文章首發于我的個人部落格,到個人部落格體驗更佳閱讀哦
https://www.itqiankun.com/article/1564901799 為什麼要設定B+樹的非葉子節點資料小于4kb呢,我們往下一探究竟
原因如下所示
因為資料庫裡面的索引就是使用的bmore樹,是以我們使用sql語句來講解bmore樹的産生:
比如有下面的兩個常用的需求:
根據某個值查找資料,比如select * from user where id=1234;
根據區間值來查找某些資料,比如select * from user where id > 1234 and id < 2345。 為了讓二叉查找樹支援按照區間來查找資料,我們可以對它進行這樣的改造:樹中的節點并不存儲資料本身,而是隻是作為索引。除此之外,我們把每個葉子節點串在一條連結清單上,連結清單中的資料是從小到大有序的。就像下面這樣:
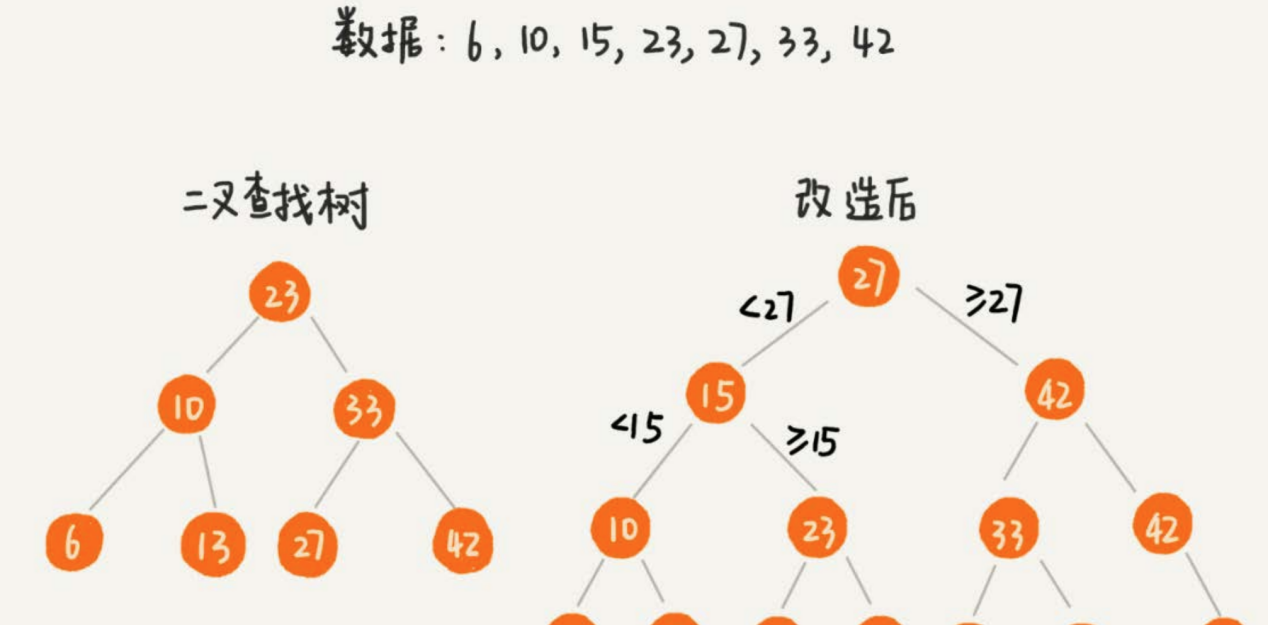
改造之後,如果我們要求某個區間的資料。我們隻需要拿區間的起始值,在樹中進行查找,當查找到某個葉子節點之後,我們再順着連結清單往後周遊,直到連結清單中的結點資料值大于區間的終止值為止。所有周遊到的資料,就是符合區間值的所有資料。

但是,我們要為幾千萬、上億的資料建構索引,如果将索引存儲在記憶體中,盡管記憶體通路的速度非常快,查詢的效率非常高,但是,占用的記憶體會非常多。
比如,我們給一億個資料建構二叉查找樹索引,那索引中會包含大約1億個節點,每個節點假設占用16個位元組,那就需要大約1GB的記憶體空間。給一張表建立索引,我們需要1GB的記憶體空間。如果我們要給10張表建立索引,那對記憶體的需求是無法滿足的。如何解決這個索引占用太多記憶體的問題呢?
我們可以借助時間換空間的思路,把索引存儲在硬碟中,而非記憶體中。我們都知道,硬碟是一個非常慢速的儲存設備。通常記憶體的通路速度是納秒級别的,而磁盤通路的速度是毫秒級别的。讀取同樣大小的資料,從磁盤中讀取花費的時間,是從記憶體中讀取所花費時間的上萬倍,甚至幾十萬倍。是以我們通過減少通路磁盤索引的次數來減少這個通路磁盤的查詢速度。怎麼減少呢,就是讓每個節點的讀取(或者通路),都對應一次磁盤IO操作,這樣樹的高度就等于每次查詢資料時磁盤IO操作的次數。
是以我們要把bmore樹建立成m叉樹,因為m值越大,樹的高度也就越低,如圖所示,給16個資料建構二叉樹索引,樹的高度是4,查找一個資料,就需要4個磁盤IO操作(如果根節點存儲在記憶體中,其他結點存儲在磁盤中),
如果對16個資料建構五叉樹索引,那樹的高度隻有2,查找一個資料,對應隻需要2次磁盤操作。如下圖所示
如果m叉樹中的m是100,那對一億個資料建構索引,樹的高度也隻是3,最多隻要3次磁盤IO就能擷取到資料。磁盤IO變少了,查找資料的效率也就提高了。
但是m值也不是越大越好,因為不管是記憶體中的資料,還是磁盤中的資料,作業系統都是按頁(一頁大小通常是4KB,這個值可以通過getconfig PAGE_SIZE指令檢視)來讀取的,一次隻會讀一頁的資料。如果要讀取的資料量超過一頁的大小,就會觸發多次IO操作。是以,我們在選擇m大小的時候,要盡量讓每個節點的大小等于一個頁的大小。讀取一個節點,隻需要一次磁盤IO操作。
那麼什麼叫做一個節點的大小呢,比如下面的資料,下面的籃筐的這個節點,它裡面存儲的資料,就是可以存儲所有子節點裡面的資料,但是不包含本節點的資料,本節點的資料在本節點的父節點裡面存儲着。什麼意思呢,看下面的圖檔,下面的藍框裡面的30,65其實是在下面的藍框的父節點紅框節點裡面存儲着,然後下面的綠色框裡面的30,65其實是在父節點藍框節點裡面存儲着,同時藍框節點還存儲着下面的綠色框裡面的所有位元組點資料,是以隻要保證紅框節點,藍框節點等節點的資料大小不超過4kb就可以了,那麼如果超過了怎麼辦呢,超過4kb大小的節點都會被mysql處理掉,這裡就要去看bmore樹的添加和删除了
能看到這裡的同學,就幫忙點個贊吧,Thanks(・ω・)ノ