袋鼠雲雲原生一站式資料中台PaaS——數棧,覆寫了建設資料中心過程中所需要的各種工具(包括資料開發平台、資料資産平台、資料科學平台、資料服務引擎等),完整覆寫離線計算、實時計算應用,幫助企業極大地縮短資料價值的萃取過程,提高提煉資料價值的能力。
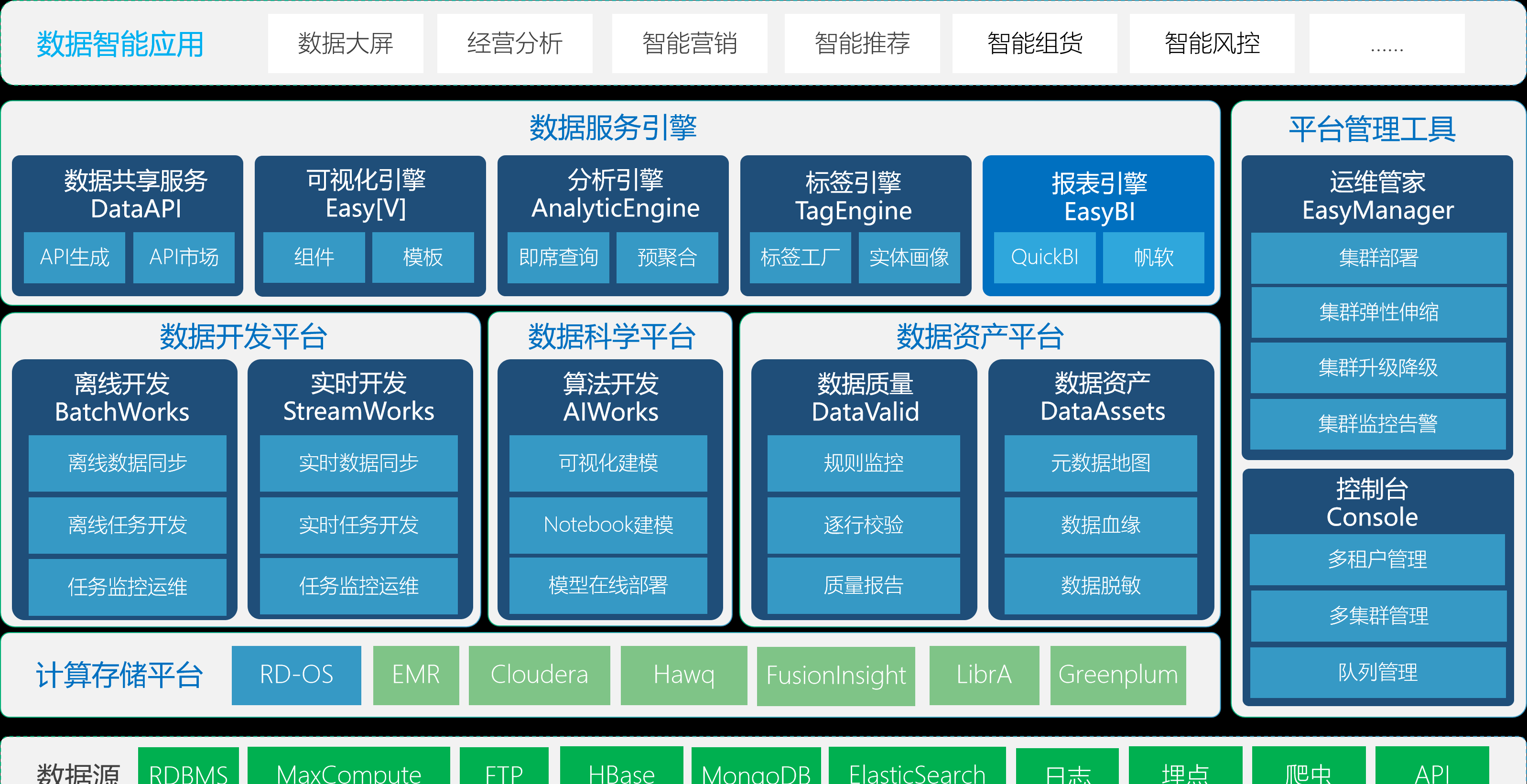
數棧架構圖
目前,數棧-離線開發平台(BatchWorks) 中的資料離線同步任務、數棧-實時開發平台(StreamWorks)中的資料實時采集任務已經統一基于FlinkX來實作。資料的離線采集和實時采集基本的原理的是一樣的,主要的不同之處是源頭的流是否有界,是以統一用Flink的Stream API 來實作這兩種資料同步場景,實作資料同步的批流統一。
1、功能介紹
斷點續傳
斷點續傳是指資料同步任務在運作過程中因各種原因導緻任務失敗,不需要重頭同步資料,隻需要從上次失敗的位置繼續同步即可,類似于下載下傳檔案時因網絡原因失敗,不需要重新下載下傳檔案,隻需要繼續下載下傳就行,可以大大節省時間和計算資源。斷點續傳是數棧-離線開發平台(BatchWorks)裡資料同步任務的一個功能,需要結合任務的出錯重試機制才能完成。當任務運作失敗,會在Engine裡進行重試,重試的時候會接着上次失敗時讀取的位置繼續讀取資料,直到任務運作成功為止。
實時采集
實時采集是數棧-實時開發平台(StreamWorks)裡資料采集任務的一個功能,當資料源裡的資料發生了增删改操作,同步任務監聽到這些變化,将變化的資料實時同步到目标資料源。除了資料實時變化外,實時采集和離線資料同步的另一個差別是:實時采集任務是不會停止的,任務會一直監聽資料源是否有變化。這一點和Flink任務是一緻的,是以實時采集任務是數棧流計算應用裡的一個任務類型,配置過程和離線計算裡的同步任務基本一樣。
2、Flink中的Checkpoint機制
斷點續傳和實時采集都依賴于Flink的Checkpoint機制,是以咱們先來簡單了解一下。Checkpoint是Flink實作容錯機制最核心的功能,它能夠根據配置周期性地基于Stream中各個Operator的狀态來生成Snapshot,進而将這些狀态資料定期持久化存儲下來,當Flink程式一旦意外崩潰時,重新運作程式時可以有選擇地從這些Snapshot進行恢複,進而修正因為故障帶來的程式資料狀态中斷。

Checkpoint觸發時,會向多個分布式的Stream Source中插入一個Barrier标記,這些Barrier會随着Stream中的資料記錄一起流向下遊的各個Operator。當一個Operator接收到一個Barrier時,它會暫停處理Steam中新接收到的資料記錄。因為一個Operator可能存在多個輸入的Stream,而每個Stream中都會存在對應的Barrier,該Operator要等到所有的輸入Stream中的Barrier都到達。
當所有Stream中的Barrier都已經到達該Operator,這時所有的Barrier在時間上看來是同一個時刻點(表示已經對齊),在等待所有Barrier到達的過程中,Operator的Buffer中可能已經緩存了一些比Barrier早到達Operator的資料記錄(Outgoing Records),這時該Operator會将資料記錄(Outgoing Records)發射(Emit)出去,作為下遊Operator的輸入,最後将Barrier對應Snapshot發射(Emit)出去作為此次Checkpoint的結果資料。
3、斷點續傳
前提條件
同步任務要支援斷點續傳,對資料源有一些強制性的要求:
1、 資料源(這裡特指關系資料庫)中必須包含一個升序的字段,比如主鍵或者日期類型的字段,同步過程中會使用checkpoint機制記錄這個字段的值,任務恢複運作時使用這個字段構造查詢條件過濾已經同步過的資料,如果這個字段的值不是升序的,那麼任務恢複時過濾的資料就是錯誤的,最終導緻資料的缺失或重複;
2、資料源必須支援資料過濾,如果不支援的話,任務就無法從斷點處恢複運作,會導緻資料重複;
3、目标資料源必須支援事務,比如關系資料庫,檔案類型的資料源也可以通過臨時檔案的方式支援;
任務運作的詳細過程
我們用一個具體的任務詳細介紹一下整個過程,任務詳情如下:
資料源:mysql表,假設表名data_test,表中包含主鍵字段id
目标資料源 :hdfs檔案系統,假設寫入路徑為 /data_test
并發數: 2
checkpoint配置: 時間間隔為60s,checkpoint的StateBackend為FsStateBackend,路徑為 /flinkx/checkpoint
jobId:用來構造資料檔案的名稱,假設為 abc123
1) 讀取資料
讀取資料時首先要構造資料分片,構造資料分片就是根據通道索引和checkpoint記錄的位置構造查詢sql,sql模闆如下:
select*fromdata_test
whereidmod${channel_num}=${channel_index}
andid> ${offset}
如果是第一次運作,或者上一次任務失敗時還沒有觸發checkpoint,那麼offset就不存在,根據offset和通道可以确定具體的查詢sql:offset存在時第一個通道:
whereidmod2=0
andid> ${offset_0};
第二個通道
select*fromdata_testwhereidmod2=1andid> ${offset_1};
offset不存在時第一個通道:
whereidmod2=0;
whereidmod2=1;
資料分片構造好之後,每個通道就根據自己的資料分片去讀資料了。
2)寫資料
寫資料前會先做幾個操作:
檢測 /data_test 目錄是否存在,如果目錄不存在,則建立這個目錄,如果目錄存在,進行2操作;
判斷是不是以覆寫模式寫資料,如果是,則删除 /data_test目錄,然後再建立目錄,如果不是,則進行3操作;
檢測 /data_test/.data 目錄是否存在,如果存在就先删除,再建立,確定沒有其它任務因異常失敗遺留的髒資料檔案;
資料寫入hdfs是單條寫入的,不支援批量寫入。資料會先寫入/data_test/.data/目錄下,資料檔案的命名格式為:channelIndex.jobId.fileIndex
包含通道索引,jobId,檔案索引三個部分。
3)checkpoint觸發時
在FlinkX中“狀态”表示的是辨別字段id的值,我們假設checkpoint觸發時兩個通道的讀取和寫入情況如圖中所示:
checkpoint觸發後,兩個reader先生成Snapshot記錄讀取狀态,通道0的狀态為 id=12,通道1的狀态為 id=11。Snapshot生成之後向資料流裡面插入barrier,barrier随資料流向Writer。以Writer_0為例,Writer_0接收Reader_0和Reader_1發來的資料,假設先收到了Reader_0的barrier,這個時候Writer_0停止寫出資料到HDFS,将接收到的資料先放到 InputBuffer裡面,一直等待Reader_1的barrier到達之後再将Buffer裡的資料全部寫出,然後生成Writer的Snapshot,整個checkpoint結束後,記錄的任務狀态為:
Reader_0:id=12Reader_1:id=11Writer_0:id=無法确定Writer_1:id=無法确定
任務狀态會記錄到配置的HDFS目錄/flinkx/checkpoint/abc123下。因為每個Writer會接收兩個Reader的資料,以及各個通道的資料讀寫速率可能不一樣,是以導緻writer接收到的資料順序是不确定的,但是這不影響資料的準确性,因為讀取資料時隻需要Reader記錄的狀态就可以構造查詢sql,我們隻要確定這些資料真的寫到HDFS就行了。在Writer生成Snapshot之前,會做一系列操作保證接收到的資料全部寫入HDFS:
a.close寫入HDFS檔案的資料流,這時候會在/data_test/.data目錄下生成兩個兩個檔案:/data_test/.data/0.abc123.0/data_test/.data/1.abc123.0
b.将生成的兩個資料檔案移動到/data_test目錄下;
c.更新檔案名稱模闆更新為:channelIndex.abc123.1;
快照生成後任務繼續讀寫資料,如果生成快照的過程中有任何異常,任務會直接失敗,這樣這次快照就不會生成,任務恢複時會從上一個成功的快照恢複。
4)任務正常結束
任務正常結束時也會做和生成快照時同樣的操作,close檔案流,移動臨時資料檔案等。
5)任務異常終止
任務如果異常結束,假設任務結束時最後一個checkpoint記錄的狀态為:Reader_0:id=12Reader_1:id=11
那麼任務恢複的時候就會把各個通道記錄的狀态指派給offset,再次讀取資料時構造的sql為:
第一個通道:
andid>12;
whereidmod2=1
andid>11;
這樣就可以從上一次失敗的位置繼續讀取資料了。
支援斷點續傳的插件
理論上隻要支援過濾資料的資料源,和支援事務的資料源都可以支援斷點續傳的功能,目前FlinkX支援的插件如下:
ReaderWriter
mysql等關系資料讀取插件HDFS、FTP、mysql等關系資料庫寫入插件
4、實時采集
目前FlinkX支援實時采集的插件有KafKa、binlog插件,binlog插件是專門針對mysql資料庫做實時采集的,如果要支援其它的資料源,隻需要把資料打到Kafka,然後再用FlinkX的Kafka插件消費資料即可,比如oracle,隻需要使用oracle的ogg将資料打到Kafka。這裡我們專門講解一下mysql的實時采集插件binlog。
binlog
binlog是Mysql sever層維護的一種二進制日志,與innodb引擎中的redo/undo log是完全不同的日志;其主要是用來記錄對mysql資料更新或潛在發生更新的SQL語句,并以"事務"的形式儲存在磁盤中。binlog的作用主要有:
複制:MySQL Replication在Master端開啟binlog,Master把它的二進制日志傳遞給slaves并回放來達到master-slave資料一緻的目的;
資料恢複:通過mysqlbinlog工具恢複資料;
增量備份;
MySQL 主備複制
有了記錄資料變化的binlog日志還不夠,我們還需要借助MySQL的主備複制功能:主備複制是指 一台伺服器充當主資料庫伺服器,另一台或多台伺服器充當從資料庫伺服器,主伺服器中的資料自動複制到從伺服器之中。
主備複制的過程:
MySQL master 将資料變更寫入二進制日志( binary log, 其中記錄叫做二進制日志事件binary log events,可以通過 show binlog events 進行檢視);
MySQL slave 将 master 的 binary log events 拷貝到它的中繼日志(relay log);
MySQL slave 重放 relay log 中事件,将資料變更反映它自己的資料;
寫入Hive
binlog插件可以監聽多張表的資料變更情況,解析出的資料中包含表名稱資訊,讀取到的資料可以全部寫入目标資料庫的一張表,也可以根據資料中包含的表名資訊寫入不同的表,目前隻有Hive插件支援這個功能。Hive插件目前隻有寫入插件,功能基于HDFS的寫入插件實作,也就是說從binlog讀取,寫入hive也支援失敗恢複的功能。
寫入Hive的過程:
從資料中解析出MySQL的表名,然後根據表名映射規則轉換成對應的Hive表名
檢查Hive表是否存在,如果不存在就建立Hive表;
查詢Hive表的相關資訊,構造HdfsOutputFormat;
調用HdfsOutputFormat将資料寫入HDFS;