origin/master-2.x
mvn clean package -DskipTests 編譯完後, assembly/target目錄下會生成emr-datasources_shaded_${version}.jar,其中${version}為sdk的版本。
- 資料源
本文采用Loghub作為資料源,有關日志采集、日志解析請參考
日志服務。
3.統計PV/UV
一般場景下需要将統計出的PV/UV以及相應的統計時間存入Redis。其他一些業務場景中,也會隻儲存最新結果,用新的結果不斷覆寫更新舊的資料。以下首先介紹第一種情況的操作流程。
3.1啟動用戶端
指令行啟動streaming-sql用戶端
streaming-sql --master yarn-client --num-executors 2 --executor-memory 2g --executor-cores 2 --jars emr-datasources_shaded_2.11-${version}.jar --driver-class-path emr-datasources_shaded_2.11-${version}.jar 也可以建立SQL語句檔案,通過
streaming-sql -f
的方式運作。
3.1定義資料表
資料源表定義如下
CREATE TABLE loghub_source(user_ip STRING, __time__ TIMESTAMP)
USING loghub
OPTIONS(
sls.project=${sls.project},
sls.store=${sls.store},
access.key.id=${access.key.id},
access.key.secret=${access.key.secret},
endpoint=${endpoint}); 其中,資料源表包含user_ip和__time__兩個字段,分别代表使用者的IP位址和loghub上的時間列。OPTIONS中配置項的值根據實際配置。
結果表定義如下
CREATE TABLE redis_sink
USING redis
OPTIONS(
table='statistic_info',
host=${redis_host},
key.column='user_ip'); 其中,user_ip對應資料中的使用者IP字段,配置項${redis_host}的值根據實際配置。
3.2建立流作業
CREATE SCAN loghub_scan
ON loghub_source
USING STREAM
OPTIONS(
watermark.column='__time__',
watermark.delayThreshold='10 second'); CREATE STREAM job
OPTIONS(
checkpointLocation=${checkpoint_location})
INSERT INTO redis_sink
SELECT COUNT(user_ip) AS pv, approx_count_distinct( user_ip) AS uv, window.end AS interval
FROM loghub_scan
GROUP BY TUMBLING(__time__, interval 1 minute), window; 4.3檢視統計結果
最終的統計結果如下圖所示
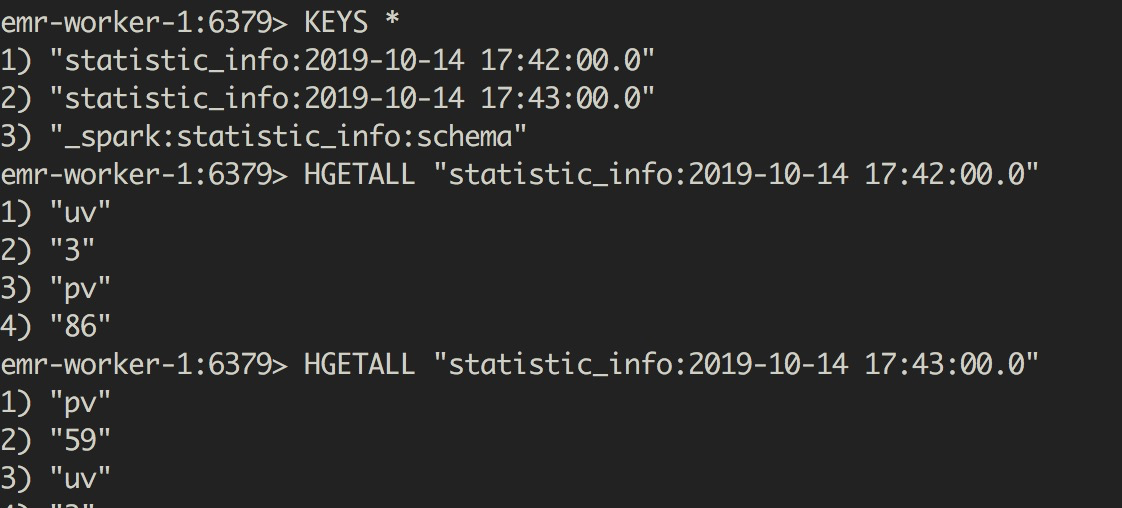
可以看到,每隔一分鐘都會生成一條資料,key的形式為表名:interval,value為pv和uv的值。
3.4實作覆寫更新
将結果表的配置項
key.column
修改為一個固定的值,例如定義如下
CREATE TABLE redis_sink
USING redis
OPTIONS(
table='statistic_info',
host=${redis_host},
key.column='statistic_type'); 建立流作業的SQL改為
CREATE STREAM job
OPTIONS(
checkpointLocation='/tmp/spark-test/checkpoint')
INSERT INTO redis_sink
SELECT "PV_UV" as statistic_type,COUNT(user_ip) AS pv, approx_count_distinct( user_ip) AS uv, window.end AS interval
FROM loghub_scan
GROUP BY TUMBLING(__time__, interval 1 minute), window; 
可以看到,Redis中值保留了一個值,這個值每分鐘都被更新,value包含pv、uv和interval的值。
4.總結
本文簡要介紹了使用Streaming SQL結合Redis實作流式進行中統計PV/UV的需求。後續文章,我将介紹Spark Streaming SQL的更多内容
阿裡巴巴開源大資料技術團隊成立Apache Spark中國技術社群,定期推送精彩案例,技術專家直播,問答區數個Spark技術同學每日線上答疑,隻為營造純粹的Spark氛圍,歡迎釘釘掃碼加入!