- 作者:周凱波(寶牛)
- 整理:毛鶴
本文主要介紹 Flink on Yarn/K8s 的原理及應用實踐,文章将從 Flink 架構、Flink on Yarn 原理及實踐、Flink on Kubernetes 原理剖析三部分内容進行分享并對 Flink on Yarn/Kubernetes 中存在的部分問題進行了解答。
Flink 架構概覽
Flink 架構概覽–Job
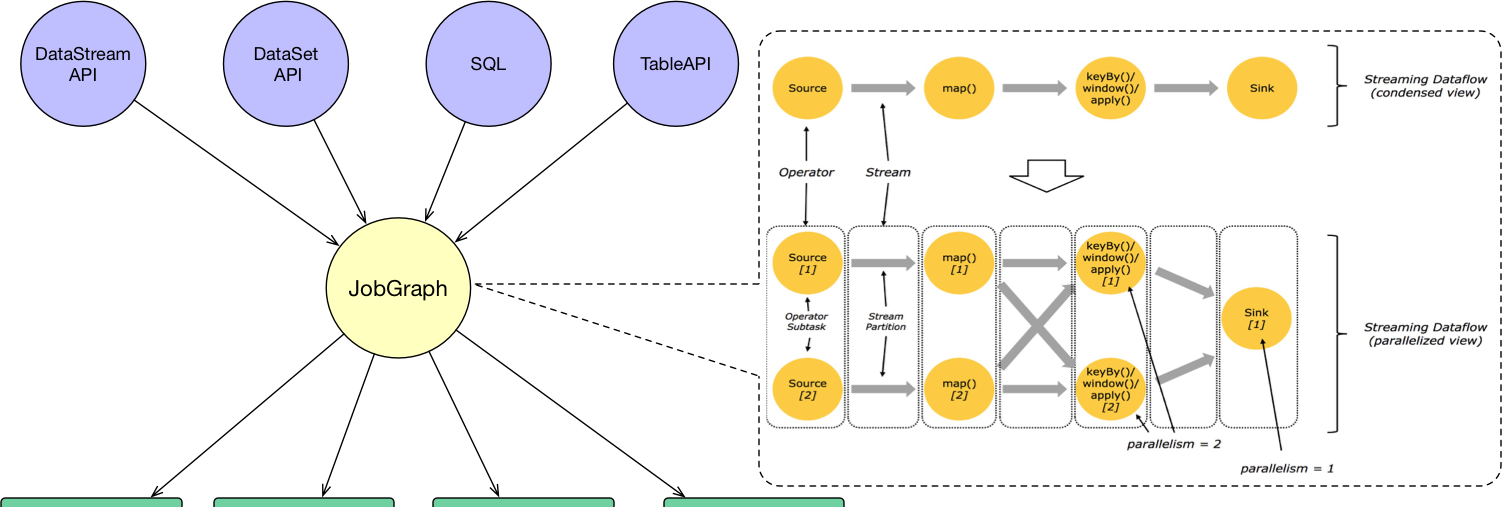
使用者通過 DataStream API、DataSet API、SQL 和 Table API 編寫 Flink 任務,它會生成一個JobGraph。JobGraph 是由 source、map()、keyBy()/window()/apply() 和 Sink 等算子組成的。當 JobGraph 送出給 Flink 叢集後,能夠以 Local、Standalone、Yarn 和 Kubernetes 四種模式運作。
Flink 架構概覽–JobManager

JobManager的功能主要有:
- 将 JobGraph 轉換成 Execution Graph,最終将 Execution Graph 拿來運作
- Scheduler 元件負責 Task 的排程
- Checkpoint Coordinator 元件負責協調整個任務的 Checkpoint,包括 Checkpoint 的開始和完成
- 通過 Actor System 與 TaskManager 進行通信
- 其它的一些功能,例如 Recovery Metadata,用于進行故障恢複時,可以從 Metadata 裡面讀取資料。
Flink 架構概覽–TaskManager
TaskManager 是負責具體任務的執行過程,在 JobManager 申請到資源之後開始啟動。TaskManager 裡面的主要元件有:
- Memory & I/O Manager,即記憶體 I/O 的管理
- Network Manager,用來對網絡方面進行管理
- Actor system,用來負責網絡的通信
TaskManager 被分成很多個 TaskSlot,每個任務都要運作在一個 TaskSlot 裡面,TaskSlot 是排程資源裡的最小機關。
在介紹 Yarn 之前先簡單的介紹一下 Flink Standalone 模式,這樣有助于更好地了解 Yarn 和 Kubernetes 架構。
- 在 Standalone 模式下,Master 和 TaskManager 可以運作在同一台機器上,也可以運作在不同的機器上。
- 在 Master 程序中,Standalone ResourceManager 的作用是對資源進行管理。當使用者通過 Flink Cluster Client 将 JobGraph 送出給 Master 時,JobGraph 先經過 Dispatcher。
- 當 Dispatcher 收到用戶端的請求之後,生成一個 JobManager。接着 JobManager 程序向 Standalone ResourceManager 申請資源,最終再啟動 TaskManager。
- TaskManager 啟動之後,會有一個注冊的過程,注冊之後 JobManager 再将具體的 Task 任務分發給這個 TaskManager 去執行。
以上就是一個 Standalone 任務的運作過程。
Flink 運作時相關元件
接下來總結一下 Flink 的基本架構和它在運作時的一些元件,具體如下:
- Client:使用者通過 SQL 或者 API 的方式進行任務的送出,送出後會生成一個 JobGraph。
- JobManager:JobManager 接受到使用者的請求之後,會對任務進行排程,并且申請資源啟動 TaskManager。
- TaskManager:它負責一個具體 Task 的執行。TaskManager 向 JobManager 進行注冊,當 TaskManager 接收到 JobManager 配置設定的任務之後,開始執行具體的任務。
Flink on Yarn 原理及實踐
Yarn 架構原理–總覽
Yarn 模式在國内使用比較廣泛,基本上大多數公司在生産環境中都使用過 Yarn 模式。首先介紹一下 Yarn 的架構原理,因為隻有足夠了解 Yarn 的架構原理,才能更好的知道 Flink 是如何在 Yarn 上運作的。
Yarn 的架構原理如上圖所示,最重要的角色是 ResourceManager,主要用來負責整個資源的管理,Client 端是負責向 ResourceManager 送出任務。
使用者在 Client 端送出任務後會先給到 Resource Manager。Resource Manager 會啟動 Container,接着進一步啟動 Application Master,即對 Master 節點的啟動。當 Master 節點啟動之後,會向 Resource Manager 再重新申請資源,當 Resource Manager 将資源配置設定給 Application Master 之後,Application Master 再将具體的 Task 排程起來去執行。
Yarn 架構原理–元件
Yarn 叢集中的元件包括:
- ResourceManager (RM):ResourceManager (RM)負責處理用戶端請求、啟動/監控 ApplicationMaster、監控 NodeManager、資源的配置設定與排程,包含 Scheduler 和 Applications Manager。
- ApplicationMaster (AM):ApplicationMaster (AM)運作在 Slave 上,負責資料切分、申請資源和配置設定、任務監控和容錯。
- NodeManager (NM):NodeManager (NM)運作在 Slave 上,用于單節點資源管理、AM/RM通信以及彙報狀态。
- Container:Container 負責對資源進行抽象,包括記憶體、CPU、磁盤,網絡等資源。
Yarn 架構原理–互動
以在 Yarn 上運作 MapReduce 任務為例來講解下 Yarn 架構的互動原理:
- 首先,使用者編寫 MapReduce 代碼後,通過 Client 端進行任務送出
- ResourceManager 在接收到用戶端的請求後,會配置設定一個 Container 用來啟動 ApplicationMaster,并通知 NodeManager 在這個 Container 下啟動 ApplicationMaster。
- ApplicationMaster 啟動後,向 ResourceManager 發起注冊請求。接着 ApplicationMaster 向 ResourceManager 申請資源。根據擷取到的資源,和相關的 NodeManager 通信,要求其啟動程式。
- 一個或者多個 NodeManager 啟動 Map/Reduce Task。
- NodeManager 不斷彙報 Map/Reduce Task 狀态和進展給 ApplicationMaster。
- 當所有 Map/Reduce Task 都完成時,ApplicationMaster 向 ResourceManager 彙報任務完成,并登出自己。
Flink on Yarn–Per Job
Flink on Yarn 中的 Per Job 模式是指每次送出一個任務,然後任務運作完成之後資源就會被釋放。在了解了 Yarn 的原理之後,Per Job 的流程也就比較容易了解了,具體如下:
- 首先 Client 送出 Yarn App,比如 JobGraph 或者 JARs。
- 接下來 Yarn 的 ResourceManager 會申請第一個 Container。這個 Container 通過 Application Master 啟動程序,Application Master 裡面運作的是 Flink 程式,即 Flink-Yarn ResourceManager 和 JobManager。
- 最後 Flink-Yarn ResourceManager 向 Yarn ResourceManager 申請資源。當配置設定到資源後,啟動 TaskManager。TaskManager 啟動後向 Flink-Yarn ResourceManager 進行注冊,注冊成功後 JobManager 就會配置設定具體的任務給 TaskManager 開始執行。
Flink on Yarn–Session
在 Per Job 模式中,執行完任務後整個資源就會釋放,包括 JobManager、TaskManager 都全部退出。而 Session 模式則不一樣,它的 Dispatcher 和 ResourceManager 是可以複用的。Session 模式下,當 Dispatcher 在收到請求之後,會啟動 JobManager(A),讓 JobManager(A) 來完成啟動 TaskManager,接着會啟動 JobManager(B) 和對應的 TaskManager 的運作。當 A、B 任務運作完成後,資源并不會釋放。Session 模式也稱為多線程模式,其特點是資源會一直存在不會釋放,多個 JobManager 共享一個 Dispatcher,而且還共享 Flink-YARN ResourceManager。
Session 模式和 Per Job 模式的應用場景不一樣。Per Job 模式比較适合那種對啟動時間不敏感,運作時間較長的任務。Seesion 模式适合短時間運作的任務,一般是批處理任務。若用 Per Job 模式去運作短時間的任務,那就需要頻繁的申請資源,運作結束後,還需要資源釋放,下次還需再重新申請資源才能運作。顯然,這種任務會頻繁啟停的情況不适用于 Per Job 模式,更适合用 Session 模式。
Yarn模式特點
Yarn 模式的優點有:
- 資源的統一管理和排程。Yarn 叢集中所有節點的資源(記憶體、CPU、磁盤、網絡等)被抽象為 Container。計算架構需要資源進行運算任務時需要向 Resource Manager 申請 Container,YARN 按照特定的政策對資源進行排程和進行 Container 的配置設定。Yarn 模式能通過多種任務排程政策來利用提高叢集資源使用率。例如 FIFO Scheduler、Capacity Scheduler、Fair Scheduler,并能設定任務優先級。
- 資源隔離:Yarn 使用了輕量級資源隔離機制 Cgroups 進行資源隔離以避免互相幹擾,一旦 Container 使用的資源量超過事先定義的上限值,就将其殺死。
- 自動 failover 處理。例如 Yarn NodeManager 監控、Yarn ApplicationManager 異常恢複。
Yarn 模式雖然有不少優點,但是也有諸多缺點,例如運維部署成本較高,靈活性不夠。
Flink on Yarn 實踐
關于 Flink on Yarn 的實踐在
https://ververica.cn/developers/flink-training-course1/上面有很多課程,例如:《Flink 安裝部署、環境配置及運作應用程式》 和 《用戶端操作》都是基于 Yarn 進行講解的,這裡就不再贅述。
Flink on Kubernetes 原理剖析
Kubernetes 是 Google 開源的容器叢集管理系統,其提供應用部署、維護、擴充機制等功能,利用 Kubernetes 能友善地管理跨機器運作容器化的應用。Kubernetes 和 Yarn 相比,相當于下一代的資源管理系統,但是它的能力遠遠不止這些。
Kubernetes–基本概念
Kubernetes(k8s)中的 Master 節點,負責管理整個叢集,含有一個叢集的資源資料通路入口,還包含一個 Etcd 高可用鍵值存儲服務。Master 中運作着 API Server,Controller Manager 及 Scheduler 服務。
Node 為叢集的一個操作單元,是 Pod 運作的主控端。Node 節點裡包含一個 agent 程序,能夠維護和管理該 Node 上的所有容器的建立、啟停等。Node 還含有一個服務端 kube-proxy,用于服務發現、反向代理和負載均衡。Node 底層含有 docker engine,docker 引擎主要負責本機容器的建立和管理工作。
Pod 運作于 Node 節點上,是若幹相關容器的組合。在 K8s 裡面 Pod 是建立、排程和管理的最小機關。
Kubernetes–架構圖
Kubernetes 的架構如圖所示,從這個圖裡面能看出 Kubernetes 的整個運作過程。
- API Server 相當于使用者的一個請求入口,使用者可以送出指令給 Etcd,這時會将這些請求存儲到 Etcd 裡面去。
- Etcd 是一個鍵值存儲,負責将任務配置設定給具體的機器,在每個節點上的 Kubelet 會找到對應的 container 在本機上運作。
- 使用者可以送出一個 Replication Controller 資源描述,Replication Controller 會監視叢集中的容器并保持數量;使用者也可以送出 service 描述檔案,并由 kube proxy 負責具體工作的流量轉發。
Kubernetes–核心概念
Kubernetes 中比較重要的概念有:
- Replication Controller (RC) 用來管理 Pod 的副本。RC 確定任何時候 Kubernetes 叢集中有指定數量的 pod 副本(replicas) 在運作, 如果少于指定數量的 pod 副本,RC 會啟動新的 Container,反之會殺死多餘的以保證數量不變。
- Service 提供了一個統一的服務通路入口以及服務代理和發現機制
- Persistent Volume(PV) 和 Persistent Volume Claim(PVC) 用于資料的持久化存儲。
- ConfigMap 是指存儲使用者程式的配置檔案,其後端存儲是基于 Etcd。
Flink on Kubernetes–架構
Flink on Kubernetes 的架構如圖所示,Flink 任務在 Kubernetes 上運作的步驟有:
- 首先往 Kubernetes 叢集送出了資源描述檔案後,會啟動 Master 和 Worker 的 container。
- Master Container 中會啟動 Flink Master Process,包含 Flink-Container ResourceManager、JobManager 和 Program Runner。
- Worker Container 會啟動 TaskManager,并向負責資源管理的 ResourceManager 進行注冊,注冊完成之後,由 JobManager 将具體的任務分給 Container,再由 Container 去執行。
- 需要說明的是,在 Flink 裡的 Master 和 Worker 都是一個鏡像,隻是腳本的指令不一樣,通過參數來選擇啟動 master 還是啟動 Worker。
Flink on Kubernetes–JobManager
JobManager 的執行過程分為兩步:
- 首先,JobManager 通過 Deployment 進行描述,保證 1 個副本的 Container 運作 JobManager,可以定義一個标簽,例如 flink-jobmanager。
- 其次,還需要定義一個 JobManager Service,通過 service name 和 port 暴露 JobManager 服務,通過标簽選擇對應的 pods。
Flink on Kubernetes–TaskManager
TaskManager 也是通過 Deployment 來進行描述,保證 n 個副本的 Container 運作 TaskManager,同時也需要定義一個标簽,例如 flink-taskmanager。
對于 JobManager 和 TaskManager 運作過程中需要的一些配置檔案,如:flink-conf.yaml、hdfs-site.xml、core-site.xml,可以通過将它們定義為 ConfigMap 來實作配置的傳遞和讀取。
Flink on Kubernetes–互動
整個互動的流程比較簡單,使用者往 Kubernetes 叢集送出定義好的資源描述檔案即可,例如 deployment、configmap、service 等描述。後續的事情就交給 Kubernetes 叢集自動完成。Kubernetes 叢集會按照定義好的描述來啟動 pod,運作使用者程式。各個元件的具體工作如下:
- Service: 通過标簽(label selector)找到 job manager 的 pod 暴露服務。
- Deployment:保證 n 個副本的 container 運作 JM/TM,應用更新政策。
- ConfigMap:在每個 pod 上通過挂載 /etc/flink 目錄,包含 flink-conf.yaml 内容。
Flink on Kubernetes–實踐
接下來就講一下 Flink on Kubernetes 的實踐篇,即 K8s 上是怎麼運作任務的。
Session Cluster
•Session Cluster
•啟動
•kubectl create -f jobmanager-service.yaml
•kubectl create -f jobmanager-deployment.yaml
•kubectl create -f taskmanager-deployment.yaml
•Submit job
•kubectl port-forward service/flink-jobmanager 8081:8081
•bin/flink run -d -m localhost:8081 ./examples/streaming/TopSpeedWindowing.jar
•停止
•kubectl delete -f jobmanager-deployment.yaml
•kubectl delete -f taskmanager-deployment.yaml
•kubectl delete -f jobmanager-service.yaml 首先啟動 Session Cluster,執行上述三條啟動指令就可以将 Flink 的 JobManager-service、jobmanager-deployment、taskmanager-deployment 啟動起來。啟動完成之後使用者可以通過接口進行通路,然後通過端口進行送出任務。若想銷毀叢集,直接用 kubectl delete 即可,整個資源就可以銷毀。
Flink 官方提供的例子如圖所示,圖中左側為 jobmanager-deployment.yaml 配置,右側為 taskmanager-deployment.yaml 配置。
在 jobmanager-deployment.yaml 配置中,代碼的第一行為 apiVersion,apiVersion 是API 的一個版本号,版本号用的是 extensions/vlbetal 版本。資源類型為 Deployment,中繼資料 metadata 的名為 flink-jobmanager,spec 中含有副本數為 1 的 replicas,labels 标簽用于 pod 的選取。containers 的鏡像名為 jobmanager,containers 包含從公共 docker 倉庫下載下傳的 image,當然也可以使用公司内部的私有倉庫。args 啟動參數用于決定啟動的是 jobmanager 還是 taskmanager;ports 是服務端口,常見的服務端口為 8081 端口;env 是定義的環境變量,會傳遞給具體的啟動腳本。
右圖為 taskmanager-deployment.yaml 配置,taskmanager-deployment.yaml 配置與 jobmanager-deployment.yaml 相似,但 taskmanager-deployment.yaml 的副本數是 2 個。
接下來是 jobmanager-service.yaml 的配置,jobmanager-service.yaml 的資源類型為 Service,在 Service 中的配置相對少一些,spec 中配置需要暴露的服務端口的 port,在 selector 中,通過标簽選取 jobmanager 的 pod。
Job Cluster
除了 Session 模式,還有一種 Per Job 模式。在 Per Job 模式下,需要将使用者代碼都打到鏡像裡面,這樣如果業務邏輯的變動涉及到 Jar 包的修改,都需要重新生成鏡像,整個過程比較繁瑣,是以在生産環境中使用的比較少。
以使用公用 docker 倉庫為例,Job Cluster 的運作步驟如下:
- build 鏡像:在 flink/flink-container/docker 目錄下執行 build.sh 腳本,指定從哪個版本開始去建構鏡像,成功後會輸出 “Successfully tagged topspeed:latest” 的提示。
sh build.sh --from-release --flink-version 1.7.0 --hadoop-version 2.8 --scala-version 2.11 --job-jar ~/flink/flink-1.7.1/examples/streaming/TopSpeedWindowing.jar --image-name topspeed - 上傳鏡像:在 hub.docker.com 上需要新增賬號和建立倉庫進行上傳鏡像。
docker tag topspeed zkb555/topspeedwindowing
docker push zkb555/topspeedwindowing - 啟動任務:在鏡像上傳之後,可以啟動任務。
kubectl create -f job-cluster-service.yaml
FLINK_IMAGE_NAME=zkb555/topspeedwindowing:latest FLINK_JOB=org.apache.flink.streaming.examples.windowing.TopSpeedWindowing FLINK_JOB_PARALLELISM=3 envsubst < job-cluster-job.yaml.template | kubectl create -f –
FLINK_IMAGE_NAME=zkb555/topspeedwindowing:latest FLINK_JOB_PARALLELISM=4 envsubst < task-manager-deployment.yaml.template | kubectl create -f - Flink on Yarn/Kubernetes問題解答
Q: Flink 在 K8s 上可以通過 Operator 方式送出任務嗎?
目前 Flink 官方還沒有提供 Operator 的方式,Lyft 公司開源了自己的 Operator 實作:
https://github.com/lyft/flinkk8soperator。
Q: 在 K8s 叢集上如果不使用 Zookeeper 有沒有其他高可用(HA)的方案?
Etcd 是一個類似于 Zookeeper 的高可用鍵值服務,目前 Flink 社群正在考慮基于 Etcd 實作高可用的方案(
https://issues.apache.org/jira/browse/FLINK-11105)以及直接依賴 K8s API 的方案(
https://issues.apache.org/jira/browse/FLINK-12884)。
Q: Flink on K8s 在任務啟動時需要指定 TaskManager 的個數,有和 Yarn 一樣的動态資源申請方式嗎?
Flink on K8s 目前的實作在任務啟動前就需要确定好 TaskManager 的個數,這樣容易造成 TM 指定太少,任務無法啟動,或者指定的太多,造成資源浪費。社群正在考慮實作和 Yarn 一樣的任務啟動時動态資源申請的方式。這是一種和 K8s 結合的更為 Nativey 的方式,稱為 Active 模式。Active 意味着 ResourceManager 可以直接向 K8s 叢集申請資源。具體設計方案和進展請關注:
https://issues.apache.org/jira/browse/FLINK-9953 視訊回顧▼ Apache Flink 社群推薦 ▼
Apache Flink 及大資料領域頂級盛會 Flink Forward Asia 2019 大會議程重磅釋出,參與
問卷調研就有機會免費擷取門票!
https://developer.aliyun.com/special/ffa2019